Advanced RAG
There are many enterprise products built almost solely on RAG.
Naive RAG
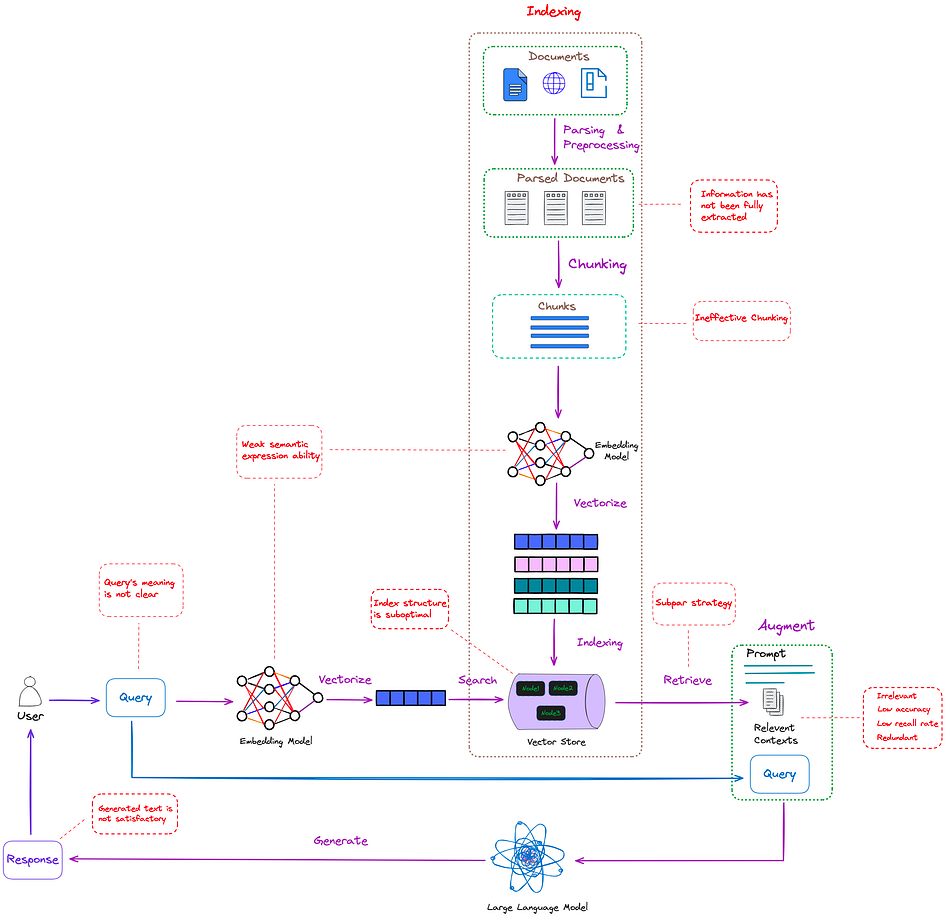
The standard RAG workflow consists of three main steps as illustrated in the graph below:
- Indexing: Creating an index of documents for retrieval.
- Retrieval: Searching the index for relevant documents based on a user query.
- Generation: Using a language model to generate answers or responses based on the retrieved documents.
The three steps all face possible issues:
Indexing:
Poor document parsing.
Inefficient document chunking strategies.
Weak semantic representations from embedding models.
Non-optimized index structures.
Retrieval:
Low relevance: retrieved documents are not highly relevant to the user query (low accuracy).
Incomplete retrieval: not all relevant documents are retrieved (low recall).
Redundancy: retrieved documents may be repetitive or redundant.
Queries are often not specific or well-defined.
Retrieval strategies might not be well-suited to the use case and may rely solely on semantic similarity.
Generation:
- Overreliance on the retrieved content, leading to issues such as irrelevant or even harmful responses (e.g., toxic or biased content).
This paper “Retrieval-Augmented Generation for Large Language Models: A Survey” discussed several problems associated with Naive RAG implementations. The advanced approaches to RAG attempt to overcome the limitations of naive RAG by improving the way queries are processed, documents are retrieved, and responses are generated. Advanced RAG techniques focus on refining each step of the process, from query transformations to more efficient retrieval strategies.
Advanced RAG
Overview
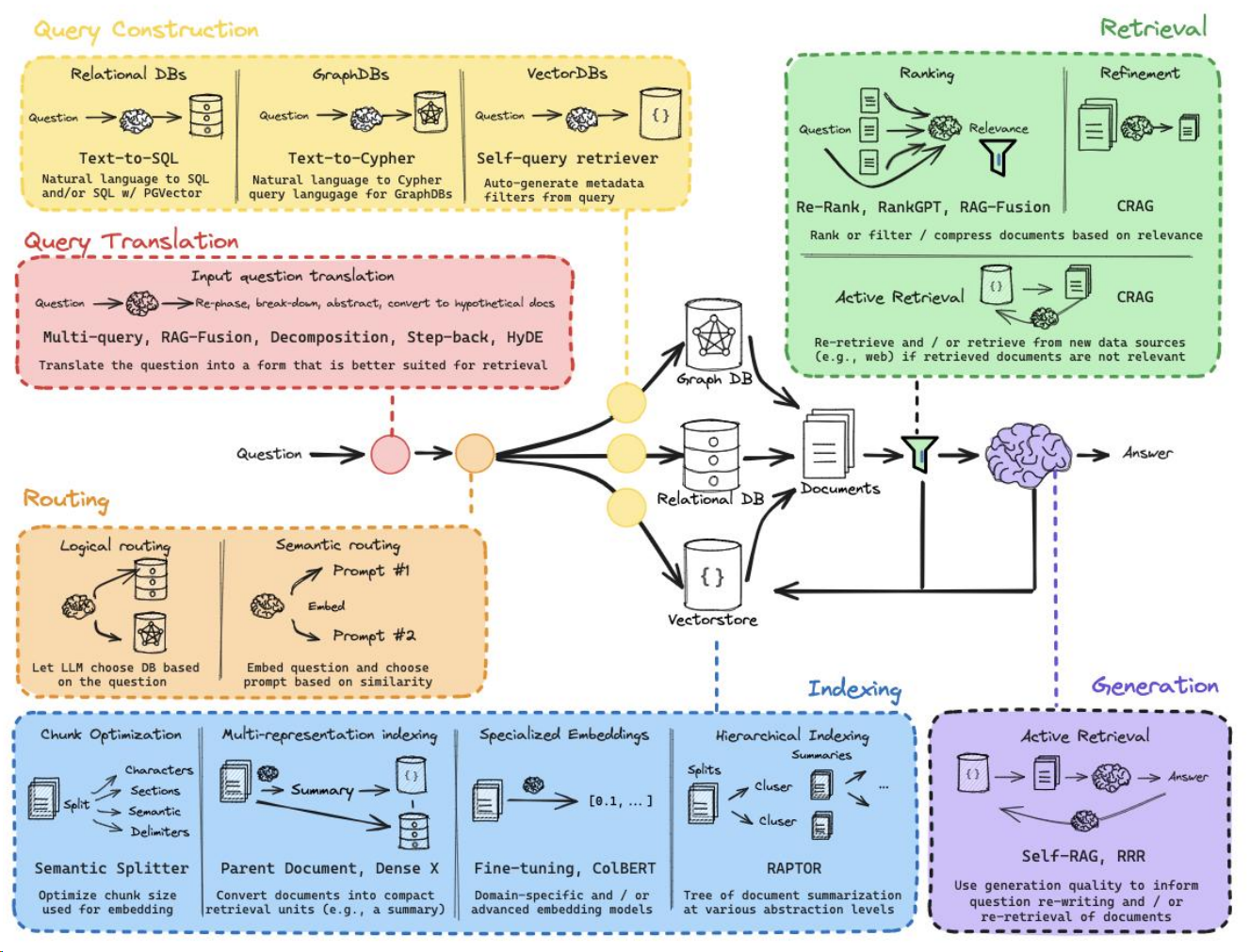
Source: LangChain
Pre-Retrieval Enhancements
Query Transformations / Translation
Query transformations are techniques aimed at re-writing or modifying the input questions to improve the retrieval process.
