2024 December - What I Have Read
Substack
the more the AV competition globally heats up, and the more large players invest in the technology, including Tesla, the higher the demand for the Uber platform will become for these AV players.
― Uber Technologies – A brilliant business executing to perfection (Quarterly Update) - Rijnberk InvestInsights [Link]
This article predicts Uber to be a massive beneficiary of the AV / Robotaxi revolution. There indeed is a moat.
Where do LLMs spend their FLOPS? - Artificial Fintelligence [Link]
Theoretical Analysis of LLM FLOPS Allocation
FLOPS Distribution in Decoder Models:
Based on a standard decoder model, FLOPS are allocated as follows for each layer:
6d² for computing Query (Q), Key (K), and Value (V) matrices.
2d² for computing the attention output matrix, using the formula: softmax(Q @ K.T) @ V.
16d² for running the feedforward network (FFN).
This results in a total of 24d² FLOPS per layer.
Percentage-wise:
25% of the time is spent computing QKV.
~8% is spent computing the attention output matrix.
~66% is spent running the FFN.
Attention Mechanism:
While the attention equation itself \(softmax(QK^T/\sqrt{d_{head}})V\) has negligible computational cost (~0.005% for Llama7B) compared to other operations, its impact on memory usage necessitates techniques like KV cache and flash attention.
KV Cache:
The KV cache, essential for efficient attention computation, requires O(T) memory, where T is the number of tokens generated.
The memory size of the KV cache is calculated as 4 * number of layers * d_model bytes.
While the KV cache demands a significant amount of memory, it essentially reuses the same memory space throughout the token generation process.
Modern Architectures:
Architectures like Mistral 7B and Llama2 employ Grouped Query Attention (GQA) and sliding window attention to optimize performance.
GQA reduces the KV cache size by sharing the KV projection across multiple heads. This leads to a linear decrease in memory consumption as the number of KV heads decreases.
Sliding window attention limits the KV cache size to the window size (e.g., 4096 for Llama7B), further controlling memory usage.
Performance-Motivated Architectural Changes
Impact of Model Width and Depth:
Increasing the number of layers linearly scales both the FLOPS and the number of parameters.
Increasing the model width (d_model) quadratically scales the number of parameters and, consequently, the compute requirements.
This is because weight matrices within layers have a size of (d_model, d_model), leading to a quadratic relationship between model width and parameters.
Balancing Latency and Parallelization:
Wider models parallelize better due to the ease of splitting layers across multiple GPUs using tensor parallelism.
Deeper models require sequential computation of layers, hindering parallelization, especially during training.
Therefore, wider models are preferred when low latency is critical.
Empirical Analysis of LLM Performance
The article investigates the memory usage of the KV cache in LLMs, specifically Llama2. The author observes that the actual memory consumed by the model is higher than what the theoretical calculations suggest. Here's how the discrepancy is highlighted:
- Theoretical Calculation: The formula for
calculating the KV cache memory requirement per token is
4 * number of layers * d_modelbytes. In the experiment, the Llama2 model used hasd_modelof 1024 and 8 hidden layers. This means it theoretically needs 32KB of memory per token (4 * 8 * 1024 bytes = 32KB). - Expected Memory Usage: For generating 20 tokens, the model should ideally use 640KB of memory (32KB/token * 20 tokens = 640KB).
- Observed Memory Usage: However, the empirical analysis revealed that the model's memory consumption jumped by ~2.1MB every 20 tokens. This is significantly higher than the expected 640KB.
The author concludes that this discrepancy of about 3x suggests an inefficient implementation of the KV cache in the model being used. The extra overhead could stem from various factors not accounted for in the theoretical calculation, and further investigation would be needed to pinpoint the exact cause.
Transformer inference tricks - Artificial Fintelligence [Link]
KV Cache
- The KV cache is a crucial optimization for decoder models, significantly reducing computation. It exploits the fact that keys and values remain constant for the prompt and each decoded token in subsequent iterations. By caching these values, the computational complexity of sampling becomes linear instead of quadratic, enabling decent performance with longer contexts.
- However, it introduces state management complexity, as inference needs to continue for all sequences even if some are completed. The KV cache demands significant memory, proportional to the number of layers, heads, and the embedding dimension. For instance, GPT-3 with 96 layers, 96 heads, and a dimension of 128 requires 2.4M parameters per token, translating to 10GB of memory for a 2048 token context window. This memory requirement is a major challenge for consumer-grade GPUs with limited HBM, like the 4090.
Speculative Decoding
- Speculative decoding leverages excess compute capacity, particularly in local inference settings. It utilizes two models: a small, fast “draft” model and a large, slow model. The smaller model quickly makes multiple inferences, guessing the large model’s predictions, while the larger model verifies these guesses in parallel. This effectively reduces the sequential cost of generating a sequence to that of the smaller model.
- However, it requires training and storing both models, and performance is limited by the smaller model’s prediction accuracy. HuggingFace reports a typical doubling of decoding rate using this technique.
- Newer techniques like Jacobi decoding and lookahead decoding aim to improve upon speculative decoding by generating n-grams and recursively matching them, potentially achieving latency improvements without requiring a draft model.
Effective Sparsity
- Sparsity in transformer activations arises from the softmax operation in the attention mechanism and ReLU activations in MLPs, leading to many zero values. Utilizing this sparsity can be challenging, with limited support in mainstream tensor programs.
- One optimization involves skipping computations for zero activations, feasible in custom implementations like Llama.cpp. However, the effectiveness of this approach diminishes exponentially with batch size due to the random distribution of sparsity across tokens.
