As Columbia Business School professor Rita McGrath points out,
it’s about identifying “the strategic inflection points” at which the
cost of waiting exceeds to cost acting — in other words, identifying the
most strategic point to enter a market or adopt a technology, balancing
the risks and opportunities based on market readiness, technological
maturity and organizational capacity.
This speaks to the growing adoption of agile, “act, learn, build”
approaches over traditional “prove-plan-execute” orientations. The
popularity of techniques like discovery-driven
planning, the
lean startup, and other agile approaches and propagated this
philosophy in which, rather than building bullet-proof business cases,
one makes small steps, learning from them, and deciding whether to
invest further.
― “6 Strategic Concepts That Set High-Performing Companies
Apart”, Harvard Business Review [Article]
It’s a very good read. It provided real world business examples such
as Nvidia’s partnership with ARM Holdings and Amazon’s Alexa offering
for the strategic concept “borrow someone’s road”, Microsoft’s decision
to make Office available on Apple’s iOS devices in 2014 and Microsoft’s
partnership with Adobe, Salesforce, and Google for the strategic concept
“Parter with a third party”, Deere & Co’s decision on openly
investing in precision agriculture technologies for the strategic
concept “reveal your strategy”, Mastercard’s “Beyond Cash” initiative in
2012 for the strategic concept “be good”, Ferrari’s strategic entry into
the luxury SUV market for the strategic concept “let the competition
go”, and Tesla’s modular approach to battery manufacturing for the
strategic concept “adopt small scale attacks”.
Gig work is structured in a way that strengthens the alignment
between customers and companies and deepens the divide between customers
and workers, leading to systemic imbalances in its service
triangle.
Bridging the customer-worker divide can result in higher customer
trust and platform commitment, both by the customer and the
worker.
To start, platforms need to increase transparency, reduce
information asymmetry, and price their services clearly, allowing
customers to better understand what they are paying for rather than only
seeing an aggregated total at the end of the transaction. This, in turn,
can help customers get used to the idea that if workers are to be paid
fairly, gig work cannot be a free or low-cost service.
Gig workers might be working through an app, but they are not
robots, and they deserve to be treated respectfully and thoughtfully. So
tip well, rate appropriately, and work together to make the experience
as smooth as possible both for yourself and for workers.
― “How Gig Work Pits Customers Against Workers”, Harvard
Business Review [Article]
This is a good article for better understanding how gig work
structured differently than other business model, and what the key
points are for better business performance and triangle
relationships.
TCP/IP unlocked new economic value by dramatically lowering the
cost of connections. Similarly, blockchain could dramatically reduce the
cost of transactions. It has the potential to become the system of
record for all transactions. If that happens, the economy will once
again undergo a radical shift, as new, blockchain-based sources of
influence and control emerge.
“Smart contracts” may be the most transformative blockchain
application at the moment. These automate payments and the transfer of
currency or other assets as negotiated conditions are met. For example,
a smart contract might send a payment to a supplier as soon as a
shipment is delivered. A firm could signal via blockchain that a
particular good has been receivedor the product could have GPS
functionality, which would automatically log a location update that, in
turn, triggered a payment. We’ve already seen a few early experiments
with such self-executing contracts in the areas of venture funding,
banking, and digital rights management.
The implications are fascinating. Firms are built on contracts,
from incorporation to buyer-supplier relationships to employee
relations. If contracts are automated, then what will happen to
traditional firm structures, processes, and intermediaries like lawyers
and accountants? And what about managers? Their roles would all
radically change. Before we get too excited here, though, let’s remember
that we are decades away from the widespread adoption of smart
contracts. They cannot be effective, for instance, without institutional
buy-in. A tremendous degree of coordination and clarity on how smart
contracts are designed, verified, implemented, and enforced will be
required. We believe the institutions responsible for those daunting
tasks will take a long time to evolve, And the technology challenges
especially security are daunting.
― “The Truth About Blockchain”, Harvard Business
Review [Article]
This is the second Blockchain related article I have read from
Harvard Business Review. Different authors have different perspectives.
Unlike the previous article with a lot of concerns and cautions about
Web3, this article seems more optimistic. It proposed a framework for
adopting blockchain to revolutionize modern business, and a guidance to
Blockchain investment. It points out that Blockchain has great
potentials in boosting the efficiency and reducing the cost for all
transactions and then explained the reason why the adoption of
Blockchain would be slow by making a comparison with TCP/IP, which took
more than 30 years to reshape the economy by dramatically lowering the
cost of connections. This is an interesting comparison: e-mail enabled
bilateral messaging as the first application of TCP/IP, while bitcoin
enables bilateral financial transactions as the first application of
Blockchain. It reminds me about what people (Jun Lei, Huateng Ma, Lei
Ding, etc) were thinking about internet mindset and business model back
in 2000s.