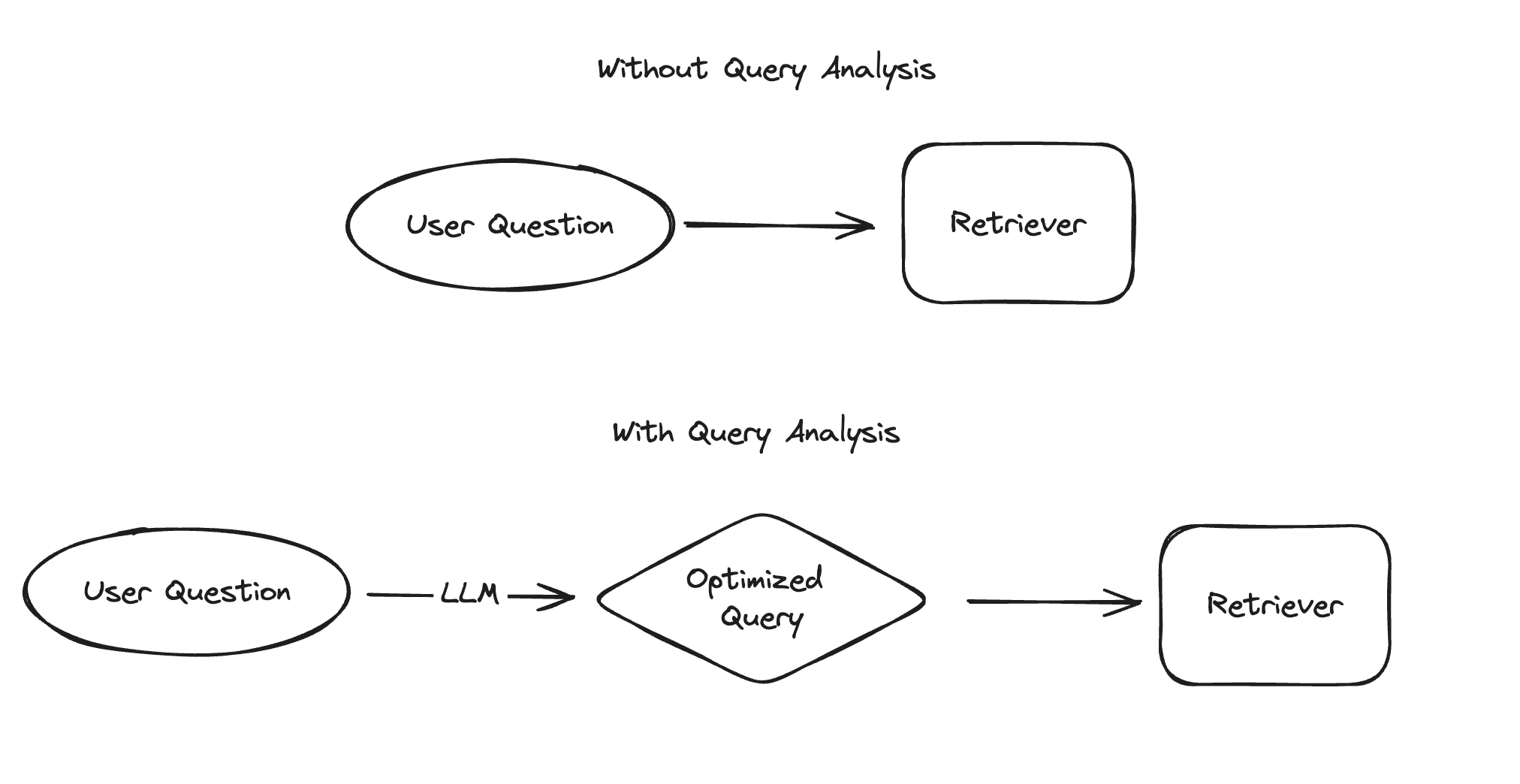
Query transformation types:
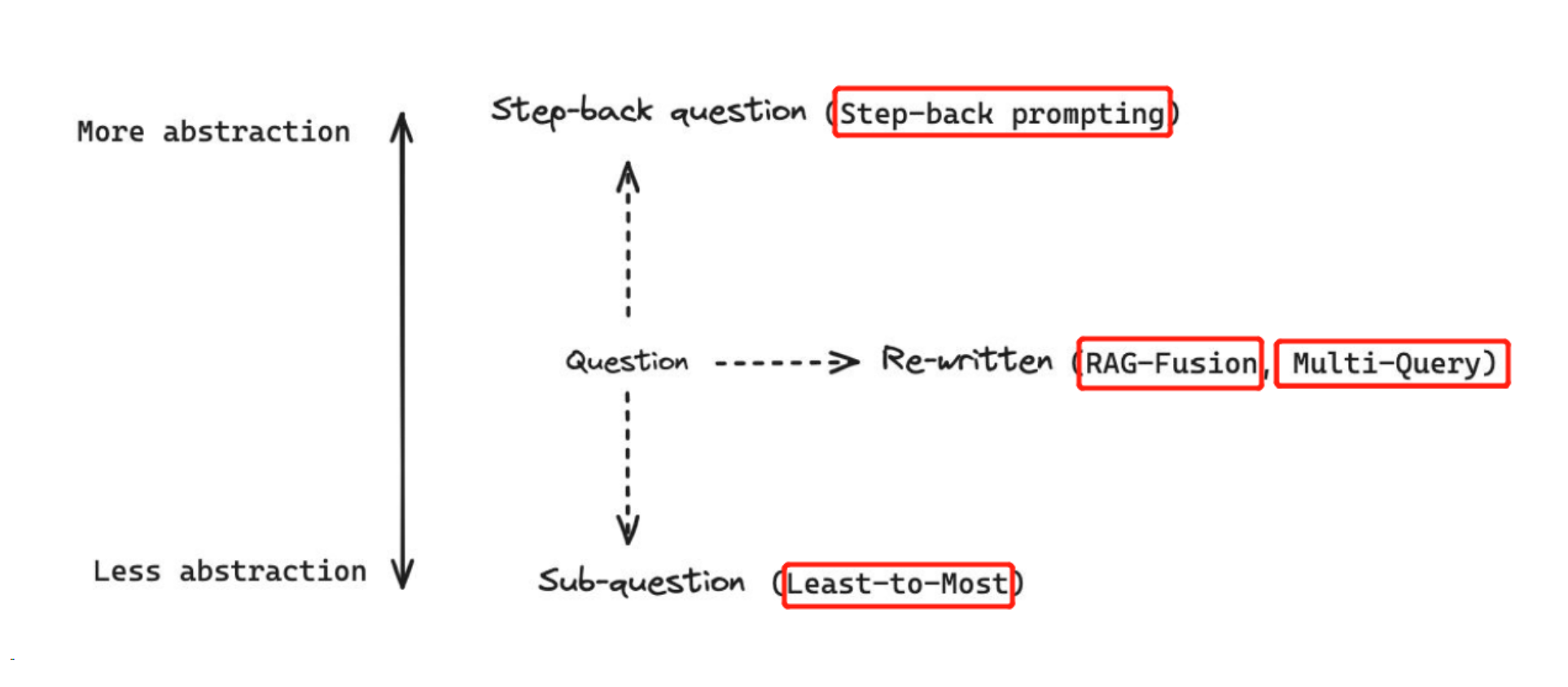
Some notable methods include:
Multi Query:
The MultiQueryRetriever automates prompt tuning by using a language model (LLM) to generate multiple queries from different perspectives for a given user query. It retrieves relevant documents for each generated query and combines the results to create a larger, more comprehensive set of potentially relevant documents. This technique helps mitigate some of the limitations of distance-based retrieval, save time on experimenting with different prompts, and provides a richer set of results.