- Therefore, leveraging sparsity is most effective for batch size 1, although speculative decoding might be more beneficial in such scenarios.
Quantization
- Quantization reduces the precision of model weights and activations, potentially saving memory and increasing inference speed. Research suggests that quantization to 4 bits or more results in negligible performance degradation. The k-bit inference scaling laws paper demonstrates that reducing precision allows for using a larger model with the same memory footprint and potentially achieving better performance.
- However, using lower precision formats may lack native support in hardware and could be unstable in production environments. FP8 offers a good balance between performance and support, being the lowest precision format natively supported by modern accelerators. Int8 is another option, easier to implement with tools like PyTorch, though it lacks the performance advantages of FP8.
- Libraries like bitsandbytes facilitate quantization, offering tools and APIs for implementation.
Top 10 China's AI Stories in 2024: A Year-End Review - Recode China AI [Link]
China's AI landscape is rapidly catching up to the US, with multiple models now reaching similar performance benchmarks as GPT-4 and advancements in areas like video generation, robotics, and autonomous driving.
Several AI-powered apps have emerged in China, with ByteDance's Doubao leading in popularity domestically and MiniMax's Talkie gaining traction internationally, though China has yet to produce a "killer app" with at least 100 million daily active users.
A number of Chinese AI startups have emerged since ChatGPT's debut, backed by significant capital, but they now face strong competition from tech giants.
Chinese open-source LLMs have made substantial global progress, with Alibaba’s Qwen series being the most downloaded on Hugging Face.
Chinese AI video generators have surged ahead due to the delayed release of Sora, with platforms like Kuaishou’s Kling and MiniMax’s Hailuo offering competitive features.
An LLM API price war has been ignited by major Chinese tech companies, with significant price reductions for developers and SMEs.
China's semiconductor industry faces challenges due to US restrictions but is also making strides in self-sufficiency, with companies like Huawei pushing forward on competitive AI chips.
China's robotaxi industry is gaining momentum, with Baidu's Apollo Go expanding its fleet and other self-driving startups completing IPOs.
OpenAI and Microsoft have tightened AI access in China, prompting Chinese AI companies to offer alternatives and accelerating the development of homegrown models.
China is seeing a robotics boom with rapid innovation in humanoid and other types of robots, though challenges remain in complex tasks and high production costs.
AI resurrection is becoming increasingly accessible, raising ethical and legal questions as companies offer services to create digital replicas of the deceased.
Finetuning LLM Judges for Evaluation - Deep (Learning) Focus [Link]
This article discusses the challenges of evaluating LLMs and how finetuning specialized LLM judges can improve the evaluation process. Here's how the logic of the article flows:
The article notes that while human evaluation is the most reliable method, it is also expensive, time-consuming, and not scalable. This creates a need for efficient ways to test LLM capabilities.
There are two primary evaluation approaches: human evaluation and automatic metrics.
- Human evaluation is considered the "definitive source of truth" but is recognized as noisy, subjective and prone to bias.
- Automatic metrics are used to speed up model development, but they are imperfect proxies for human opinions. The article further divides automatic metrics into two categories: traditional metrics and model-based evaluation.
- Traditional metrics like ROUGE and BLEU are reference-based, comparing LLM outputs to "golden" answers, and are less effective for modern LLMs which are open-ended and can produce many valid responses.
- LLM-as-a-Judge is introduced as a model-based approach, using a powerful LLM to evaluate another LLM's output. This method is effective, easy to implement, and can handle open-ended tasks.
While effective, LLM-as-a-Judge has limitations, including a lack of transparency, security concerns, cost, and a lack of specialization for domain-specific evaluations. The article argues that these limitations can be addressed by training specialized LLM judges.
- Meta-evaluation involves assessing the performance of the LLM judge by comparing its output to high-quality human evaluation data.
- Early research on finetuned LLM judges were created as open source replacements for proprietary LLMs. The original LLM-as-a-Judge paper also explored finetuning, and found that a finetuned Vicuna-13B model showed potential. The need for finetuning is further justified because proprietary LLMs can be expensive, lack control or transparency, and because open source models are becoming more capable. The article discusses how a Vicuna-13B model was improved by finetuning on human votes from Chatbot Arena, though it still fell short of GPT-4 performance.
- Several examples of finetuned LLM judges:
- PandaLM: This model is designed to identify the best model among a set, particularly useful for hyperparameter tuning. It is trained on a dataset of over 300K examples with instructions, inputs, paired responses, evaluation results and rationales. PandaLM is effective in specialized domains like law and biology.
- JudgeLM: This model focuses on the factors that contribute most to the quality of a judge model, such as data quality and diversity, base model size, bias, and generalization. JudgeLM uses a high-quality, diverse dataset and is trained to mitigate bias, including positional, knowledge, and format biases.
- Auto-J: This model is designed for domain-specific grading, with an emphasis on providing high-quality, structured explanations. It is trained on real-world queries and responses and can perform both pairwise and direct assessment scoring.
- Other related research using LLMs for critiques, verification, and generating synthetic training data.
Prometheus is a key development in finetuned LLM judges, capable of fine-grained, domain-specific evaluation. It is trained to ingest custom scoring rubrics as input.
- The Prometheus model uses the Feedback Collection dataset, which includes instructions, responses, rubrics, reference answers, rationales, and scores. It is trained to sequentially provide feedback and then score the response using a supervised finetuning (SFT) strategy.
- Prometheus 2 is introduced as an extension that can handle both direct assessment and pairwise scoring. It is trained on both the Feedback Collection and the Preference Collection, and uses a linear model merging approach to combine models trained for the two scoring formats.