In the end, the authors proposed a four-quadrant framework for
adopting Blockchain step by step. The four quadrants are created by two
dimensions: novelty (equivalent to the amount of efforts required to
ensure users understand the problem) and complexity (equivalent to the
amount of coordination and collaboration required to produce values).
With the increase of both dimensions, the adoption will require more
institutional change. An example of “low novelty and low complexity” is
simply adding bitcoin as an alternative transaction method. An example
of “low novelty and high complexity” is building a new, fully formed
cryptocurrency system which requires wide adoption from every monetary
transaction party and consumers’ complete understanding of
cryptocurrency. An example of “high novelty and low complexity” is
building a local private network on which multiple organizations are
connected via a distributed ledger. An example of “high novelty and high
complexity” is building “smart contracts”.
News
Does Amazon’s cashless Just Walk Out technology rely on 1,000
workers in India? [Link]
Amazon insists Just Walk Out isn’t secretly run by workers
watching you shop [Link]
An update on Amazon’s plans for Just Walk Out and
checkout-free technology [Link]
It’s been reported that there are over 1000 Indian workers behind the
cameras of Just Walk Out. It sounds dystopian and reminds me of
“Snowpiercer” movie in 2013. In 2022, about 700 of every 1000 Just Walk
Out sales had to be reviewed by Amazon’s team in India, according to The
Information. Amazon spokesperson explained that the technology is made
by AI (computer vision and deep learning) while it does rely on human
moderators and data labelers. Amazon clarified that it’s not true that
Just Walk Out relies on human reviewers. They said object detection and
receipt generation are completely AI powered, so no human watching live
videos. But human are responsible for labeling and annotation for data
preparation, which also requires watching videos.
I guess the technology was not able to complete the task end-to-end
by itself without supervision or it’s still on the developing stage? I
believe it could be Amazon’s strategy to build and test Just Walk Out,
Amazon Dash Cart, and Amazon One at the same time while improving AI
system, since they are “just getting started”. As Amazon found out that
customers prefer Dash Cart in large stores, it has already expanded Dash
Cart to all Amazon Fresh stores as well as third-party grocers. And
customers prefer Just Walk Out in small stores, so it’s available now in
140+ thrid-party locations. Customers love Amazon One’s security and
convenience regardless the scale of stores, so it’s now available at
500+ Whole Foods Market stores, some Amazon stores, and 150+ third-party
locations.
Data centres consume water directly to prevent information
technology equipment from overheating. They also consume water
indirectly from coal-powered electricity generation.
The report said that if 100 million users had a conversation with
ChatGPT, the chatbot “would consume 50,000 cubic metres of water – the
same as 20 Olympic-sized swimming pools – whereas the equivalent in
Google searches would only consume one swimming pool”.
― China’s thirsty data centres, AI industy could use more
water than size of South Korea’s population by 2030: report
warns [Link]
The rapid growth of AI could dramatically increase demand on water
resources. AI eats tokens, consumes compute, and drinks water.
15 Graphs That Explain the State of AI in 2024 [Link]
Stanford Institute for Human-Centered Artificial Intelligence (HAI)
published 2024’s AI Index report [Link].
502-page reading journey started.