LangChain Tutorial: How to use MultiQueryRetriever.
LangChain API: MultiQueryRetriever.
Video Tutorial: RAG from Scratch (Part 5 - Query Translation: Multi Query).
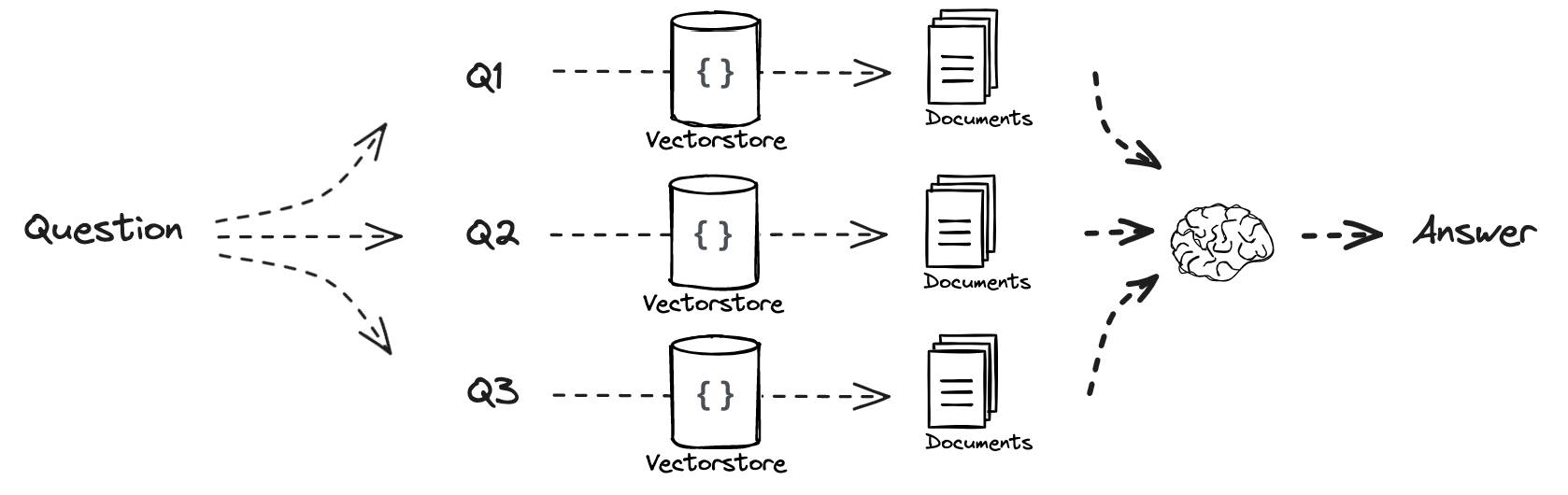
RAG Fusion
RAG-Fusion combines RAG and Reciprocal Rank Fusion (RRF) by generating multiple queries, reranking them with reciprocal scores and fusing the documents and scores. RRF gives the more relevant retrieval results higher scores and re-ranks them according to the scores. RAG-Fusion was able to provide accurate and comprehensive answers due to the generated queries contextualizing the original query from various perspectives.
Paper: A New Take on Retrieval-Augmented Generation.