- Prometheus-Vision extends the Prometheus concept to Vision-Language Models (VLMs). It uses a dataset called the Perception Collection, which includes images, instructions, responses, rubrics and reference answers.
Other types of finetuned judges, including:
- Self-rewarding LLMs, which use the LLM itself to provide its own rewards and feedback.
- LLM-as-a-Meta-Judge, which allows the LLM judge to self-improve.
- Self-taught evaluators, which train evaluators without human preference data.
- Foundational Large Autorater Models (FLAMe), which are trained on a massive amount of human preference data and generalize well to other tasks.
- Direct judgement preference optimization, which uses preference optimization to create more advanced evaluation capabilities.
A generic framework based on the Prometheus model for creating a finetuned LLM judge. The steps include:
- Solidifying evaluation criteria.
- Preparing a high-quality dataset.
- Using synthetic data.
- Focusing on the rationales for each score.
- Training the model using SFT and meta-evaluating its performance.
E-Commerce Unleashed - App Economy Insights [link]
Highlights discussion points:
Cyber week trends.
"Cyber Week (from Black Friday to Cyber Monday) showcased shifting consumer behaviors and the growing dominance of e-commerce."
Shopify’s acceleration.
Shopify has evolved from a platform for small businesses into a global enabler for merchants, offering tools to scale internationally. Its emphasis on payments, particularly through Shop Pay, has been pivotal, with Shop Pay emerging as a high-conversion checkout option. In Q3, Gross Payment Volume accounted for 62% of Shopify’s Gross Merchandise Volume, marking a 4% year-over-year increase. Additionally, Shopify's partnership with Amazon to integrate Prime benefits directly into Shopify stores represents a strategic move to boost customer loyalty and conversions by leveraging Amazon's trusted fulfillment network and extensive Prime membership base.
Amazon takes on Temu.
Amazon has launched Amazon Haul, a new storefront aimed at attracting budget-conscious shoppers and safeguarding its market position. This initiative is strategically designed to meet the increasing demand for affordable e-commerce solutions.
Walmart’s advertising play.
Walmart is redefining modern retail by merging its extensive physical presence with advanced digital capabilities to create a powerful omnichannel strategy. The company leverages first-party data and its retail media network to maintain a competitive edge.
Walmart Connect integrates online and in-store advertising, allowing brands to engage customers at their preferred shopping points. By utilizing vast first-party data, Walmart delivers targeted and relevant ads, enhancing both advertiser returns and customer satisfaction. The platform is also attracting advertisers from diverse industries, including automotive and financial services.
Walmart’s planned acquisition of Vizio marks its entry into connected TV advertising, broadening Walmart Connect’s reach into households through smart TVs and enhancing inventory visibility and supply chain integration through improved data capabilities. This positions Walmart as a leader in omnichannel retail and advertising.
AI: The quiet game changer.
AI played a transformative role during Cyber Week, enhancing the shopping experience across various dimensions. Hyper-personalized shopping was driven by AI recommendation engines, which anticipated consumer needs and boosted conversions, exemplified by features like Amazon’s “frequently bought together.” Generative AI tools, such as chatbots, simplified product discovery during the busy sales period, with innovations like Amazon Q offering AI-generated review summaries to streamline decision-making.
AI also optimized logistics through demand forecasting, ensuring products remained in stock and reducing shipping delays. In payments, real-time AI fraud detection provided secure checkouts on platforms like Walmart and Shopify. Additionally, AI tools like Shopify’s Sidekick and Magic enhanced product descriptions, SEO strategies, and customer support, further elevating the e-commerce experience. These advancements underscored AI's critical role in reshaping retail during one of the busiest shopping weeks of the year.
AI presents new challenges for incumbents but also drives significant innovation and growth.
― Salesforce: The Agent Wave - App Economy Insights [Link]
The company’s autonomous AI platform - Agentforce - was introduced in Sep 2024 and launched in late Oct. Agentforce enables businesses to deploy AI agents for tasks such as sales, marketing, and customer support. This marks a pivotal step in Salesforce’s platform strategy, with far-reaching implications. CEO Marc Benioff views Agentforce as transformative, positioning it at the core of a shift toward “agent-first companies.” In this model, AI not only assists humans but fundamentally redefines business operations by automating processes and enhancing productivity.
