2024 June
Substack
Salesforce: Worst Day in 20 Years - App Economy Insights [Link]
PayPal hired Mark Grether who was head of Uber’s ad business to lead the initiative of an ad network.
Costco’s membership fees declined from 86% to 50% of the its operating profit. It has shown economies of scale and benefits from a more favorable revenue mix.
Salesforce’s revenue grew 11% to $9.1B, missing Wall Street estimates by $20M. Current Remaining Performance Obligations - the best indicator of future growth - rose 10%, missing estimates of 12%. The slowing growth is partially due to broader macroeconomic challenges and internal execution issues. Salesforce Data Cloud is contributing to 25% of the deals valued above $1M, indicating it’s well-positioned to benefit from AI boom.
Live Nation has caused such widespread outrage in 2022 Taylor Swift Eras Tour ticket sales because fans faced technical glitches and exorbitant fees. Live Nation was accused of locking venues into exclusive deals and bullying artists into using its services, which caused higher ticket prices through service and convenience fees. Live Nation is under scrutiny by the government. It is forced to divest Ticketmaster (acquired in 2020). Fans / artists are expecting increased competition in live music industry and lower prices, and a smoother ticket buying experience.
Online Travel: AI is Coming - App Economy Insights [Link]
AI agents as the next frontier could make traveling personalized. The key metrics to define their success are 1) gross bookings, 2) nights booked, 3) average daily rate (ADR), 4) revenue per available room (RevPAR), customer acquisition cost (CAC).
The largest travel companies (online travel agencies and rentals and hotel chains) are Booking Holdings, Airbnb, Expedia, Marriott, and Hilton.
Highlights: 1) Booking Holdings (operating as an OTA): CEO Glenn Fogel envisions AI enhancing connected trips (single booking that include multiple travel elements such as flights, accommodations, car rentals, etc), 2) Airbnb exceeded expectations on both revenue and profitability in Q1 due to its robust international expansion, while slowing down the growth in North America. Airbnb is aiming to create an AI powered concierge to elevate the overall Airbnb experiences, 3) Expedia (operating as an OTA): Expedia is currently facing challenges of transition and adjustment: Vrbo vacation rental platform integration into Expedia platform is slower than expected. And it’s also facing challenges in attracting and retaining customers in its B2C segment. A new CEO Ariane Gorin was recently appointed to help navigate through these challenges. 4) Marriott (operating as booking platform): Marriott has developed Homes & Villas tool that allows users to search for vacation rentals using language. A slow-down RevPAR in North America has been observed which indicates a shift in consumer preferences towards international destinations and alternative accommodations. Its brand reputation, loyalty program and focus on group/business travel remain strong. 5) Hilton: has strong emphasis on personalization and loyalty programs though facing headwinds in the US. CEO Chris Nassetta envisions AI-powered tools to address guest concerns in real time.
From graphics rendering, gaming and media, cloud computing and crypto, Nvidia’s chips have led the way in each of these past innovation cycles as it saw its GPU applications expand over the last 2 decades. And now it is getting ready to advance the next industrial revolution, that will be powered by AI.
Some industry experts believe that 20% of the demand for AI chips next year will be due to model inference needs, with “Nvidia deriving about 40% of its data center revenue just from inference.”
― NVIDIA’s chips are the tastiest AI can find. It’s stock still has ways to go - The Pragmatic Optimist [Link]
This is a good summary of Nvidia’s strategies towards computing, path to AI domination, tailwinds of efficiency, position in the future.
Nvidia is “at the right place at the right time”:
- During 2000-2010 where the world successfully emerged from the dot-com bust, demand of Nvidia’s GPUs increased as the proliferation of games and multimedia applications. By 2011, Nvidia had already begun to reposition the company’s strategy for GPU chips towards mobile computing. At the same time, the concept of cloud computing, crypto-mining, and data center started to form.
- Nvidia has built grounded relationship with academics and researchers. According to the paper published by Andrew Ng to show the power of NVIDIA GPU. During 2011-2015, Ng had been working as the Chief Scientist at many big tech firms and deployed data center architectures based on Nvidia’s GPUs. During 2010-2014, data center and HPC grew at a compounded growth rate of 64%. This period of time was one of the moments that set Nvidia on the course to dominate AI.
In semiconductor industry, there are two different ways of manufacturing chips at scale:
- Designing and manufacturing your own chip - what Intel was doing. Manufacturing chips can be very expensive and hard. Today, chip foundries such as Taiwan’s TSMC and South Korea’s Samsung are able to maintain leading edge.
- Designing and producing powerful chips at a quicker pace by partnering with chip foundries like TSMC - what Nvidia and AMD fabless companies are doing.
2024 could be the first year that Huang’s Nvidia could cede some market share to AMD. AMD launched their own MI300-series and Intel launched their Gaudi3 AI Accelerator chip, aiming to get back share from Nvidia’s H100/H200 chips. However Huang looks ahead:
Huang believes Nvidia must turn its attention to the next leg of AI - Model Inference.
Tech companies spend more on AI data center equipment over years, Nvidia’s revenue won’t slow down.
Nvidia’s executives also believe that company can benefit from demand from specific industry verticals, such as automotive.s
Tesla, for example, is leading self driving cars.
Automotive AI and Sovereign AI are two future areas of growth where enterprises continue to spend on data centers for model training and inferencing.
The authors also assessed Nvidia’s valuation and believe that:
- Between 2023 and 2026, Nvidia’s sales should be growing at a compounded annual growth rate of 43–45%.
- Over the next 3 years, they expect operating profit to grow in line with revenue growth, with operating profit margins remaining relatively flat in 2025 and 2026.
The Coming Wave of AI, and How Nvidia Dominates - Fabricated Knowledge [Link]
Nvidia is the clear leader in 1) System and Networking, 2) Hardware (GPUs and Accelerators), and 3) Software (Kernels and Libraries) but offers the whole solution as a product.
Amazon drives tremendous savings from custom silicon which are hard for competitors to replicate, especially in the standard CPU compute and storage applications. Custom silicon drives 3 core benefits for cloud providers.