Code: Raudaschl/rag-fusion
LangChain Cookbook:RAG Fusion
Video Tutorial: RAG from scratch: Part 6 (Query Translation – RAG Fusion)
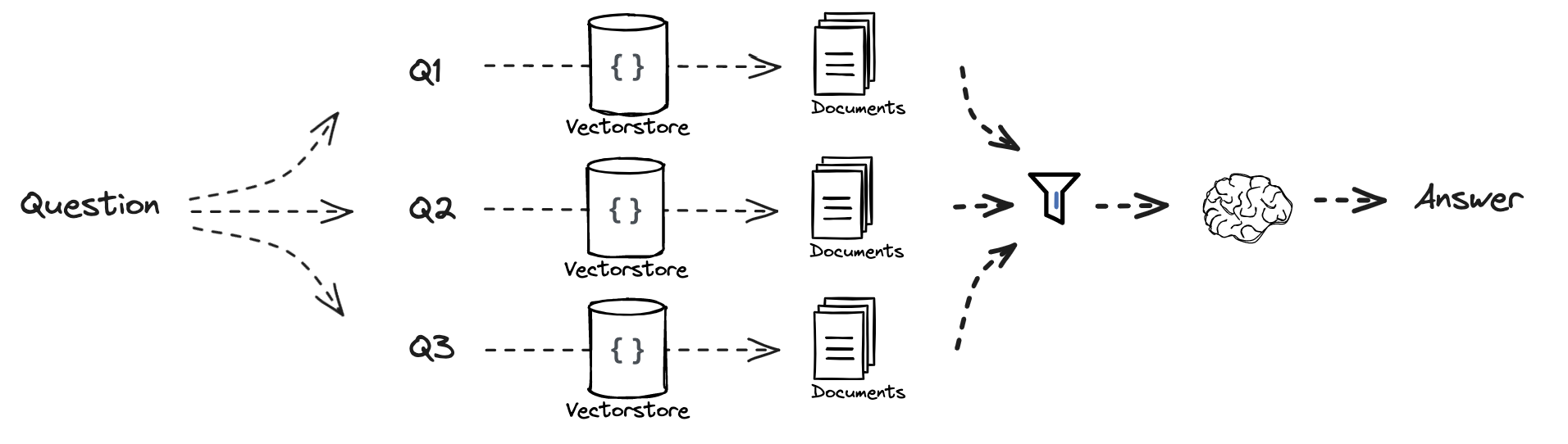
Step-Back Prompting
Step back prompting refers to the technique of generating a more generalized or abstract version of a specific query in order to mitigate potential issues with search quality or model-generated responses. This involves first reformulating the initial question into a broader or higher-level version (the “step back” question) and then querying both the original and the generalized question to improve the comprehensiveness and relevance of the responses.
Paper: Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models“.
LangChain Tutorial: Step Back Prompting
LangChain Cookbook: Step-Back Prompting (Question-Answering)
Video Tutorial: RAG from scratch: Part 8 (Query Translation – Step Back)
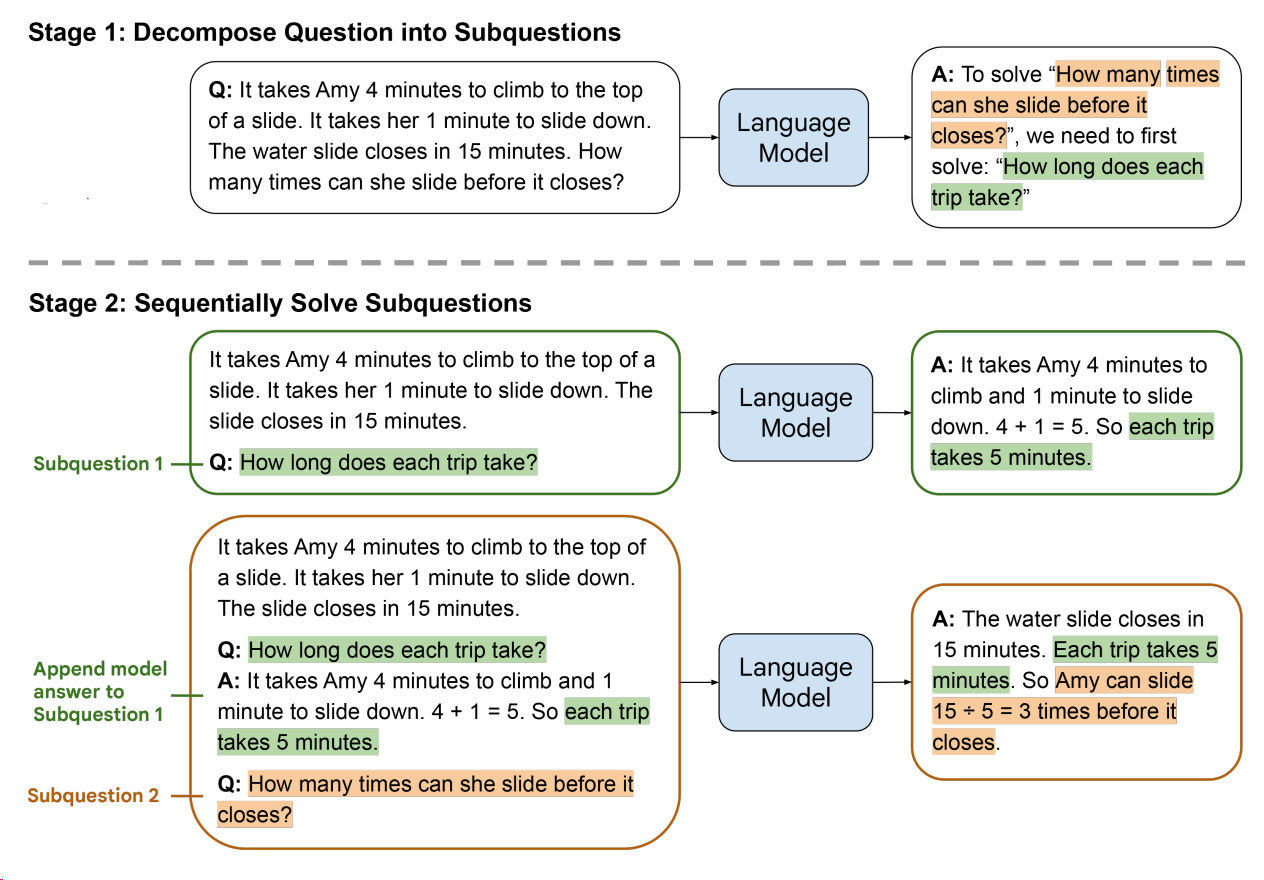
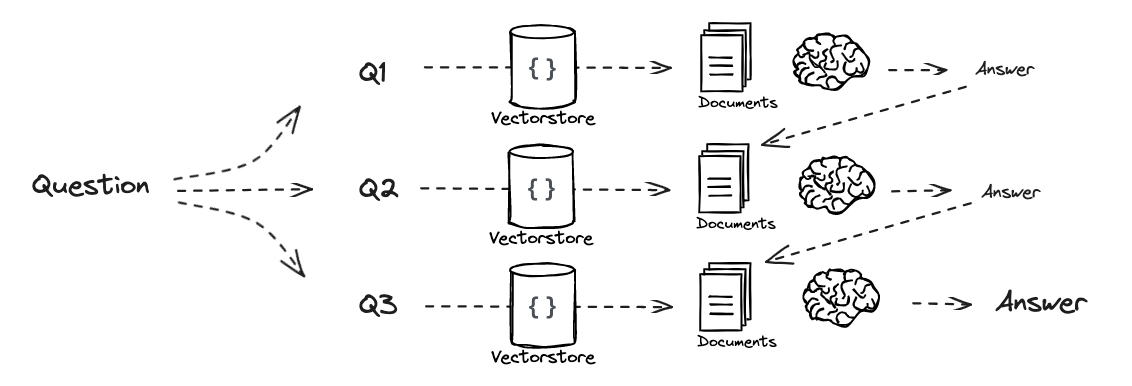
Decomposition:
When a user asks a complex question, a single query might not retrieve the right results. To address this, the question can be broken into sub-questions, each of which is retrieved separately, and the answers are combined.