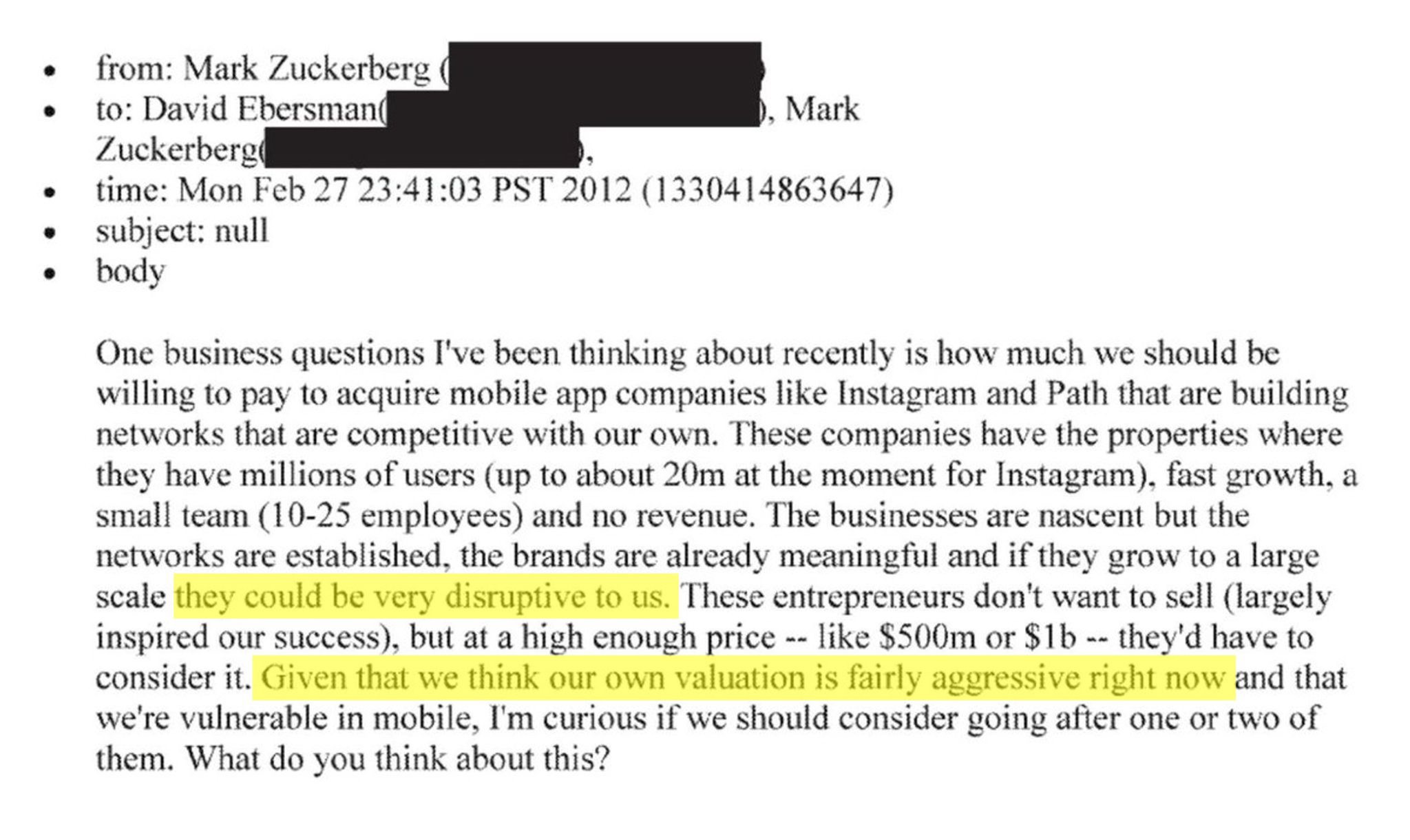
ins_emails1ins_emails2ins_emails3ins_emails4
― Leaked emails reveal why Mark Zuckerberg bought
Instagram [Link]
Zuckerberg’s discussion of Instagram acquisition back in 2012 proved
his corporate strategic foresights. He was aiming to buy the time and
network effect, rather than simply neutralizing competitors or improving
products. He bought Instagram for \(\$1\)B, today it is worth \(\$500\)B. It’s very impressive.
Introducing Meta Llama 3: The most capable openly available
LLM to date [Link]
Meta released early versions of Llama 3. Pretrained and
instruction-fine-tuned Llama3 with 8B and 70B parameters are now
open-source. Its 405B version is still training.
Llama 3 introduces Grouped Query Attention (GQA), which reduces the
computational complexity of processing large sequences by grouping
attention queries. Llama 3 also had extensive pre-training involving
over 15 trillion tokens, including a significant amount of content in
different languages, enhancing its applicability across diverse
linguistic contexts. Post-training techniques include finetuning and
rejection sampling which refine the model’s ability to follow
instructions and minimize error.
Cheaper, Better, Faster, Stronger - Continuing to push the
frontier of AI and making it accessible to all. [Link]
Mistral AI’s Mixtral 8x22B has a Sparse Mixture-of-Experts (SMoE)
architecture, which maximize efficiency by activating only 44B out of
176B parameters. The model’s architecture ensures that only the most
relevant “experts” are activated during specific tasks. The experts are
individual neural networks as apart of SMoE model. They are trained to
become proficient at particular sub-tasks out of the overall task. Since
only a few experts are engaged for any given input, this design reduces
computational complexity.