- Engineering the silicon for your unique workloads for higher performance through architectural innovation.
- Strategic control and lock-in over certain workloads.
- Cost savings from removing margin stacking of fabless design firms.
The removal of these workloads from server CPU cores to the custom Nitro chip not only greatly improves cost, but also improves performance due to removing noisy neighbor problems associated with the hypervisor, such as shared caches, IO bandwidth, and power/heat budgets.
― Amazon’s Cloud Crisis: How AWS Will Lose The Future Of Computing - Semianalysis [Link]
A good overview of Amazon’s in-house semiconductor designs (Nitro, Graviton, SSDs, Inferentia, and Trainium). It includes how Microsoft Azure, Google Cloud, Nvidia Cloud, Oracle Cloud, IBM Cloud, Equinix Fabric, Coreweave, Cloudflare, and Lambda are each fighting Amazon’s dominance across multiple vectors and to various degrees.
Amazon’s custom silicon efforts - Nitro:
- AWS worked with Cavium on developing the custom SoC on a discrete PCIe card and associated software, named “Nitro System”. It removes workloads from server CPU cores to the custom Nitro chips.
- Annapurna Labs was acquired by Amazon in 2015. It focuses on server SOCs for networking and storage. Amazon was trying to continue its efforts on storage, and Nitro is the main enabler of a competitive advantage in these storage and databases.
- Nitro provides services such as virtual disk to the tenant’s virtual machines and enables customers to dynamically grow and shrink high performance storage at low cost.
- Amazon worked with Marvell to co-design the AWS Nitro SSD controller. The focus was on avoiding latency spikes and latency variability, and maximizing the lifetime of the SSD.
Other two clouds (Google and Microsoft) are years behind Amazon, both required a partner, and both were stuck with 1st or 2nd generation merchant silicon for the next few years.
James Hamilton, an engineer in Amazon, had and look at two key ways in which using AWS-designed, Arm-based CPUs could offer advantages compared to their external counterparts.
- Using Arm’s scale in mobile by using the arm-designed Neoverse cores or
- TSMC’s manufacturing scale. Both would reduce costs and offer better value to customers.
In-house CPUs enables Amazon to design CPUs to maximize density and minimize server and system level energy which helps reduce costs. The tremendous scale of Amazon especially regarding general-purpose compute and storage-related verticals will continue to drive a durable advantage in the cloud for many years.
Ultrafusion is Apple’s marketing name for using a local silicon interconnect (bridge die) to connect the two M2 Max chips in a package. The two chips are exposed as a single chip to many layers of software. M2 Ultra utilizes TSMC’s InFO-LSI packaging technology. This is a similar concept as TSMC’s CoWoS-L that is being adopted by Nvidia’s Blackwell and future accelerators down the road to make large chips. The only major difference between Apple and Nvidia’s approaches are that InFO is chip-first vs CoWoS-L is chip-last process flow, and that they are using different types of memory.
― Apple’s AI Strategy: Apple Datacenters, On-device, Cloud, And More - Semianalysis [Link]
Apple’s purchases of GPUs are minuscule and Apple is not a top 10 customer of Nvidia. The production of M2 Ultras can be consistent with the fact that Apple is using their own silicon in their own data centers for serving AI to Apple users. And Apple has expansion plans for their own data center infrastructure. Furthermore, Apple made a number of hires including Sumit Gupta who joined to lead cloud infrastructure at Apple in March.
One of the best known non-bank banks is Starbucks – “a bank dressed up as a coffee shop”. Trung Phan, rates the misperception up there alongside “McDonald’s is a real estate company dressed up as a hamburger chain” and “Harvard is a hedge fund dressed up as an institution of higher learning”.
Today, more than 60% of the company’s peak morning business in the US comes from Starbucks Rewards members who overwhelmingly order via the app. The program has 33 million users, equivalent to around one in ten American adults.
― Banks in Disguise - Net Interest [Link]
Starbucks had offered a gift card since 2001 and started to pair it with a new loyalty program “Starbucks Rewards” in 2008. Consumers are allowed to access free wifi and refillable coffee by paying with a reloadable card. The card was put onto an app in 2010 and expanded to over 9000 locations. It quickly became the largest combined mobile payments in loyalty program in the US. Uses load or reload around $10 B of value onto their cards each year and so about $1.9B of stored card value sat on the company’s balance sheet, just like customer deposits. There are several advantages: 1) the company does not pay interest on customer funds, and 2) sweep customer funds into company’s own bank account when it concludes customers may have forgotten about them - this is called ‘breakage’. In late 2023, Starbucks was accused of making it impossible for consumers to spend down their stored value cards by only allowing funds to be added in $5 increments and requiring a $10 minimum spend. Although the company has to pay rewards to customers, it saves on merchant discount fees and receives a lots of free and valuable personal information about customers.
Delta’s SkyMiles scheme is one of the largest globally with 25 M active members. There are two ways points schemes generate money: 1) when scheme member buy a regular ticket, they also buy mileage credit they can redeem in the future, and 2) they make money from card companies (such as American Express) and other partners.
VC Says “Chaos” Coming for Startups, Ads, and Online Business as Generative AI Eats Web - Big Technology [Link]
The main point is that, as generative AI is ingested into the web, a decades-old system of online referrals and business building will be reshaped. The business model of every existing business (online travel, ecommerce, online advertising, etc) on the internet are impacted due to the transformation of online search by AI. It decreases the number of customer’s impressions on the internet thus reduce advertiser’s chance of being charged. And it also reduces the chance for startups to be observed and build brands.
OpenAI: $80 Billion - Trendline [Link]
So top 10 most valuable unicorns are 1) ByteDance, 2) SpaceX, 3) OpenAI, 4) SHEIN, 5) Stripe, 6) Databricks, 7) Revolut, 8) Fanatics, 9) Canva, 10) Epic Games
Nvidia’s four largest customers each have architectures in progress or production in different stages:
- Google Tensor
- Amazon Inferentium and Trainium
- Microsoft Maia
- Meta MTIA
― What’s all the noise in the AI basement? - AI Supremacy [Link]
Current situation of players in semiconductor industry in the context of AI competition.