LangChain Doc: Decomposition
Video Tutorial: RAG from scratch: Part 7 (Query Translation – Decomposition)
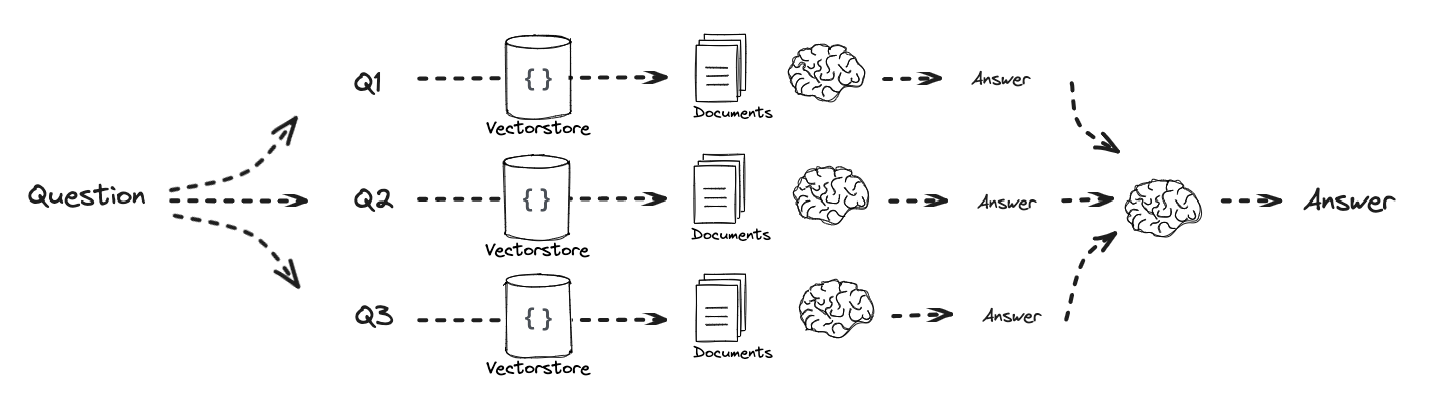
Least-to-Most Prompting
The key idea in this strategy is to break down a complex problem into a series of simpler subproblems and then solve them in sequence. Solving each subproblem is facilitated by the answers to previously solved subproblems. Least-to-most prompting is capable of generalizing to more difficult problems than those seen in the prompts.
Paper: Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Video Tutorial: RAG from scratch: Part 7 (Query Translation – Decomposition)
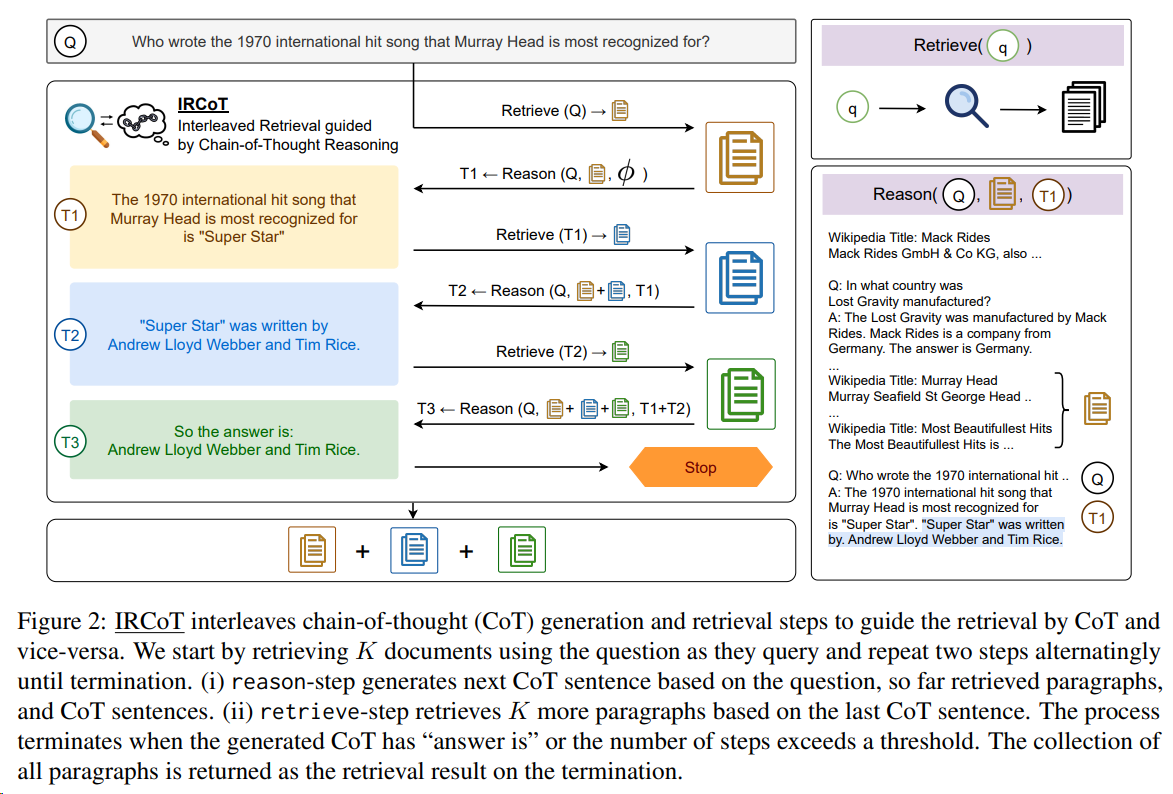
IR-Cot
An approach for multi-step QA that interleaves retrieval with steps (sentences) in a CoT, guiding the retrieval with CoT and in turn using retrieved results to improve CoT. It incorporates the idea of least-to-most prompting into RAG to improve retrieval, resulting in factually more accurate CoT reasoning.