GPT-4-Turbo has significantly enhanced its multimodal capabilities by
incorporating AI vision technology. This model is able to analyze
videos, images, and audios. Its tokenizer now has a larger 128000 token
context window, which maximizes its memory.
The race to lead A.I. has become a desperate hunt for the digital
data needed to advance the technology. To obtain that data, tech
companies including OpenAI, Google and Meta have cut corners, ignored
corporate policies and debated bending the law, according to an
examination by The New York Times.
Tech companies are so hungry for new data that some are
developing “synthetic” information. This is not organic data created by
humans, but text, images and code that A.I. models produce — in other
words, the systems learn from what they themselves generate.
― How Tech Giants Cut Corners to Harvest Data for
A.I. [Link]
OpenAI developed a speech recognition tool ‘Whisper’ to transcribe
the audio from YouTube videos, generating text data for AI system.
Google employees know OpenAI had harvested YouTube videos for data but
they didn’t stop OpenAI because Google had also used transcripts of
YouTube videos for training AI models. Google’s rules about the legal
usage of YouTube videos is vague and OpenAI’s employee were wading into
a legal gray area.
As many tech companies such as Meta and OpenAI reached the stage of
data shortage, OpenAI started to train AI models by using synthetic data
synthesized by two different AI models, one produces the data, the other
judges the information.
Musk released the preview of first multimodal model Grok-1.5V. It is
able to understand both textual and visual information. One unique
feature is that it adopts Rust, JAX, and Kubernetes to construct its
distributed training architecture.
One page of the Microsoft presentation highlights a variety of
“common” federal uses for OpenAI, including for defense. One bullet
point under “Advanced Computer Vision Training” reads: “Battle
Management Systems: Using the DALL-E models to create images to train
battle management systems.” Just as it sounds, a battle management
system is a command-and-control software suite that provides military
leaders with a situational overview of a combat scenario, allowing them
to coordinate things like artillery fire, airstrike target
identification, and troop movements. The reference to computer vision
training suggests artificial images conjured by DALL-E could help
Pentagon computers better “see” conditions on the battlefield, a
particular boon for finding — and annihilating — targets.
OpenAI spokesperson Liz Bourgeous said OpenAI was not involved in
the Microsoft pitch and that it had not sold any tools to the Department
of Defense. “OpenAI’s policies prohibit the use of our tools to develop
or use weapons, injure others or destroy property,” she wrote. “We were
not involved in this presentation and have not had conversations with
U.S. defense agencies regarding the hypothetical use cases it
describes.”
Microsoft told The Intercept that if the Pentagon used DALL-E or
any other OpenAI tool through a contract with Microsoft, it would be
subject to the usage policies of the latter company. Still, any use of
OpenAI technology to help the Pentagon more effectively kill and destroy
would be a dramatic turnaround for the company, which describes its
mission as developing safety-focused artificial intelligence that can
benefit all of humanity.
― Microsoft Pitched OpenAI’s DALL-E as Battlefield Tool for
U.S. Military [Link]
Other than what has mentioned in the news, by cooperating with
Department of Defense, AI can understand how human battle and defense,
which is hard to learn from current textual and visual information from
the internet. So it’s possible that this is the first step of AI
troop.
Microsoft scientists developed what they call a qubit
virtualization system. This combines quantum error-correction techniques
with strategies to determine which errors need to be fixed and the best
way to fix them.
The company also developed a way to diagnose and correct qubit
errors without disrupting them, a technique it calls “active syndrome
extraction.” The act of measuring a quantum state such as superposition
typically destroys it. To avoid this, active syndrome extraction instead
learns details about the qubits that are related to noise, as opposed to
their quantum states, Svore explains. The ability to account for this
noise can permit longer and more complex quantum computations to proceed
without failure, all without destroying the logical qubits.
― Microsoft Tests New Path to Reliable Quantum Computers
1,000 physical qubits for each logical one? Try a dozen, says
Redmond [Link]
Think about it in the sense of another broad, diverse category
like cars. When they were first invented, you just bought “a car.” Then
a little later, you could choose between a big car, a small car, and a
tractor. Nowadays, there are hundreds of cars released every year, but
you probably don’t need to be aware of even one in ten of them, because
nine out of ten are not a car you need or even a car as you understand
the term. Similarly, we’re moving from the big/small/tractor era of AI
toward the proliferation era, and even AI specialists can’t keep up with
and test all the models coming out.
This week, the speed of releasing LLMs becomes about 10 per week.