Big 4 Visualized - App Economy Insights [Link]
The four titans of accounting industry - Deloitte, PwC, EY, and KPMG. They make money from 1) audit: verifying financial statement, 2) assurance: including processes, internal control, cybersecurity assessments, and fraud investigations, 3) consulting: offering advice on everything from M&A to digital transformation, especially in helping enterprise software sales, 4) risk adn tax advisory: navigating compliance, regulations, and tax laws.
Insights:
Deloitte: 1) fastest growing in revenue, 2) heavily investing in AI and digital transformation, 3) acquisition as a growth strategy.
PwC: 1) heavily investing $1B in Gen AI initiative with Microsoft, 2) will become the largest customer and 1st reseller of OpenAI’s enterprise product, 3) leader of financial services sector, serving most global banks and insurers, 4) has faced scrutiny over its audit of the failed cryptocurrency exchange FTX, raising concerns about its risk management practices.
EY: 1) invested $1.4B to create EY.ai EYQ, an AI platform and LLM, 2) abandoned its “Project Everest” plan to split it audit and consulting businesses in 2023, 3) growing business through strategic acquisitions, 4) has faced criticism for an about $2B hole in its accounts, raising concerns about its audit practices and risk management, 5) was fined $100M because hundreds of employees cheated on ethics exams.
KPMG: 1) focusing on digital transformation (data analytics, AI, and cybersecurity), 2) has faced regulatory scrutiny and fines due to audit practices, raising concerns about its audit quality and independence.
I think the release highlights something important happening in Al right now: experimentation with four kinds of models - Al models, models of use, business models, and mental models of the future. What is worth paying attention to is how all the Al giants are trying many different approaches to see what works.
This demonstrates a pattern: the most advanced generalist Al models often outperform specialized models, even in the specific domains those specialized models were designed for.
That means that if you want a model that can do a lot - reason over massive amounts of text, help you generate ideas, write in a non-robotic way - you want to use one of the three frontier models: GPT-40, Gemini 1.5, or Claude 3 Opus.
The potential gains to AI, the productivity boosts and innovation, along with the weird risks, come from the larger, less constrained models. And the benefits come from figuring out how to apply AI to your own use cases, even though that takes work. Frontier models thus have a very different approach to use cases than more constrained models. Take a look at this demo, from OpenAI, where GPT-4o (rather flirtatiously?) helps someone work through an interview, and compare it to this demo of Apple’s AI-powered Siri, helping with appointments. Radically different philosophies at work.
― What Apple’s AI Tells Us: Experimental Models⁴ - One Useful Thing [Link]
Al Models: Apple does not have frontier model like Google and Microsoft do, but they have created a bunch of small models that are able to run on Al-focused chips in their products. The medium-sized model that can be called by iPhone in the cloud. The model that’s running on iPhone and the model that’s running in the cloud are as good as Mistral’s and ChatGPT.
Models of Use: However, larger, less constrained models are the potential gains to Al, the productivity boosts and innovation. You would prefer to use GPT-4o to do nuanced tasks such as helping with your interviews rather than use Apple Al-powered Siri.
Business Models: Apple sounds like they will start with free service as well, but may decide to charge in the future. The truth is that everyone is exploring this space, and how they make money and cover costs is still unclear (though there is a lot of money out there. People don’t trust Al companies because they are concerning about privacy. However Apple makes sure models cannot learn about your data even if it wanted to. Personal data on your iPhone are only accessed by local Al.
And those handed to the cloud is encrypted. For those data given to OpenAl, it’s anonymous and requires explicit permission. Apple is making very ethical use of Al. Though we should still be cautious about Apple’s training data.
Models of the Future: Apple and OpenAl have different goals. Apple is building narrow Al systems that can accurately answer questions about your personal data. While OpenAl is building autonomous agents that would complete complex tasks for you. In comparison, Apple has a clear and practical vision of how Al can be applied, while the future OpenAl’s AGI remains to be seen.
Elon has been spreading significant FUD by threatening to prohibit Apple devices at his companies. The truth is Apple at no point will be sending any of your data to OpenAI without explicit user permission. Even if you opt for “Use ChatGPT” for longer questions, OpenAI isn’t allowed to store your data.
According to Counterpoint Research, smartphone makers who have launched AI features on their smartphones have seen a revival in sales. Look at Samsung for example, where its S24 series grew 8% compared to S23 in 2024 with sales for its mid-range premium model growing 52% YoY. With Apple having a larger market share, along with receding expectations for an economic recession, this could be the start of a new growth chapter for the Cupertino darling once again.
Pete Huang at The Neuron explains in a step by step process of what really goes down when you ask Siri with AI a question.
For almost all questions, Siri uses AI that lives on the device, aka it won’t need to hit up the cloud or ChatGPT, aka your question won’t ever leave the phone.
- These on-device models are decent (they’re built on top of open-source models) and outperform Google’s on-device model, Gemma-7B, 70% of the time.
For more complex questions like “Find the photo I took at the beach last summer,” Siri will consult a smarter AI model that runs on Apple’s servers.
- When Siri sends your question to Apple’s servers, your data is anonymized and not stored there forever.
Now, for longer questions like “Can you help me create a weekly meal plan?” or “Rewrite this email using a more casual tone,” Siri will use ChatGPT only if you give it permission to.
- Even if you opt for “Use ChatGPT,” OpenAI isn’t allowed to store your data.
― The Real Test For Consumer’s AI Appetite Is About To Begin - The Pragmatic Optimist [Link]
Interested to know how it actually works when you ask Siri with AI a question.
5 Founder-Led Businesses - Invest in Quality [Link]
Three research findings:
- Founder-led businesses outpaced other companies by a wide margin. (Researched by Ruediger Fahlenbrach in 2009).