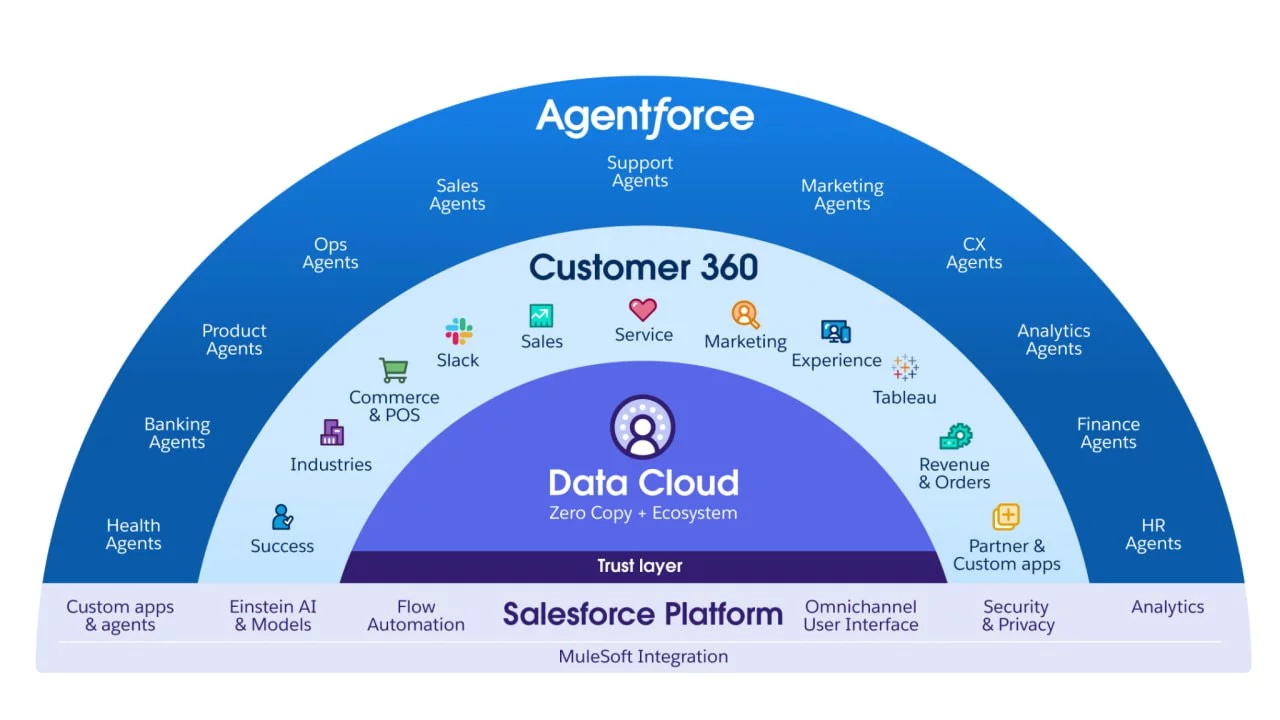
What to watch:
- Salesforce recently completed its acquisition of Own and Zoomin, reinforcing its Data Cloud capabilities.
- Salesforce Ventures announced a new \(\$500\) million AI fund, targeting high-profile AI startups like Anthropic, Mistral, and Cohere, supporting Salesforce’s efforts to remain at the forefront of enterprise AI.
- Clara Shih, CEO of Salesforce AI left Salesforce to set up a new Business AI group at Meta, aiming to build AI tools for businesses of all sizes. Shih’s departure highlights the intensity of the AI talent war, which will be a fascinating layer to watch in the coming year.
OpenAI's o1 using "search" was a PSYOP - Interconnects [Link]
The article primarily argues that OpenAI's o1 model does not use explicit search at test time, and its apparent search capabilities are a result of reinforcement learning (RL) during training. The author argues against the idea that o1 uses online search at test time or intermediate rewards during training. The article posits that the "suspects" are reduced to "Guess + Check" and "Learning to Correct". They uses the test-time compute plot, and the training process, as key points in their argument to show how o1 can achieve high performance using RL with controlled training data and no explicit search during inference.
One major source of this idea is Sasha Rush's lecture on Test Time Scaling (o1).
Insurance companies aren't the main villain of the U.S. health system - Nahpinion [Link]
This article argues that health insurance companies are not the primary cause of high healthcare costs in the United States12. Instead, the article argues that the excessive prices charged by healthcare providers are the main reason for the high cost of healthcare. The article suggests that focusing anger on insurance companies is "shooting the messenger," and the solution is to reduce costs within the medical system itself, such as having the government negotiate lower prices with providers.
Evidences are: insurance companies have low profit margins, spend much more on medical costs than they make in profit. Americans pay a smaller percentage of their health costs out of pocket than people in most other rich countries. This suggests that US health insurers are paying a higher percentage of costs than government insurance systems in other countries. The cost of healthcare provision in the U.S. is too high. The actual people charging high prices are the providers themselves, such as hospitals, pharmaceutical companies, and system. They outsource the actual collection of these fees to insurance companies.
15 Times to use AI, and 5 Not to - One Useful Thing [Link]
When to Use AI:
Use AI for tasks that require generating a high quantity of ideas, such as in brainstorming sessions.
AI is useful when you are an expert and can quickly judge the quality of its output.
AI can summarize large amounts of information where minor errors are acceptable.
Use AI for translating information between different formats or audiences.
AI can help you overcome creative blocks by providing multiple options to move forward.
Use AI when it is known to be better than any available human option, and its errors won't cause significant problems.
Use AI as a companion when reading to get help with context and details. (very helpful to me)
AI can provide a variety of solutions, allowing you to curate the best ones.
AI is helpful for tasks where research has proven it to be effective, like coding.
Use AI to get a first look at how different audiences might react to your work.
AI can act as a competent co-founder for entrepreneurial ventures.
Use AI to get a specific perspective, such as reactions from fictional personas.
AI can help with tasks that are ritualistic and have lost their purpose.
Use AI to get a second opinion by comparing its conclusions with yours.
Use AI when it can perform a task better than humans.
When Not to Use AI:
Avoid AI when you need to learn and synthesize new ideas, as it is not the same as reading and thinking yourself.
Do not use AI when very high accuracy is essential because AI errors can be very plausible and hard to spot.
Avoid AI if you do not understand its failure modes, such as hallucinations or persuasiveness.
Do not use AI when the struggle with a topic is necessary for success and learning.
Avoid AI when it is bad at a specific task.
Oracle : The 4th Hyperscaler? - App Economy Insights [Link]
Google released the first version of its Gemini 2.0 family of artificial intelligence models on December 11th, 2024. Including its Chrome browser automation product called Mariner.
Project Astra and Mariner along with NotebookLM remain very intriguing AI products by Google in 2025.
Gemini 2 and the rise of multi-modal AI - AI Supremacy [Link]
Incredible.