Paper: Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions
IR-CoT Code:https://github.com/StonyBrookNLP/ircot
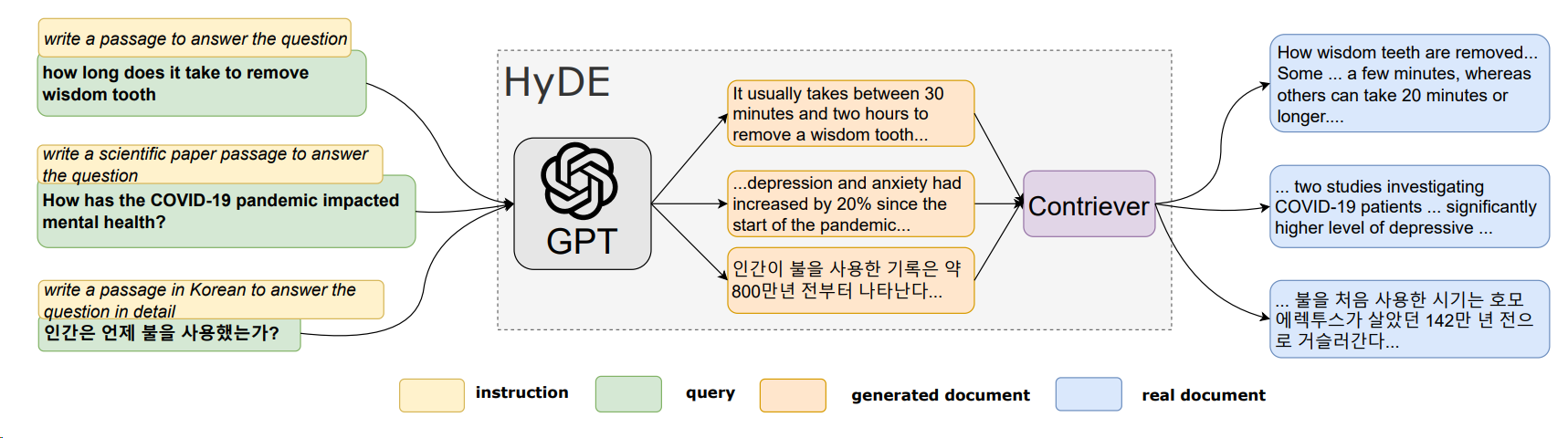
Hypothetical Document Embeddings (HyDE): Given a query, HyDE first zero-shot instructs an instruction-following language model to generate a hypothetical document. The document captures relevance patterns but is unreal and may contain false details. Then, an unsupervised contrastively learned encoder (e.g. Contriever) encodes the document into an embedding vector. This vector identifies a neighborhood in the corpus embedding space, where similar real documents are retrieved based on vector similarity.
Simply speaking, HyDE uses responses to retrieve documents rather than using queries to retrieve documents. The rational behind this approach is that the semantic similarity between query and real document is smaller than the semantic similarity between hypothetical document and real document.
LangChain Doc: Hypothetical Document Embeddings
Paper: Precise Zero-Shot Dense Retrieval without Relevance Labels
LangChain Cookbook: Improve document indexing with HyDE
New queries based on historical dialogues
This is a required technique for developing a chatbot or a conversational RAG.
LangChain Tutorials: Conversational RAG; Build a Chatbot; How to add message history; How to add memory to chatbots
LangChain Code: create_history_aware_retriever
Query Construction
Query construction refers to converting a natural language query into the query language specific to the database you are working with. This is essential for interacting with different databases and vector stores that require structured queries for more efficient document retrieval.
Check which vector databases support filtering: https://superlinked.com/vector-db-comparison
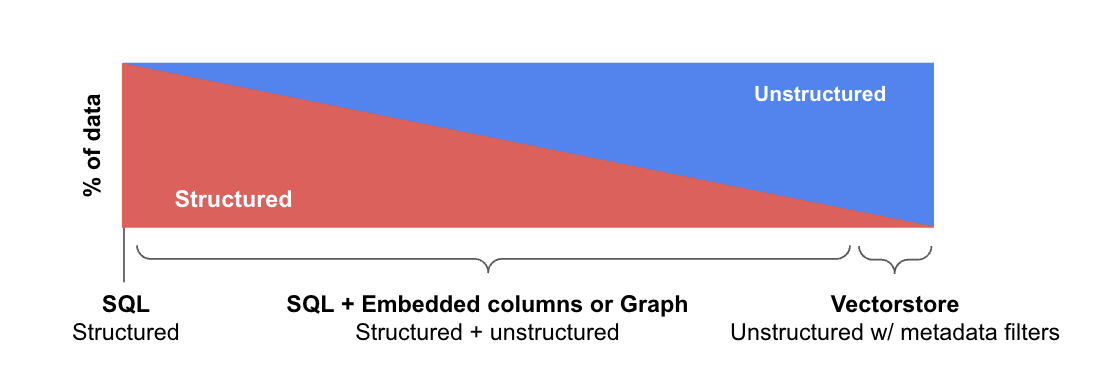
Data can be structured, unstructured or semi-structured (see demo below). This requires LLMs to have capability of query construction.
| Examples | Data Source | References |
|---|---|---|
| Text-to-metadata-filter | VectorStore | Docs |
| Text-to-SQL | SQL DB | Docs; Blog; Blog |
| Text-to-SQL + Semantic | PGVector supported SQL DB | Cookbook |
| Text-to-Cypher | Graph DB | Blog; Blog |
Self-query retriever
A self-querying retriever is one that, as the name suggests, has the ability to query itself. Specifically, given any natural language query, the retriever uses a query-constructing LLM chain to write a structured query (usually in JSON) and then applies that structured query to its underlying VectorStore. This allows the retriever to not only use the user-input query for semantic similarity comparison with the contents of stored documents but to also extract filters from the user query on the metadata of stored documents and to execute those filters.