- Family-owned businesses ignored short-term quarterly numbers to focus on the long-term value creation, which lead to a major outperformance because of 1) lower risk-taking in the short term, and 2) greater vision and investment for the long term. (Researched by Henry McVey in 2005).
- Businesses managed by billionaires outperformed the market by 7% annually from 1996 to 2011. (researched by Joel Shulman in 2012).
Insights behind the findings above:
- Founders and owners often have their life savings invested in the shares of the business, so they have the incentive aligned.
- Bureaucracy reduces business performance. They will almost never make a radical shift, because politicians care more about their job title than the long term prospects of the business. Founders on the other hand are able to make radical decisions and overrule the bureaucracy, therefore they can take the business in a direction to fulfill long term vision.
- Founders and billionaires are exceptional people to run business.
The article listed five examples of founder-led businesses: MercadoLibre, Adyen, Fortinet, Intercontinental Exchange, and Paycom.
This move positions Apple as an AI aggregator, offering users a curated selection of the best AI tools while keeping their data private. It’s a win-win. Apple gets to enhance its user experience with powerful AI capabilities. At the same time, OpenAI gains access to Apple’s massive user base for brand recognition and potential upsell to ChatGPT Plus. There is no detail available on the exact terms of the partnership.
― Apple: AI for the Rest of Us - App Economy Insights [Link]
Integrating ChatGPT alongside Apple Intelligence features is a smart move that allows Apple to focus on their strengths (privacy, personalization) while leveraging general knowledge AI from OpenAI. This will enable Apple to blame any wrong answers and hallucinations on the LLMs the company partners with and stay out of PR trouble.
The Other Side of the Trade - The Rational Walk [Link]
An ethical implication about taking advantage of a glitch caused by software malfunction.
AI may take longer to monetize than most expect. How long will investor optimism last? - The Pragmatic Optimist [Link]
The Dark Stain on Tesla’s Directors - Lawrence Fossi [Link]
2,596 - How to make the mokst out of Google’s leaked ranking factors [Link]
Ramp and the AI Opportunity [Link]
How Perplexity builds product [Link]
IBM’s Evolution of Qiskit [Link]
Articles and Blogs
Today, foundries manufacture supermajority of the chips produced in the world, and Taiwan Semiconductor Manufacturing Company (TSMC) alone has ~60% market share in the global foundry market.
Perhaps more astonishingly, TSMC has a de-facto monopoly with ~90% market share in the leading edge nodes (manufacturing processes with the smallest transistor sizes and highest densities). Leading edge nodes are crucial for applications requiring the highest computing performance like supercomputers, advanced servers, high-end PCs/laptops, smartphones, AI/machine learning, and military/defense systems. As a result, the very basic tenet of modern life is essentially standing on the shoulders of one company based in Taiwan.
― TSMC: The Most Mission-Critical Company on Earth [Link]
This is a deep dive report of Taiwan Semiconductor Manufacturing Company (TSMC).
In terms of next steps, Google has “limited the inclusion of satire and humor content” as part of “better detection mechanisms for nonsensical queries.” Additionally:
- “We updated our systems to limit the use of user-generated content in responses that could offer misleading advice.”
- “We added triggering restrictions for queries where AI Overviews were not proving to be as helpful.”
- “For topics like news and health, we already have strong guardrails in place. For example, we aim to not show AI Overviews for hard news topics, where freshness and factuality are important. In the case of health, we launched additional triggering refinements to enhance our quality protections.”
― Google explains AI Overviews’ viral mistakes and updates, defends accuracy [Link]
The AI Revolution Is Already Losing Steam [Link]
It remains questions whether AI could become commoditized, whether it has potential to produce revenue and profits, and whether a new economy is actually being born.
According to Anshu Sharma, the future of AI startups (OpenAI and Anthropic) could be dim, and big tech companies (Microsoft and Google) will make profits from existing users and networks but need to spend a lot of money for a long time, which would leave the AI startups unable to compete. This is true that AI startups are already struggling right now, because at current stage AI is hard to commoditized, and it requires a lot of investments.
The improvement of AI is slowing down because they exhausted all available data on the internet. Regarding the adoption of AI in enterprise, time is required to make sure that chatbots can replace the specialized knowledge of human experts due to technical challenges.
One thing we’ve learned: the business goal must be paramount. In our work with clients, we ask them to identify their most promising business opportunities and strategies and then work backward to potential gen AI applications. Leaders must avoid the trap of pursuing tech for tech’s sake. The greatest rewards also will go to those who are not afraid to think big. As we’ve observed, the leading companies are the ones that are focusing on reimagining entire workflows with gen AI and analytical AI rather than simply seeking to embed these tools into their current ways of working. For that to be effective, leaders must be ready to manage change at every step along the way. And they should expect that change to be constant: enterprises will need to design a gen AI stack that is robust, cost-efficient, and scalable for years to come. They’ll also need to draw on leaders from throughout the organization. Realizing profit-and-loss impact from gen AI requires close partnership with HR, finance, legal, and risk to constantly readjust the resourcing strategies and productivity expectations. - Alex Singla
Although it varies by industry, roughly half of our survey respondents say they are using readily available, off-the-shelf gen AI models rather than custom-designed solutions. This is a very natural tendency in the early days of a new technology—but it’s not a sound approach as gen AI becomes more widely adopted. If you have it, your competitor probably has it as well. Organizations need to ask themselves: What is our moat? The answer, in many cases, likely will be customization. - Alexander Sukharevsky
― The state of AI in early 2024: Gen AI adoption spikes and starts to generate value - McKinsey [Link]
Industries are struggling with budgeting for Gen AI. There are some areas where investments are paying off, such as meaningful cost reductions in HR and revenue increases in supply chain management from Gen AI.
There are varies risks of Gen AI usage: data privacy, bias, intellectual property (IP) infringement, model management risks, security and incorrect use, etc. Among all, inaccuracy and intellectual property infringement ar eincreasingly considered relevant risks to organizations’ Gen AI use.