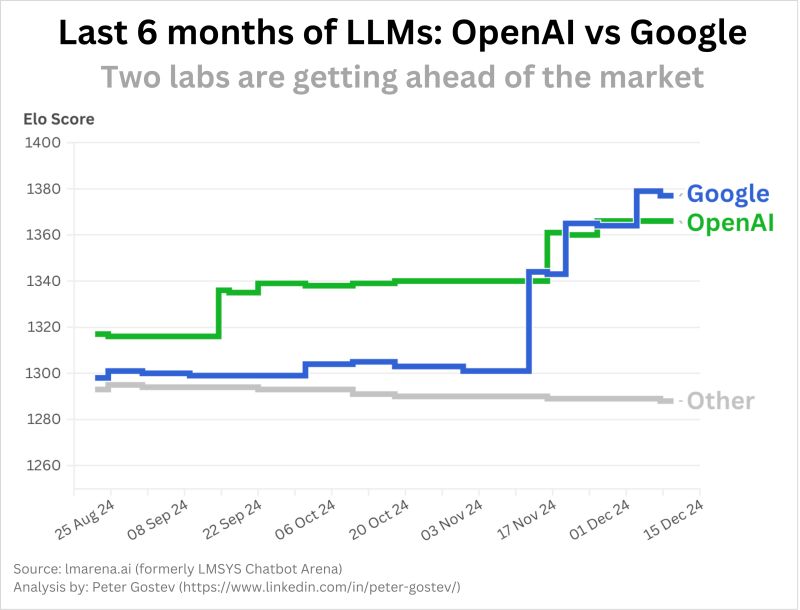
Figure source: Peter Gostev on Linkedin
Palantir Unclassified! Equity Research! - Global Equity Briefing [Link]
Palantir is a software company that provides tools for analyzing large datasets, which enable users to make better decisions. Founded in the early 2000s, Palantir initially offered services to government agencies, including the US intelligence community, to combat terrorism. The CIA was one of their first investors. Palantir's software is also used by corporations to improve operations and decision-making.
Business Model
Palantir operates as a Software as a Service (SaaS) company, offering a suite of customizable products for which clients pay a licensing fee. The company has two operating segments: government and commercial.
Government Sales: Palantir provides services to government institutions, recognizing a gap in the market due to many Silicon Valley companies not wanting to work with governments. These contracts are often long-term, providing predictable revenue streams. The company benefits from the transparency of government information, and it is easier for them to predict needs and market their software.
Commercial Sales: Palantir's solutions are used across many industries by various employees from production line workers to CEOs. The use cases for Palantir software in the commercial sector are extensive.
Customer Acquisition: Palantir targets large organizations with complex problems, which increases their competitive advantage. Solving difficult problems first earns customer trust.
Products: Gotham, Foundry, Apollo, and AIP.
- Gotham: It is a government-focused platform that allows users to analyze large datasets to make better decisions and find hidden connections, with the goal of improving operations and decision-making.
- Foundry: This is a commercial platform that allows large and complex companies to integrate, visualize, and analyze their data to optimize their operations and value chain.
- Apollo: This is a platform for continuous software deployment, enabling secure and seamless delivery of software across various environments for Palantir's clients.
- AIP: Palantir's newest offering, it is a platform for organizations to create customized AI tools using their own data, providing accurate and detailed answers to specific questions.
Opportunities
Palantir can benefit from the growing demand for digital twins, which are exact digital replicas of real-world items used for integration, monitoring, simulation, and maintenance. The digital twin market is projected to grow significantly. Palantir is positioned to benefit from the AI revolution with its AIP platform, and its other products also use AI. The global AI market is expected to reach \(\$1.84\) trillion by 2030. Palantir is developing industry-specific operating systems, like Skywise for the airline industry. These operating systems are sticky and offer significant revenue opportunities. The healthcare industry could be a large market for such systems. Palantir's commercial sector is growing, and there are significant opportunities for international expansion.
Is AI hitting a wall? - Strange Loop Canon [Link]
Arguments that suggest AI progress is hitting a wall include the observation that pre-training scaling has plateaued, meaning simply increasing model size and data may not yield the same improvements as before. Also, current evaluation benchmarks may be saturated, failing to assess deeper work, since they are based on human tests or simple recall. Current AI models struggle with real-world tasks due to issues like hallucination and a lack of creative planning, even if they appear human-level in individual evaluations. Finally, the visible effects of scaling are limited, with reduced cross-entropy loss not translating to significant improvements for observers.
Conversely, arguments against AI progress hitting a wall emphasize the presence of large amounts of unused data, including various types like conversations and video data. The use of synthetic data can enhance learning by converting existing data into different formats and testing it against real-world scenarios. AI models are now being taught reasoning, enabling them to "think for longer" and improving performance in areas requiring clear thought processes. Additionally, there is the possibility of exploring new S-curves or scaling laws. New models are also capable of expert-level work that is not captured by current benchmarks, potentially speeding up scientific research. Finally, AI models can now interact with digital systems, and are becoming more aware of the world.