This article provides good explanation about why we don’t need to keep
up with it or test all released models. Car is a good analogy to AI
model nowadays. There are all kinds of brands and sizes, and designed
for different purposes. Hundreds of cars are released every year, but
you don’t need to know them. Majority of the models are not
groundbreaking but whenever there is big step, you will be aware of
it.
Although not necessary to catch up all the news, we at least need to
be aware of the main future model features - where modern and future
LLMs are heading to: 1) multimodality 2) recall capability 3)
reasoning.
ByteDance Exploring Scenarios for Selling TikTok Without
Algorithm [Link]
ByteDance is internally exploring scenarios for selling TikTok’s US
business to non-tech industry without the algorithm if they exhausted
all legal options to fight legislation of the ban. Can’t imagine who
without car expertise is going to buy a car without engine.
Developers and creators can take advantage of all these
technologies to create mixed reality experiences. And they can reach
their audiences and grow their businesses through the content discovery
and monetization platforms built into Meta Horizon OS, including the
Meta Quest Store, which we’ll rename the Meta Horizon Store.
Introducing Our Open Mixed Reality Ecosystem [Link]
Everyone knows how smart Zuck is in the idea of open-source.
Other news:
Elon Musk says Tesla will reveal its robotaxi on August
8th [Link]
SpaceX launches Starlink satellites on record 20th reflight
of a Falcon 9 rocket first stage [Link]
Deploy your Chatbot on Databricks AI with RAG, DBRX Instruct,
Vector Search & Databricks Foundation Models [Link]
Adobe’s ‘Ethical’ Firefly AI Was Trained on Midjourney
Images [Link]
Exclusive: Microsoft’s OpenAI partnership could face EU
antitrust probe, sources say [Link]
Anthropic-cookbook: a collection of notebooks / recipes
showcasing some fun and effective ways of using Claude [Link]
Amazon deploys 750,000+ robots to unlock AI
opportunities [Link]
Apple’s four new open-source models could help make future AI
more accurate [Link]
The Mystery of ‘Jia Tan,’ the XZ Backdoor Mastermind
[Link]
YouTube
If someone whom you don’t trust or an adversary gets something
more powerful, then I think that that could be an issue. Probably the
best way to mitigate that is to have good open source AI that becomes
the standard and in a lot of ways can become the leader. It just ensures
that it’s a much more even and balanced playing field.
― Mark Zuckerberg - Llama 3, $10B Models, Caesar Augustus,
& 1 GW Datacenters [Link]
What I learned from this interview: The future of Meta AI would be a
kind of AI general assistant product where you give it complicated tasks
and then it goes away and does them. Meta will probably build bigger
clusters. No one has built 1GW data center yet but building it could
just be a matter of time. Open source can be both bad and good. People
can use LLM to do harmful things, while what Mask worries more about is
the concentration of AI, where there is an untrustworthy actor having
the super strong AI. Open source software can make AI not getting stuck
in one company but can be broadly deployed to a lot of different
systems. People can set standards on how it works and AI can get checked
and upgraded together.
It is clear that inference was going to be a scaled problem.
Everyone else had been looking at inference as you take one chip, you
run a model on it, it runs whatever. But what happened with AlphaGo was
we ported the software over, and even though we had 170 GPUs vs 48 TPUs,
the 48 TPUs won 99 out of 100 games with the exact same software. What
that meant was compute was going to result in better performance. And so
the insight was - let’s build scaled inference.
(Nvidia) They have the ecosystem. It’s a double-sided market. If
they have a kernel-based approach they already won. There’s no catching
up. The other way that they are very good is vertical integration and
forward integration. What happens is Nvidia over and over again decides
that they want to move up the stack, and whatever the customers are
doing, they start doing it.
Nvidia is incredible at training. And I think the design decision
that they made including things like HBM, were really oriented around
the world back then, which was everything is about training. There
weren’t any real world application. None of you guys were really
building anything in the wild where you needed super fast
inference.
What we saw over and over again was you would spend 100% of your
compute on training, you would get something that would work well enough
to go into production, and then it would flip to about 5%-10% training
and 90%-95% inference. But the amount of training would stay the same,
the inference would grow massively. And so every time we would have a
success at Google, all of a sudden, we would have a disaster, we called
it the success disaster, where we can’t afford to get enough compute for
inference.
HBM is this High Bandwidth Memory which is required to get
performance, because the speed at which you can run these applications
depends on how quickly you can read that into memory. There’s a finite
supply, it’s only for data centers, so they can’t reach into the supply
for mobile or other things, like you can with other parts. Also Nvidia
is the largest buyer of super caps in the world and all sorts of other
components. The 400 gigabit cables, they’ve bought them all out. So if
you want to compete, it doesn’t matter how good of a product you design,
they’ve bought out the entire supply chain for years.