LangChain Docs:
(v0.2): How to do “self-querying” retrieval
(v0.1): Self-querying
Integration: Components -> Retrievers -> Self-querying retrievers -> Qdrant
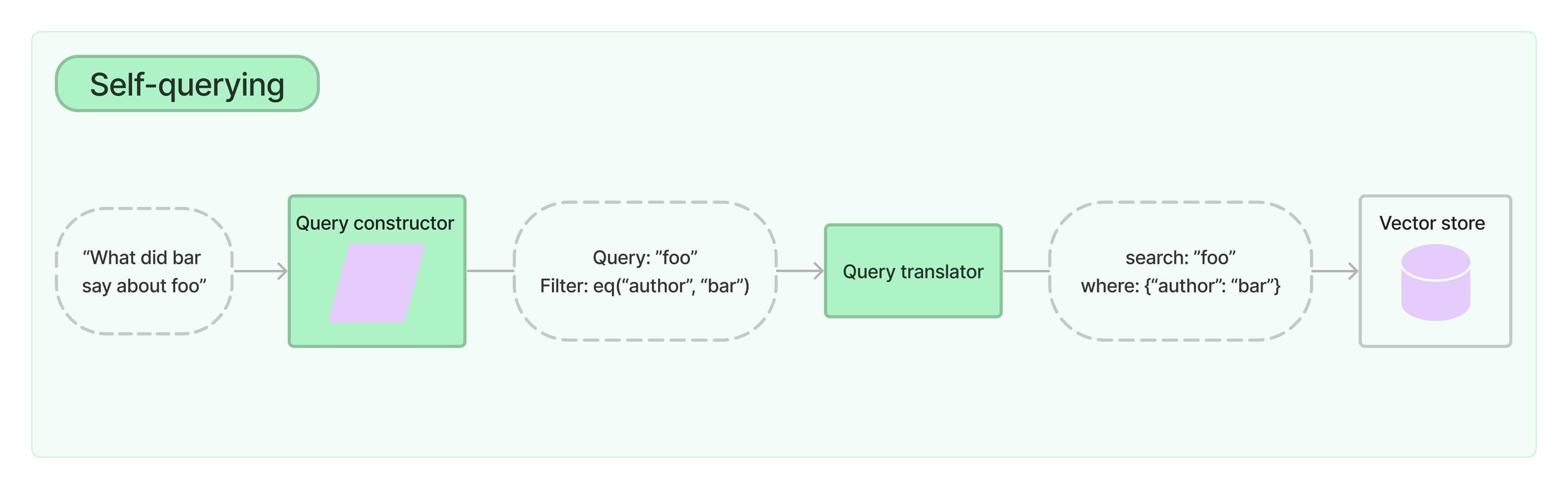
Text-to-metadata-filter: VectorStores equipped with metadata filtering enable structured queries to filter embedded unstructured documents.
Prompt templates and output parsers
Prompt analysis and prompt template: converting user’s query to filtering conditions
When constructing queries, the system uses a specific JSON format to organize the query and filters. The prompt is designed to create structured queries that can be applied to a document database or vector store. The queries consist of two main components:
- Query: The natural language query string that is used to match the document content.
- Filter: Logical conditions used to filter the documents based on specific metadata attributes.
Comparison Operations
Comparison operators (
comp) are used to compare attributes (like year, name, time, product, or team) in the document with specific values provided by the user. Here are the comparison operators:- eq: Equals (e.g.,
eq("team", "TSE")matches documents where the team is “TSE”). - ne: Not equal (e.g.,
ne("name","Ashley")matches documents where the year is not 2022). - gt: Greater than (e.g.,
gt("year", 2023)matches documents with a year greater than 2023). - gte: Greater than or equal to (e.g.,
gte("year", 2022)matches documents from the year 2000 or later). - lt: Less than (e.g.,
lt("year", 2021)matches documents created before 2021). - lte: Less than or equal to (e.g.,
lte("time", 13)matches documents with a time length of 13 mins or lower). - contain: Contains (e.g.,
contain("product", "gold")matches documents where the product contains the word “gold”). - like: Similar to or like (used for pattern matching).
- eq: Equals (e.g.,
Logical Operations
Logical operators combine multiple conditions (comparisons) into a single filter:
- and: Logical AND (e.g.,
and(gt("year", 2022), eq("product", "gold"))matches documents created later than year 2022 and are related to gold card product). - or: Logical OR (e.g.,
or(eq("team", "TS"), eq("team", "TSE"))matches documents that are either TS or TSE). - not: Logical NOT (e.g.,
not(eq("name", "Ashley"))matches documents where Ashley is not the owner).
- and: Logical AND (e.g.,
Output parser: This output parser can be used when you want to return multiple fields or you need the response to be formatted.
LangChain Docs: Structured output parser
Advanced Retrieval Techniques
Vector Store-Backed Retriever: A retriever that uses a vector database to store document embeddings and retrieve documents based on their proximity to the query embedding.
Fusion Retrieval or hybrid search: Combining multiple retrieval strategies (semantic similarity retrieval; keywords retrieval) to obtain a more diverse set of results.
LangChain Docs:
v0.2: How to combine results from multiple retrievers
v0.1: Ensemble Retriever
API: EnsembleRetriever
Code: EnsembleRetriever
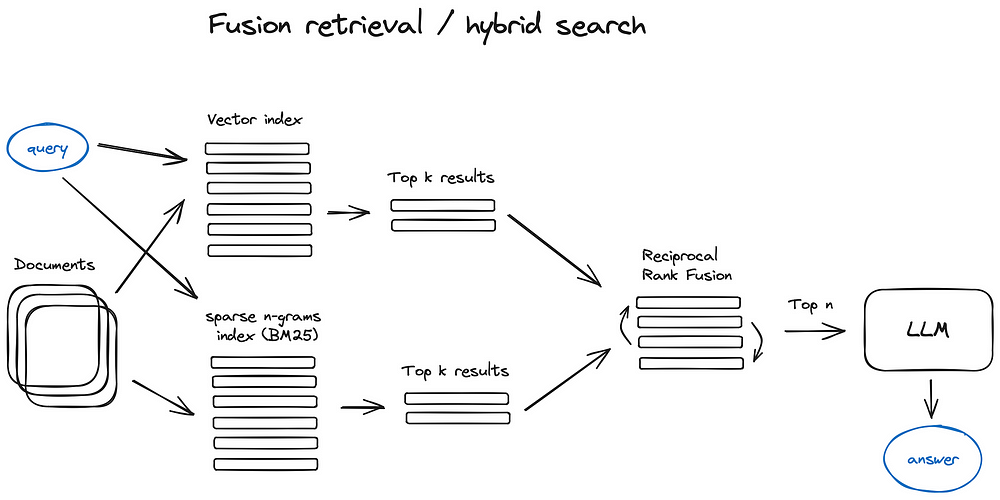
The EnsembleRetriever is a retrieval strategy that enhances retrieval performance by combining multiple retrievers. This approach leverages the strengths of different types of retrievers to compensate for each other’s weaknesses. A common example is combining a Sparse Retriever (e.g., BM25, which performs keyword-based retrieval) with a Dense Retriever (which performs semantic similarity retrieval based on embeddings). This combination works because sparse and dense methods complement each other.