Our Healthcare System, a Reign of Terror - Freddie deBoer [Link]
An Assassin Showed Just How Angry America Really Is - BIG by Matt Stoller [Link]
OpenAI o3 Model Is a Message From the Future: Update All You Think You Know About AI - The Algorithmic Bridge [Link]
OpenAI's o3: The grand finale of AI in 2024 - Interconnects [Link]
Key performance points:
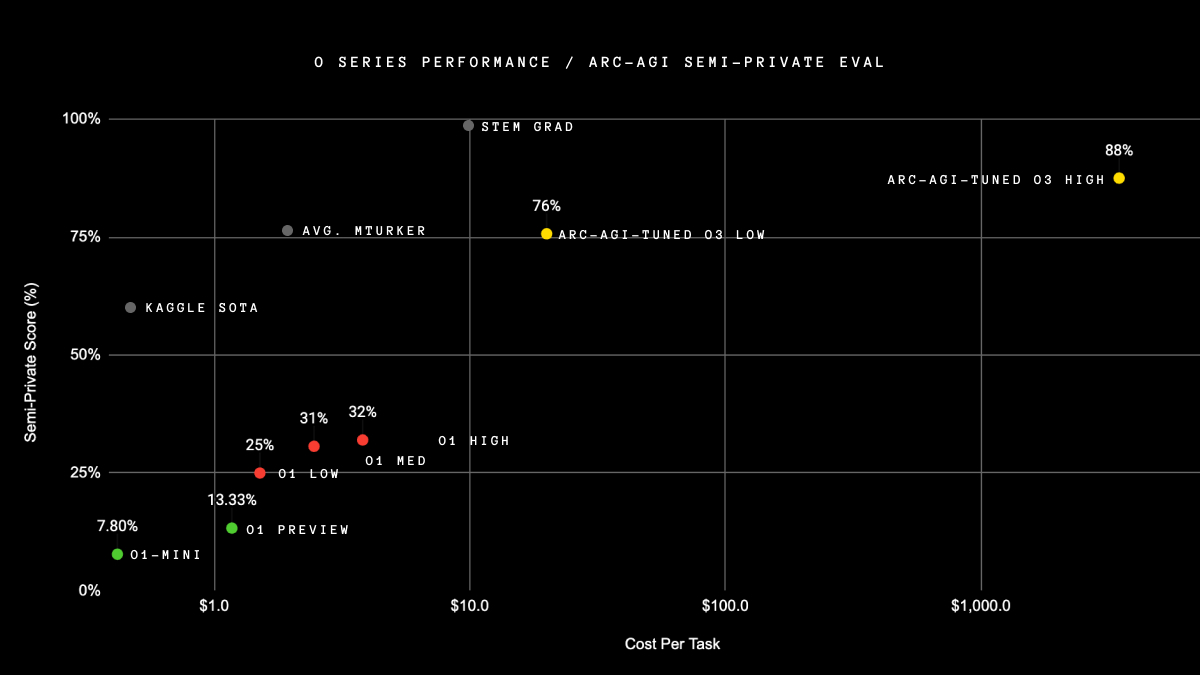
- ARC AGI Prize: o3 is the first model to surpass the 85% threshold for completing the ARC AGI prize on the public set, though it exceeded cost constraints. It achieved 87% accuracy on the public set with high compute, and 76% with low compute. For context, prior to o1-class models, OpenAI’s best model, GPT-4o, only achieved 5% accuracy. The ARC AGI challenge is designed to evaluate human-like general fluid intelligence.
- Frontier Math Benchmark: o3 demonstrates a substantial improvement on the Frontier Math benchmark, increasing performance from 2% to 25%. This benchmark is considered extremely challenging, with one Fields Medalist stating that the problems "will resist AIs for several years at least".
- Coding Benchmarks: o3 has made significant improvements on leading coding benchmarks such as SWE-Bench-Verified, achieving a score of 71.7%. On the Codeforces competition coding site, o3 achieved a score of 2727 with consensus voting, placing it at the International Grandmaster level and approximately in the top 200 of competitive human coders.
- Reasoning Capabilities: o3 represents a major advancement in reasoning evaluations, signaling that the industry is moving beyond pretraining on internet text. It is expected to accelerate the rate of progress in AI research.
- Inference and Cost: o3 was tested with two levels of compute with different sample sizes: a high-efficiency configuration with a sample size of 6, and a low-efficiency configuration with a sample size of 1024 which used 172 times more compute. The cost of running o3 at the higher level of compute was approximately \(\$5000\) per query. It is speculated that the core mechanism of o3 involves natural language program search and execution within token space, searching over Chains of Thought (CoTs).
- Availability: The o3 model, including the o3-mini version, is expected to be available to the general public in late January 2025. The o3-mini is expected to be more impactful for the general public due to its lower cost, while still outperforming o1.
o3, AGI, the art of the demo, and what you can expect in 2025 - Marcus on AI [Link]
o3 “ARC AGI” postmortem megathread: why things got heated, what went wrong, and what it all means - Marcus on AI [Link]
Gary Marcus critiques OpenAI's new model o3, arguing that its impressive demo, while showcasing advancements in math and coding, was carefully curated and lacks broader application.
- The public did not get to try the system, and it was not vetted by the scientific community. OpenAI chose what to highlight about o3. Marcus argues that until many people get to try o3 on different tasks, its reliability should not be assumed.
- The o3 demo primarily focused on math, coding, and IQ-like puzzles, with no evidence that it can work reliably in open-ended domains. It was not tested on problems where massive data augmentation was not possible. The demo did not address the most important question about the system's capabilities in open-ended domains.
- The o3 system is incredibly expensive. One estimate suggests that each call to the system might cost $1000. Even if the cost is reduced, it might still not be as good or as versatile as top STEM graduates.
- The o3's performance on the ARC-AGI test was misleading. The test is at most a necessary, but not sufficient, condition for AGI, and does not address important areas such as factuality, compositionality, and common sense.
- The core problem of neural networks generalizing better "within distribution" than "outside distribution" has not been solved.