The biggest difference between training and inference is when you
are training, the number of tokens that you are training on is measured
in month, like how many tokens can we train on this month. In inference,
what matters is how many tokens you can generate per millisecond or a
couple milliseconds.
It’s fair to say that Nvida is the exemplar in training but
really isn’t yet the equivalent scaled winner in inference.
In order to get the latency down, we had to design a completely
new chip architecture, we had to design a completely new networking
architecture, an entirely new system, an entirely new runtime, an
entirely new compiler, and entirely new orchestration layer. We had to
throw everything away and it had to be compatible with PyTorch and what
other people actually developing in.
I think Facebook announced that by the end of this year, they are
going to have the equivalent of 650000 H100s. By the end of this year,
Grok will have deployed 100000 of our LPUs which do outperform the H100s
on a throughput and on a latency basis. So we will probably get pretty
close to the equivalent of Meta ourselves. By the end of next year, we
are going to deploy 1.5M LPUs, for comparison, last year Nvidia deployed
a total of 500000 H100s. So 1.5M means Grok will probably have more
inference GenAI capacity than all of the hyperscalers and clouds service
providers combined. So probably about 50% of the inference compute in
the world.
I get asked a lot should we be afraid of AI and my answer to that
is, if you think back to Galileo, someone who got in a lot of trouble.
The reason he got in trouble was he invented the telescope, popularized
it, and made some claims that we were much smaller than everyone wanted
to believe. The better the telescope got the more obvious it became that
we were small. In a large sense, LLMs are the telescope for the mind,
it’s become clear that intelligence is larger than we are and it makes
us feel really really small and it’s scary. But what happened over time
was as we realized the universe was larger than we thought and we got
used to that, we started to realize how beautiful it was and our place
in the universe. And I think that’s what’s going to happen. We’re going
to realize intelligence is more vast than we ever imagined. And we are
going to understand our place in it, and we are not going to be afraid
of it.
This is a very insightful conversation especially in the part of
comparison of training and inference. The answer to the final question
is fascinating to end the conversation. A great takeaway that
“intelligence is a telescope for the mind, in that we realize that we
are small, while then also opportunity to see intelligence is vast and
to not be afraid of it.”.
Meta Announces Llama 3 at Weights & Biases’ Conference -
Weights & Biases [Link]
Economic value is getting disintegrated, there no value in
foundational models economically. So then the question is who can build
on top of them the fastest. Llama was announced last Thursday, 14 hours
later Groq actually had that model deployed in the Groq Cloud, so that
100K+ developers could start building on it. That’s why that model is so
popular. It puts the closed models on their heels. Because if you can’t
both train and deploy iteratively and quickly enough, these open source
alternatives will win, and as a result the economic potential that you
have to monetize those models will not be there. - Chamath
Palihapitiya
By open-sourcing these models they limit competition because VCs
are no longer going to plow half a billion dollars into a foundational
model development company, so you limit the commercial interest and the
commercial value of foundational models. - David Friedberg
AI is really two markets - training and inference. And inference
is going to be 100 times bigger than training. And Nvidia is really good
at training and very miscast at inference. The problem is that right now
we need to see a capex build cycle for inference, and there are so many
cheap and effective solutions, Groq being one of them but there are many
others. And I think why the market reacted very negatively was that it
did not seem that Facebook understood that distinction, that they were
way overspending and trying to allocate a bunch of GPU capacity towards
inference that didn’t make sense. - Chamath Palihapitiya
You want to find real durable moats not these like legal
arrangement that try to protect your business through these types of
contracts. One of the reasons why the industry moves so fast is best
practices get shared very quickly, and one of the ways that happens is
that everybody is moving around to different companies (average term of
employment is 18-36 months). There are people who violate those rules
(taking code to the new company etc), and that is definitely breaking
the rules, but you are allowed to take with you anything in your head,
and it is one of the ways that best practices sort of become more
common. - David Sacks
Are LLMs Hitting A Wall, Microsoft & Alphabet Save The
Market, TikTok Ban - Big Technology Podcast [Link]
Papers and Reports
ReALM: Reference Resolution As Language ModelingLink]
Apple proposed the ReALM model with 80M, 250M, 1B, and 3B parameters.
It can be used on mobile devices and laptops. The task of ReALM is
“Given relevant entities and a task the user wants to perform, we wish
to extract the entity (or entities) that are pertinent to the current
user query. “. The relevant entities can be on-screen entities,
conversational entities, and background entities. The analysis shows
that ReALM beats MARRs and has similar performance with GPT-4.