Sparse vs. Dense Representation
- Sparse Representation:
- High-dimensional sparse vectors: Documents and queries are represented as high-dimensional vectors, but most dimensions have zero values. This is typical of traditional information retrieval methods like TF-IDF and BM25.
- Term frequency: Each dimension corresponds to a term, and the vector values represent term frequencies or weights (e.g., TF-IDF weights).
- Sparsity: Since a document or query contains only a small subset of all possible terms, most dimensions in the vector are zero, which makes it “sparse.”
- Dense Representation:
- Low-dimensional dense vectors: Documents and queries are represented as low-dimensional vectors, where most or all dimensions have non-zero values. This representation is typically generated by deep learning models like BERT.
- Semantic embeddings: The vectors capture semantic and contextual information, rather than just term frequency.
- Density: All dimensions in the vector usually have non-zero values, hence “dense.”
Sparse and Dense Retrievers
- Sparse Retriever: The name comes from the fact that most elements in the vector representation of documents and queries are zero. It works well for exact keyword matches but may miss semantically relevant content that uses different vocabulary.
- Dense Retriever: The name reflects that the vector representation has mostly non-zero values. Dense retrievers perform better at capturing the meaning behind the text and finding semantically related content, even when the exact terms differ.
Combining Sparse and Dense Retrievers
By combining sparse and dense retrievers, the EnsembleRetriever can retrieve relevant documents more effectively:
- The Sparse Retriever excels at matching specific keywords or phrases.
- The Dense Retriever is better at capturing the semantic meaning and context, helping to retrieve documents even when exact terms differ.
This combination creates a more robust retrieval system, addressing both lexical matches (through sparse retrieval) and semantic relevance (through dense retrieval).
LangChain Doc: BM25 Retriever
API: BM25Retriever
Code: BM25Retriever
Python Package: rank_bm25
- Sparse Representation:
Sentence Window Retrieval: Retrieving extended context pre and post the relevant context, rather than only retrieving the relevant context, which can reduce information lost.

Parent Document Retrieval: Instead of sending the multiple smaller chunks to the LLM, the system merges them into their larger parent chunk. This allows for more contextualized information to be fed to the LLM, giving it a broader and more coherent set of data to generate an answer.
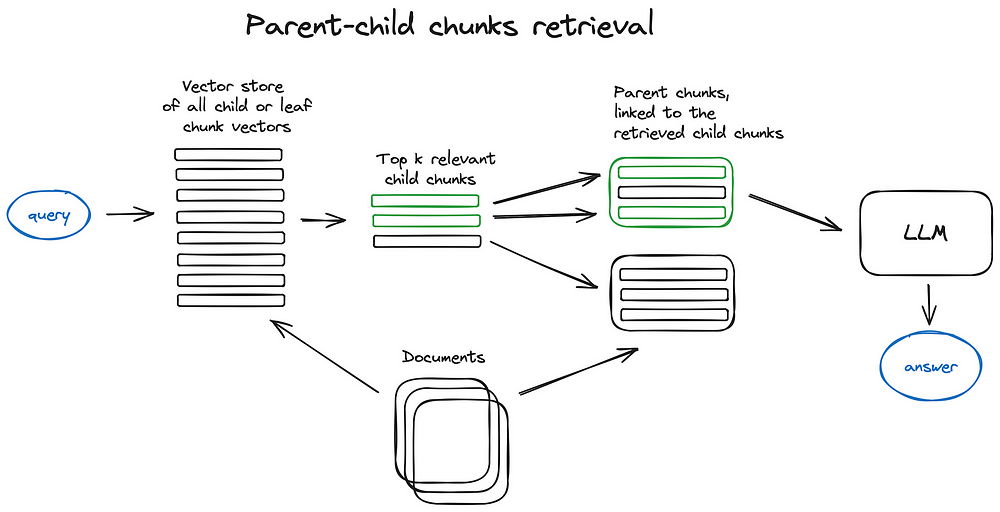
LangChain Doc: Parent Document Retriever
Code: ParentDocumentRetriever
Hierarchical index retrieval: By structuring the search in two layers—summaries for broad filtering and chunks for detailed search—this hierarchical approach increases efficiency, making it easier to find and synthesize relevant information, especially when dealing with large document sets.
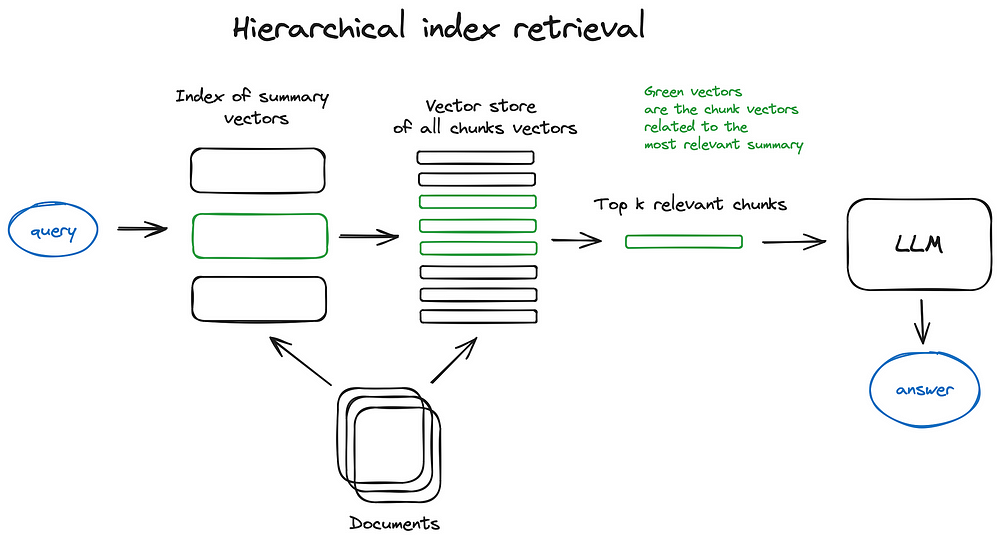
Hypothetical Questions: This technique involves having the language model generate hypothetical questions for each chunk of a document. These hypothetical questions are then embedded, and retrieval is performed based on these question embeddings, improving the relevance of the results.
LangChain Doc: hypothetical-queries
MultiVector Retriever: MultiVector Retriever is a higher level category of parent document retriever, hierarchical index retrieval, and hypothetical questions.
LangChain Doc: MultiVector
Summary: Runnable interface
Post-Retrieval Enhancements
- Re-ranking: After retrieving the documents, the system re-ranks or filters them to ensure that the most relevant results appear at the top.