According to the three archetypes for implementing Gen AI solutions (takers, shapers, and makers), survey has found that in most industries, organizations are finding off-the-shelf offerings applicable to their business needs, about half of reported Gen AI uses publicly available models or tools with little or no customization. Respondents in energy and materials, technology, and media and telecommunications are more likely to report significant customization or tuning of publicly available models or developing their own proprietary models to address specific business needs.
The time required to put Gen AI to production for most of the respondents is around 1-4 months.
Gen AI high performers are excelling. Some common characteristics or practices: 1) They are using Gen AI in more business functions (an average of 3) compared to others average 2, 2) They are more likely to use Gen AI in marketing and sales and product or service development like others, but they are more likely than other s to use Gen AI solutions in risk, legal, and compliance; in strategy and corporate finance; and in supply chain and inventory management, 3) They are three times as likely as others to be using Gen AI in activities ranging from processing of accounting doc and risk assessment to R&D testing and pricing and promotions, 4) They are less likely to use those off-the-shelf options than to either implement significantly customized version to develop their own proprietary foundation models, 5) encountered challenges with their operating model.
Asian Americans are crucial in today’s knowledge economy: around 60% hold at least a bachelor’s degree and, despite representing only about 7% of the U.S. population, account for 50% of the workforce in leading Silicon Valley tech companies.
A detailed analysis of top Fortune 500 technology companies shows that Asian professionals are even less likely to progress in their careers today than they were a decade ago.
― Stop Overlooking the Leadership Potential of Asian Employees - Harvard Business Review [Link]
This article talked about the reasons why Asian employees’ careers stagnate, solutions for the organization to help employees move past the roadblock, and reasons of investment in Asian employees.
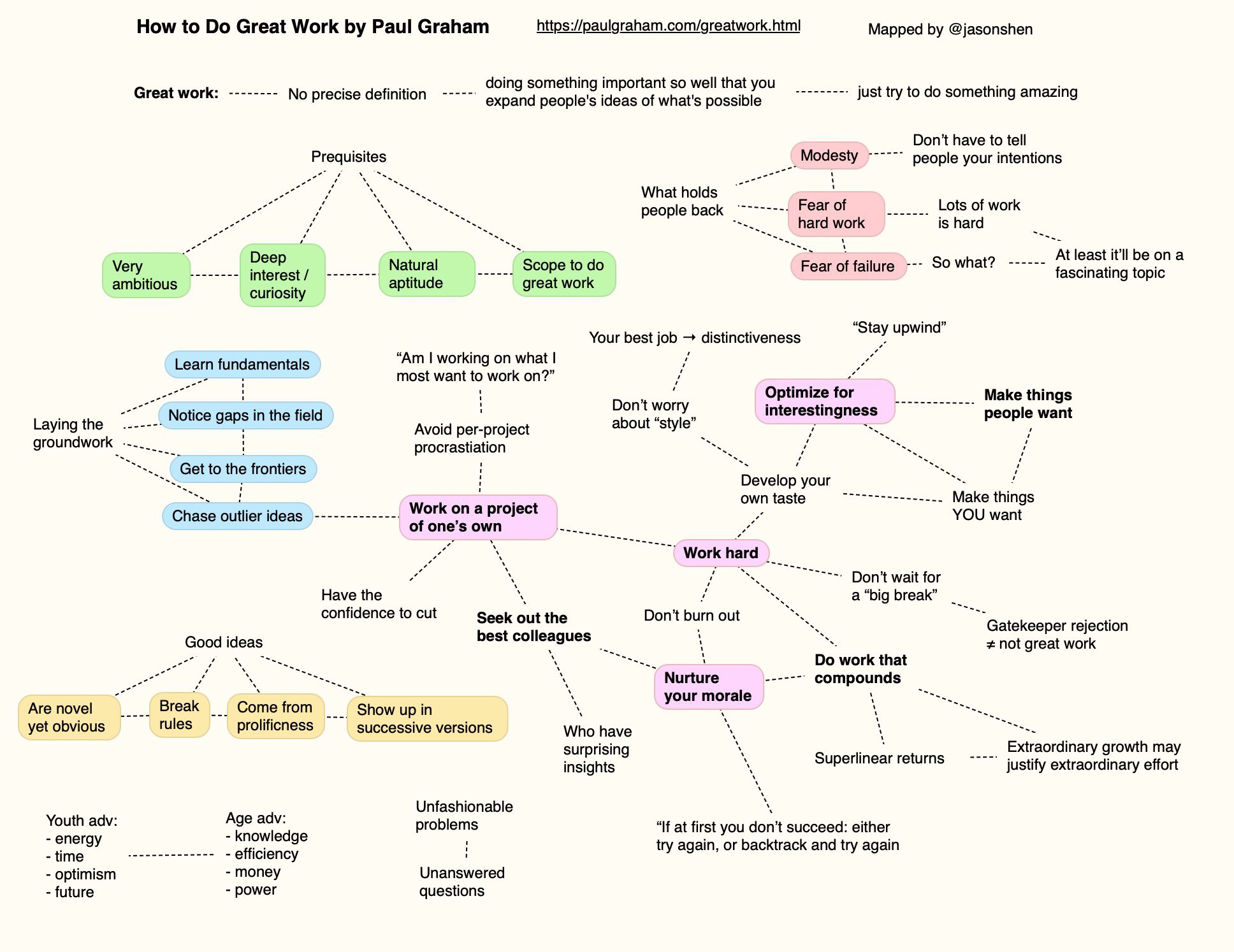
How to do great work [Link]
A good summary of this great article:
Introducing Apple’s On-Device and Server Foundation Models [Link]
This article provides details about how Apple developers trained models, fine-tuned adapters for specific user needs, and evaluated model performance.
How to Fund Growth (& when not to) [Link]
So You Want To Build A Browser Engine [Link]
Introducing the Property Graph Index: A Powerful New Way to Build Knowledge Graphs with LLMs [Link]
What matters most? Eight CEO priorities for 2024 - McKinsey [Link]
Gen AI’s second wave - McKinsey [Link]
Extracting Concepts from GPT-4 [Link]
OpenAI presents new approach to interpret concepts captured by GPT-4’s neural networks.