Bigger is not Always Better: Scaling Properties of Latent
Diffusion Models [Link]
Leave No Context Behind: Efficient Infinite Context
Transformers with Infini-attention [Link]
Google introduced the next generation transformer -
infini-transformer. It’s able to take infinite length of input without
the requirement of more memory or computation. Unlike vanilla attention
mechanism in traditional transformer which reset their attention memory
after each context window to manage new data, infini-attention retains a
compressive memory and builds in both masked local attention and
long-term linear attention mechanisms. The model compresses and reuses
key-value states across all segments, allowing it to pull relevant
information from any part of the document.
AI agents are starting to transcend their digital origins and
enter the physical world through devices like smartphones, smart
glasses, and robots. These technologies are typically used by
individuals who are not AI experts. To effectively assist them, Embodied
AI (EAI) agents must possess a natural language interface and a type of
“common sense” rooted in human-like perception and understanding of the
world.
OpenEQA: Embodies Question Answering in the Era of Foundation
Models [Link] [Link]
The OpenEQA introduced by Meta is the first open vocab benchmark
dataset for the formulation of Embodied Question Answering (EQA) task of
understanding environment either by memory or by active exploration,
well enough to answer questions in natural language. Meta also provided
an automatic LLM-powered evaluation protocol to evaluate the performance
of SOTA models like GPT-4V and see whether it’s close to human-level
performance.
OpenEQA looks like the very first step towards “world model” and I’m
excited that it’s coming. The dataset contains over 1600 high-quality
human generated questions drawn from over 180 real-world environments.
If the future AI agent can answer N questions over N real-world
environments, where N is approximately infinity, we can call it God
intelligence. But we are probably not able to achieve that “world model”
at least with my limited imagination, because it requires un-infinite
compute resources and there can be ethical issues. However, if we take
one step back, instead of creating “world model”, a “human society
model” or “transformation model”, etc, sounds more possible. Limiting
question to a specific pain point problem and limiting environment
according to it would both save resources and contribute AI’s value to
human society.
OpenELM: An Efficient Language Model Family with Open-source
Training and Inference Framework [Link] [Link]
OpenELM is a small language model (SLM) tailored for on-device
applications. The models range from 270M to 3B parameters, which are
suitable for deployment on mobile devices and PCs. The key innovation is
called “layer-wise scaling architecture”. It allocates fewer parameters
to the initial transformer layers and gradually increases the number of
parameters towards the final layers. This approach optimizes compute
resources while remaining high accuracy. Inference of OpenELM can be run
on Intel i9 workstation with RTX 4090 GPU and an M2 Max MacBook Pro.
Phi-3 Technical Report: A Highly Capable Language Model
Locally on Your Phone [Link] [Link]
Microsoft launched Phi-3 family including mini (3.8B), small (7B),
and medium (14B). These models are designed to run efficiently on both
mobile devices and PCs. All models leverage a transformer decoder
architecture. The performance is comparable to larger models such as
Mixtral 8x7B and GPT3.5. It supports a default of 4K context length but
is expandable to 128K through LongRope technology. The models are
trained on web data and synthetic data, using two-phase approach which
enhances both general knowledge and specialized skills (e.g. logical
reasoning), and fine tuned in specific domains. Mini (3.8B) is
especially optimized for mobile usage, requiring 1.8GB memory when
compressed to 4-bits and processing 12+ tokens per second on mobile
devices such as iPhone 14.
VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real
Time [Link] [Link]
2024 Generative AI Prediction Report from CB
insights [Link]
You get paid based on how hard you are to replace.
You get paid based on how much value you deliver.
Focus on being able to produce value and money will
follow.
― Andrew Lokenauth
What he’s saying is so true - Don’t work so hard and end up losing
yourself.
There is a popular saying on Wall Street. While IPO means Initial
Public Offering, it also means “It’s Probably Overpriced” (coined by Ken
Fisher).
I don’t invest in brand-new IPOs during the first six months.
Why? Shares tend to underperform out of the gate for new public
companies and often bottom around the tail end of the lock-up period,
with anticipation of selling pressure from insiders. It’s also critical
to gain insights from the first few quarters to form an opinion about
the management team.
Do they forecast conservatively?
Do they consistently beat their guidance?
If not, it might be a sign that they are running out of steam and
may have embellished their prospects in the S-1. But we need several
quarters to understand the dynamic at play.