Note to Our Energy Sucking Overlords - Michael Spencer [Link]
The rapid growth of AI is causing a surge in demand for data centers, which in turn are becoming major consumers of electricity. The energy needs of AI are growing so large that tech companies are seeking reliable power sources beyond renewable energy. The rising energy consumption of AI infrastructure will likely result in higher energy prices, potentially creating competition between Big Tech and the communities where they build data centers. To meet their energy needs, major technology companies are becoming more involved in the energy sector, including investments in nuclear and natural gas plants. The current trajectory of AI infrastructure expansion and energy consumption is unsustainable and could lead to significant challenges for society. The US is building data centers abroad in Europe and Asia, thereby maintaining their power and also acquiring cheaper labor.
Summary of statistics:
- Energy Consumption of AI tasks: A single task on the ARC-AGI benchmark using OpenAI's o3 model consumes approximately 1,785 kWh of energy, which is equivalent to the electricity used by an average U.S. household in two months. This task also generates 684 kg CO₂e, which is equivalent to the carbon emissions from more than 5 full tanks of gas.
- Investments in AI Infrastructure: In 2024, major players like Amazon, Microsoft, and Alphabet spent over \(\$240\) billion on AI-related infrastructure. In 2025, Amazon, Google, Meta, and Microsoft are expected to spend \(\$300\) billion in capital expenditures.
- Data Center Electricity Consumption: Global data center electricity consumption is expected to more than double between 2023 and 2028. The IDC expects consumption to reach 857 Terawatt hours (TWh) in 2028.
- US Data Center Energy Usage: U.S. data centers could use 6.7 to 12% of all energy demand nationwide by 2028. In 2023, data centers used 4.4% of total US power consumption, which is projected to rise to as high as 12% by 2028. This is a spike of more than threefold in the next four years.
- Data Center Locations and Power:
- Northern Virginia has over 300 data centers with approximately 3,945 megawatts of commissioned power.
- The Dallas region has 150 data centers.
- Silicon Valley has over 160 data centers.
- Phoenix has over 100 data centers with around 1,380 megawatts of power.
- Chicago has more than 110 data centers.
- Data Center Projects:
- OpenAI plans to construct massive 5-gigawatt (GW) data centers across the US.
- Oklo will build small modular reactors (SMR) by 2044 to generate 12 gigawatts of electricity for data centers.
- Meta announced a \(\$10\) billion development for a 4 million sq ft, 2 GW data center campus in Louisiana.
- Entergy is proposing to develop a 1.5GW natural gas plant in Louisiana to power a data center.
- Amazon Web Services (AWS) plans to invest \(\$11\) billion in a new data center campus in Northern Indiana.
- Generative AI Market: The generative AI market was valued at \(\$6\) billion in 2023 and could reach \(\$59\) billion in 2028.
- Increased US power demand: Data centers are one of the key reasons US power demand is expected to jump 16% over the next five years.
- Cost of Electricity for Data Centers: Electricity is the largest ongoing expense for data center operators, accounting for 46% of total spending for enterprise data centers and 60% for service provider data centers.
- The potential for data centers to consume as much energy as entire industrialized economies: By 2030, US data centers could consume as much electricity as some entire industrialized economies.
- Big Oil's Role: Big oil companies like ExxonMobil and Chevron are moving into the AI datacenter energy market. Exxon plans to build a natural gas plant to power a data center, and estimates that decarbonizing AI data centers could represent up to 20% of its total addressable market for carbon capture and storage by 2050.
What are the checks and balances on the power of Elon Musk? - Noahpinion [Link]
The article examines the significant influence of Elon Musk on U.S. politics, particularly his role in derailing a Congressional spending bill. It explores whether Musk's actions represent a threat to democratic processes, considering his control over X (formerly Twitter) and SpaceX. The author presents contrasting views of Musk—"Real Elon" versus "Evil Elon"—highlighting the uncertainty surrounding his motives and the lack of institutional checks on his power. The piece concludes by suggesting that public opinion ultimately holds sway over Musk's influence, though the potential for a powerful backlash remains to be seen.
Is AI progress slowing down? - AI SHAKE OIL [Link]
The authors argue that the recent shift away from model scaling towards inference scaling is not necessarily indicative of a slowdown, but rather a change in approach. They caution against over-reliance on industry insiders' predictions due to their inherent biases, emphasizing that progress is less predictable and more dependent on algorithmic innovation than previously assumed. Furthermore, the essay highlights the significant lag between capability advancements and real-world applications, suggesting that the focus should shift towards product development and user adoption rather than solely on model capabilities. Finally, the authors offer a more nuanced perspective on the current state of AI progress, acknowledging the potential of inference scaling while emphasizing the importance of considering broader factors beyond pure technological advancement.
The Critical AI Report, December 2024 Edition - Blood in the Machine [Link]
Gen AI's actual impact on workers so far:
Waymo: Rideshare Revolution - App Economy Insights [Link]
Manufacturing is a war now - Noahpinion [Link]
The article argues that China's dominance in manufacturing, particularly in crucial areas like drone production and batteries, poses a significant threat to the United States and its allies.