YouTube and Podcasts
In an H100 GPU, every second we can move at most 3.35 terabytes of RAM in and out of memory registers. And in the same second, we can multiply 1.98 quadrillion 8bit floating point numbers. This means that it can do 591 floating point operations in the time it takes to move one byte. In the industry this is known as a 591:1 ops:byte ratio. In other words, if you are going to spend time moving an entire gigabyte around you should do at least 591 billion floating point operations. If you don’t, you are just wasting GPU and potential compute. But if you do more than that, you are just waiting around on memory bandwidth to get your data in there. In our models, the amount of memory we need to move around is relatively fixed, it’s roughly the size of our model. This means that we do have some control over on how much math that we can do by changing our batch size.
In reality, we’ve discovered that bottleneck can arise from everywhere from memory bandwidth, network bandwidth between GPUs, between nodes, and other areas. Furthermore the location of those bottlenecks will change dramatically on the model size, architecture, and usage patterns.
― Behind the scenes scaling ChatGPT - Evan Morikawa at LeadDev West Coast 2023 [Link]
This is a behind the scenes look at how OpenAI scaled ChatGPT and the OpenAI APIs. But also a very good talk to show how hard it is to scale infrastructure for model architecture etc, and how important it is to master these skills and knowledge in chip manufacture and design industry and in LLM development industry. The talk covers 1) GPU RAM and KV Cache, 2) batch size and ops:bytes, 3) scheduling in dozens of clusters, 4) autoscaling (and the lack thereof).
Key facts to consider when developing metrics for compute optimization and model scaling:
- GPU memory is valuable. But it is frequently a bottleneck, not necessarily compute.
- Cache misses are non linear on compute, because we suddenly need to start recomputing all stuff.
When scaling ChatGPT, we need to:
- Look at KV cache utilization and maximize all the GPU RAM we have, and
- Monitor batch size - the number of concurrent requests we run to the GPU at the same time, to ensure the GPUs are fully saturated. These are two main metrics used to determine how loaded our servers were.
In reality, there are more bottlenecks (memory bandwidth, network bandwidth between GPUs, between nodes, and other areas) and the location where they arise can change according to the model size, architecture, and usage patterns. The variability has made it very hard for AI model developer and chip manufactures to design chips to get that balance right. Future ML architectures and sizes have been very difficult to predict. But overall we need to be tweaking this math as the models evolve.
The third challenge is to find enough GPUs. Note that the time of a response is dominated by the GPU streaming out one token at a time, as a result, it’s been more important to just get capacity and optimized a well balanced fleet, over putting things geographically close to users.
The fourth challenge is the inability to scale up this fleet. OpenAI has delayed some feature of ChatGPT due to the limitation of compute resources.
Some lessons they have learned in solving GPU challenges:
- It’s important to treat this as a system engineering challenge as opposed to a pure research project.
- It’s important to adaptively factor in the novel constraints of these systems.
- Every time model architecture shifts, a new inference idea is proposed or a product decision is changed, we need to adapt and rerun a lot of this math again. Diving really deep has been important. This low level of implementation details matter.
The final challenge is abuse on the system and AI safety challenges.
For many years, particularly following the original SARS pandemic, there was a lot of conversations around how do we get in front of the next pandemic, how do we figure out what’s coming and how do we prepare for it. And there was a lot of research that was launched to try and resolve that key question. It’s like does the effort to try and stop the problem cause the problem. I think that from my point of view there is a very high probability that there was some leak that meant that the work that was going on to try and get in front of the next pandemic and understand what we could do to prepare ourselves, and what vaccines could be developed and so on, actually led to the pandemic. So then when that happens how do you respond when you are sitting in that seat, that’s the key question that I think this committee is uncovering. - David Friedberg
― Trump verdict, COVID Cover-up, Crypto Corner, Salesforce drops 20%, AI correction? - All-in Podcast [Link]
The TED AI Show: What really went down at OpenAI and the future of regulation w/ Helen Toner [Link]
In the interview, Toner revealed that the reason of firing Altman is his psychological abuse and being manipulative in different situation. Looking at Altman’s track record prior to OpenAI, it seems those are not new problems of Sam.
How Walt Mossberg Built Relationships With Jobs, Gates, and Bezos - Big Technology Podcast [Link]
Nvidia’s 2024 Computex Keynote: Everything Revealed in 15 Minutes [Link]
What really works when it comes to digital and AI transformations? - McKinsey [Link]
… but what I do take offense at is labeling millions and millions of ordinary Americans as somehow lacking in empathy, lacking in caring, not being a good parents, because you don’t like their support for Trump. And I think that that is a statement that frankly reeks of being cocooned in an elite bubble for way too long. Let me just explain. If you look at where Trump’s support is strongest. It’s really in Middle America and sort of the heartland of America, basically the part of America that the Coastal at least dismissively refer to as flyover country. It’s a lot of the industrial midwest and frankly that part of the country had not had the same type of economic experience that we’ve had in Silicon Valley. They have not been beneficiaries of globalization. If you are in a handful of export industries in America and I’m talking about if you are in Hollywood or you are in Big Finance or you are in Software, then globalization has been great for you, because it has created huge global markets for our products. However, if you are in an industry that has to compete with global exports, then it’s been very bad with you and blue collar workers have been hurt, labor’s been hurt, people who work with their hands have been hurt. They have not benefitted in the same way from the system we’ve had in this country for the last 30 years. So you can understand why they would not be so enchanted with elite thinking. I think to then label those people as lacking in caring or empathy or not being good parents because they haven’t had the same economic ride that you had for the last 30 years and then you are the one who is fighting a legal battle to kick some of those people off the public beach in front of your beach house, and then you are saying they are the ones lacking in empathy, dude, look in the mirror. - David Sacks
This is the future of how smart reasonable moderate people should make decisions. It is an example. Talking to somebody you disagree with does not make your opinion bastardized, it actually makes your opinion valuable. There are these simple truths to living a productive live that if you want to embrace, you need to find friends that you can trust, even on issues when you disagree, you can hear them out. - Chamath Palihapitiya
There is no law that defines why you should or shouldn’t buy a security, with respect to the diligence you have individually done, to determine whether the underlying business is worth the price you are paying. The law says, that the business that are listing their securities for public trading have an obligation to make disclosures on their financials and any other material events to the public and they do that through the SEC filing process. That’s all out there. And then what you as an individual will do with it is up you to. - David Friedberg.