An analysis of Rubrik, a Microsoft-backed cybersecurity company going
public. I’ve got some opinions from the author in terms of company
performance and strategic investment.
Intel Unleashes Enterprise AI with Gaudi 3 - AI
Supremacy [Link]
Intel is a huge beneficiary of Biden’s CHIPS Act. In late March 2024,
Intel will receive up to \(\$8.5\)
billion in grants and \(\$11\) billion
in loans from the US government to produce cutting-edge
semiconductors.
US Banks: Uncertain Year - App Economy Insights [Link]
Formula 1’s recent surge in popularity and revenue isn’t simply a
product of fast cars and daring drivers. The Netflix docuseries Drive to
Survive, which premiered in March 2019 and is already in its sixth
season, has played a transformative role in igniting global interest and
fueling unprecedented growth for the sport.
The docuseries effectively humanized the sport, attracting new
fans drawn to the high-stakes competition, team rivalries, and
compelling personal narratives.
― Formula 1 Economics - App Economy Insights [Link]
Recent business highlights: 1) focus on drama and storylines around
sports, 2) subscribers can download exclusive games on the App Store for
free, since Nov 2021, and Netflix is exploring game monetization through
in-app purchases or ads, 3) for Premium Subscription Video on Demand,
churn plummets YoY, 4) the \(\$6.99\)/month ad-supported plan was
launched in Nov 2023, memberships grew 65% QoQ and monetization is still
lagging, 5) started limiting password sharing within one household.
Boeing 737 MAX’s two fatal crashes due to faulty software have eroded
public trust. In addition to quality issues, Boeing is facing severe
production delays. Airbus on the other hand has captured significant
market share from Boeing. Airbus is heavily investing in technologies
such as hydrogen-powered aircraft and sustainable aviation fuels. Airbus
is also investing in the A321XLR and potential new widebody
aircraft.
We disagree on what open-source AI should mean -
Interconnects [Link]
This is a general trend we have observed a couple of years ago.
We called is Mosaic’s Law where a model of a certain
capability will require 1/4th the dollars every year from hw/sw/algo
advances. This means something that is \(\$100\)m today -> \(\$25\)m next year -> \(\$6\)m in 2 yrs -> \(\$1.5\)m in 3 yrs.― Naveen Rao on
X [Link]
DBRX: The new best open model and Databricks’ ML strategy -
Interconnects [Link]
In the test of refusals, it shows that the inference system seems to
contain an added filtering in the loop to refuse illegal requests.
Llama 3: Scaling open LLMs to AGI - Interconnects
[Link]
Q1 FY24 is bad and probably the worst. This means Tesla is going to
get better in the rest of the year. It sounds that Elon is more clear
and focused on his plan. And promises are met though there are some
delays [Master Plan,
Part Deux].
Recent business highlights: 1) cancelling Model 2 and focusing on
Robotaxis and next-gen platform (Redwood), 2) laying off 10%+, 3) FSD
price cuts and EV (Model 3 and Model Y) price cuts, 4) Recall Cybertruck
due to safety issues, 5) North American Charging Standard (NACS) is
increasingly adopted by major automakers, 6) reached ~1.2B miles driven
by FSD beta, 7) energy storage deployment increased sequentially.
What is competitive in the market: 1) competitive pressure from BYD,
2) OpenAI’s Figure 01 robot and Boston Dynamics’s next-gen Atlas are
competing with Optimus.
With its open-source AI model Llama, Meta learned that the
company doesn’t have to have the best models — but they need a lot of
them. The content creation potential benefits Meta’s platforms, even if
the models aren’t exclusively theirs.
Like Google with Android, Meta aims to build a platform to avoid
being at the mercy of Apple or Google’s ecosystems. It’s a defensive
strategy to protect their advertising business. The shift to a new
vision-based computing experience is an opportunity to do so.
Meta has a head start in the VR developer community compared to
Apple. A more open app model could solidify this advantage.
By now, Meta has a clear playbook for new products:
Release an early version to a limited audience.
Gather feedback and start improving it.
Make it available to more people.
Scale and refine.
Monetize.
He also shared some interesting nuggets:
Roughly 30% of Facebook posts are AI-recommended.
Over 50% of Instagram content is AI-recommended.
― Meta: The Anti-Apple - App Economy Insights [Link]
Recent business highlights: 1) announced an open model for Horizon OS
- which powers its VR headsets, 2) Meta AI is now powered by Llama 3, 3)
whether not TikTok will still exist in US does not matter since the
algorithm will not be sold, then it will benefit any competitor company
such as Meta.