― DOJ targets Nvidia, Meme stock comeback, Trump fundraiser in SF, Apple/OpenAI, Texas stock market - All-in Podcast [Link]
Deloitte’s Pixel: A Case Study on How to Innovate from Within - HBR On Leadership Podcast [Link]
WWDC 2024 — June 10 | Apple [Link] [Short Version]
Apple’s promising updates on visionOS, iOS, Audio&Home, watchOS, iPadOS, and macOS.
Let’s reproduce GPT-2 (124M) [Link]
This four hours video guides you to create a fully functional GPT-2 model from scratch. It includes details about model construction, speed optimization, hyperparameter setup, model evaluation, and training.
Building open source LLM agents with Llama 3 [Link]
LangChain and Meta uploads new recipes/tutorials to build agents that runs locally using LangGraph and Llama 3.
Apple took a shortcut to get here, they partnered with open ai. And this is something that I don’t think they’ve ever really done before at the operating system level. Apple is famous for being vertically integrated, for being a walled garden, for being end to end. They control everything from the chips to the hardware to the operating system, and they don’t let anybody else in, until you are at the App Store Layer. This is allowing somebody in beneath the level of the App Store. This is allowing someone OpenAI to get access to your data, and to control your apps, at the operating system level. Elon pointed out wait a sec what are the privacy implications here. And I think there are major privacy implications. There is simply no way that you are going to allow an AI on your phone to take. Remember Apple in the past has been the advocate for consumer privacy. There is a whole issue of the San Bernardino terrorist where the FBI went to Apple and said we want you to give us back door access to their phone and Apple refused to do it and went to court to defend user privacy. And furthermore, one of Apple’s defenses to the antitrust arguments for allowing sideloading and allowing other apps to get access to parts of the operating system, they’ve always said we can’t do this because it would jeopardize user privacy and user security. Well here they are opening themselves up to OpenAI in a very deep and fundamental way in order to accelerate the development of these features… I think this is going to open Pandora’s box for Apple, because again they’ve proven that they can open up the operating system to a third party now, and who knows what the privacy implications of this are going to be. - David Sacks
I think there are three numbers that matter: the inflation rate, the growth in GDP, and the cost to borrow. The growth in GDP in the first quarter of 2024 was a lousy - 1.3% on the annualized basis. And even if the rate of inflation came down, we are still inflating the cost of everything by north of 3%. So the economy is only growing by 1.3% and it costs more than 3% each year to buy stuff. So that means everyone’s spending power is reducing, and our government’s ability to tax is declining, because the economy is only growing by 1.3%. And the most important fact is that the interest rates are still between 4-5% (4.7%). That means that borrowing money costs 4.7%, but the business the economy on average is only growing 1.3%. So just think about that for a second. We have tremendous amount of leverage on businesses on economy on the federal government. That leverage, the cost to pay for that debt is more than 4-5% but you are only growing your revenue by 1.3%. So at some point you cannot make your payments. That is true for consumers, it’s true for enterprises, and it’s true for federal government. The whole purpose of raising rates is to slow the flow of money through the economy. And by slowing the flow of money through the economy, there is less spending which means that you are reducing the demand relative to the supplies, so the cost of things should come down, you should reduce the rate of increasing in the cost of things… There is certainly a shift in the market because what this tells us is that the timeline at which the fed will cut rates is coming is a little bit. So the market is saying okay let’s adjust to lower rates, the 10 year treasury yield has come down a little bit, but we are still in a difficult situation for people, and for businesses. - David Friedberg
If the revenue of everything combined which is GDP isn’t going faster than the increase in the cost of everything, people, businesses, and government can’t afford their stuff. And that’f fundamentally what is going on right now. What we need to see is a normalization where GDP growth is greater than inflation rate. And as soon as that happens then we have a more normalized and stable economy. So right now things are not stable. There is a lot of difficulty and strain in the system. - David Friedberg
You had 1.3% GDP growth rate with a 6% of GDP deficit by the government. If the government wasn’t printing so much money, wasn’t over spending, and you were to have a balanced budget, it would be a recession. It would be negative GDP growth if not for the government’s program stimulating the economy. And a lot of jobs you are talking about are government jobs. The government is creating jobs like crazy, not in the private sector but in the public sector, because it is an election year. So there is a lot of political forces proping things up, and I wonder what happens after the election. - David Sacks
― Elon gets paid, Apple’s AI pop, OpenAI revenue rip, Macro debate & Inside Trump Fundraiser - All-in Podcast [Link]
Energy is high at the beginning with a blackjack! Went through several news and topics: 1) Elon’s comp package approved by shareholders, besties criticized some reneging people, who are really not good ones to do business with, 2) Apple announces “Apple Intelligence” and ChatGPT deal at WWDC, first time of opening up OS to the third party, raising data privacy concerns, 3) OpenAI reportedly hit a $3.4B revenue run rate, 4) state of US economy.
China’s AI Journey - Weighty Thoughts [Link]
Leopold Aschenbrenner - 2027 AGI, China/US Super-Intelligence Race, & The Return of History [Link]
Private Cloud Compute: A new frontier for AI privacy in the cloud - Apple Security Research [Link]
Real Success w/Christopher Tsai - We Study Billionaires Podcast [Link]
Morgan Housel: Get Rich, Stay Rich [Link]
Papers and Reports
SimPO: Simple Preference Optimization with a Reference-Free Reward [Link]
Deep Learning Interviews: Hundreds of fully solved job interview questions from a wide range of key topics in AI [Link]
Best preparation book for AI/ML job seekers and students.
The economic potential of generative AI: The next productivity frontier - McKinsey [Link]
Microsoft New Future of Work Report 2023 [Link]
Github
Anthropic has launched a new feature for its AI assistant, Claude, known as “Tool Use” or “function calling.”
All Machine Learning Algorithms Implemented in Python / Numpy [Link]
Spreadsheet Is All You Need [Link]
GPT architecture is recreated in spreadsheet.
Hello Qwen2 [Link]
Alibaba released new open-source LLM called Qwen2, which outperforms Meta’s Llama 3 in specialized tasks. It’s accessible via HuggingFace, with weights available and five model sizes (0.5B, 1.5B, 7B, 57B-14B (MoE), and 72B). Qwen2 has been trained on data in 29 languages, and can handle up to 128K tokens in context length. It has been benchmarked against Meta’s Llama 3 and OpenAI’s GPT-4, achieving top scores. The primary innovation of Qwen2 is its long-context understanding.
Cohere Cookbooks [Link]
A set of tutorials for building agents / AI applications.
News
Amazon to expand drone delivery service after clearing FAA hurdle [Link]
Amazon’s drone delivery services “Prime Air” was laid out more than a decade ago but has struggled since then. In 2022, Amazon said it would begin testing deliveries in College Station, Texas. In 2023, Prime Air was hit by layoffs. But recently Amazon said it would expand drone operations to Phoenix, Arizona, etc. And it’s expected to expand to other cities in 2025.
Salesforce’s stock suffers its biggest drop in two decades [Link]
NASA’s James Webb Space Telescope Finds Most Distant Known Galaxy [Link]
Saudi fund joins $400m funding round of Chinese AI startup Zhipu [Link]
A PR disaster: Microsoft has lost trust with its users, and Windows Recall is the straw that broke the camel’s back [Link]
As Microsoft has done a lot of things (obtrusive ads, full-screen popups, ignoring app defaults, forcing Microsoft Accounts, etc) to degrade the Windows user experience over the last few years, it lost the trust relationship between Windows users and Microsoft, therefore a tool like Recall is described as literal spyware or malware by users no matter how well you communicate the features to the world.
Apple Made Once-Unlikely Deal With Sam Altman to Catch Up in AI [Link]
The deal between Apple and OpenAI will give OpenAI access to hundreds of millions of Apple users, and bring Apple the hottest technology of the AI era - that can pair with its own services.
Nvidia is now more valuable than Apple at $3.01 trillion [Link]
Mark this today, on Jun 5, 2024, Nvidia’s market cap is higher than Apple becomes the second most valuable company in the world.
SpaceX’s Starship Rocket Successfully Completes 1st Return From Space [Link]
Woman Declared Dead Is Found Alive at Funeral Home [Link]
BYD Launches Hybrids With 1,300-Mile Driving Range [Link]
China’s plan to dominate EV sales around the world [Link]
Nvidia emails: Elon Musk diverting Tesla GPUs to his other companies [Link]
How Apple Fell Behind in the AI Arms Race [Link]
Next week, at Apple’s annual Worldwide Developers Conference, the company is set to join an AI arms race - announce an array of generative AI upgrades to its software products, including Siri.
Tesla’s $450 lightning-shaped bottle of mezcal is its most expensive liquor yet [Link]
Apple’s Upcoming AI Reveal, Pika Labs Raises $80 Million, Twelve Labs, $50 Million [Link]
Among the biggest spenders on sovereign AI is Singapore, whose national supercomputing center is being upgraded with Nvidia’s latest AI chips and where state-owned telecom Singtel is pushing an expansion of its data center footprint in Southeast Asia in collaboration with Nvidia. The country is also spearheading a large language model that is trained on Southeast Asian languages.
Other big projects are taking place in Canada, which last month pledged $1.5 billion as part of a sovereign computing strategy for the country’s startups and researchers, and Japan, which said it is investing about $740 million to build up domestic AI computing power this year following a visit from Huang.
Similar pushes are spreading across Europe, including those in France and Italy, where telecom companies are building AI supercomputers with Nvidia’s chips to develop local-language large language models. French President Emmanuel Macron last month called on Europe to create public-private partnerships to buy more graphics processing units, or the core chips used to train AI, to push its share of those deployed globally from 3% currently to 20% by 2030 or 2035.
― Nvidia’s New Sales Booster: The Global Push for National AI Champions [Link]
Cloud-computing giants and big tech companies have been a great source of revenue for NVIDIA, now Sovereign Al is another lever. Governments demand sovereign clouds for their AI infrastructure and sensitive data, and US tech companies such as NVIDIA are eager to build those for them. Question would be how long can they keep this momentum in generating high revenue.
Do you best creating, thinking, learning, brainstorming, note-taking - Google NotebookLM [Link]
Google upgraded its NotebookLM powered by Gemini 1.5.
There’s one other way Apple is dealing with privacy concerns: making it someone else’s problem. Apple’s revamped Siri can send some queries to ChatGPT in the cloud, but only with permission after you ask some really tough questions. That process shifts the privacy question into the hands of OpenAI, which has its own policies, and the user, who has to agree to offload their query. In an interview with Marques Brownlee, Apple CEO Tim Cook said that ChatGPT would be called on for requests involving “world knowledge” that are “out of domain of personal context.”
Apple’s local and cloud split approach for Apple Intelligence isn’t totally novel. Google has a Gemini Nano model that can work locally on Android devices alongside its Pro and Flash models that process on the cloud. Meanwhile, Microsoft Copilot Plus PCs can process AI requests locally while the company continues to lean on its deal with OpenAI and also build its own in-house MAI-1 model. None of Apple’s rivals, however, have so thoroughly emphasized their privacy commitments in comparison.
― Here’s how Apple’s AI model tries to keep your data private [Link]
Introducing Apple Intelligence, the personal intelligence system that puts powerful generative models at the core of iPhone, iPad, and Mac [Link]