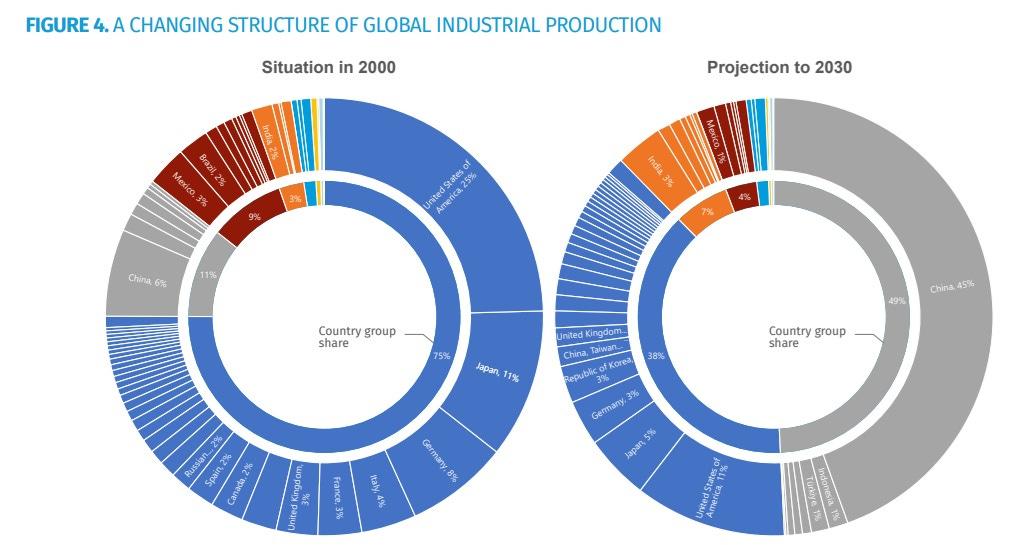
Source: https://mipforum.org/wp-content/uploads/2024/11/MIPF-Conference-Paper-FINAL-WEB.pdf
Articles and Blogs
Meet Willow, our state-of-the-art quantum chip - Google Research [Link]
Google has developed a new quantum chip called Willow, which significantly reduces errors as it scales up, a major breakthrough in quantum error correction. Willow also performed a computation in under five minutes that would take a supercomputer 10 septillion years, demonstrating its potential for solving complex problems beyond the reach of classical computers. This achievement marks a significant step towards building commercially relevant quantum computers that can revolutionize fields like medicine, energy, and AI.
Quantum Computing Roadmap:
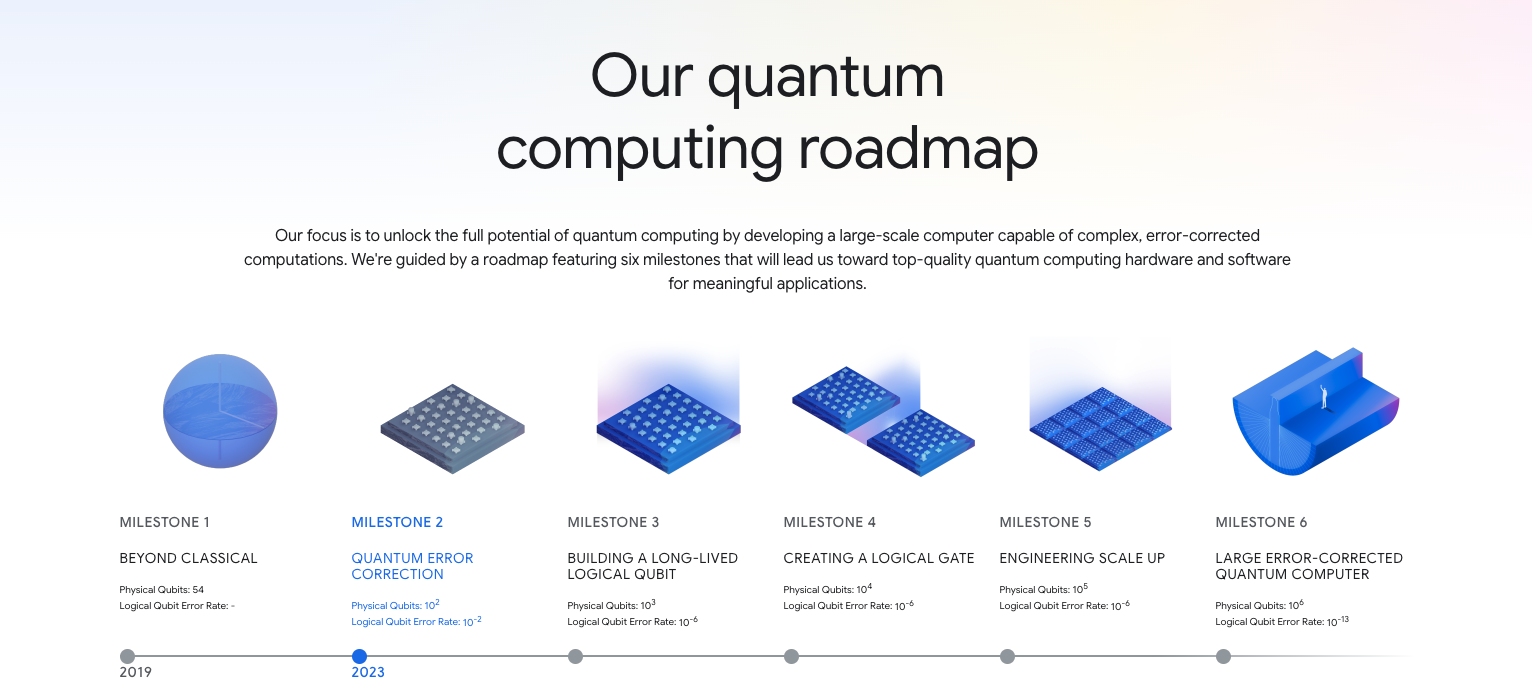
Terms to keep in mind:
- Willow: Google's latest 105-qubit superconducting processor, which is the first to demonstrate exponential error suppression with increasing surface code size.
- Below Threshold: A milestone in quantum computing where the error rate decreases as the number of qubits increases, demonstrating effective error correction.
- Logical Qubit: A fault-tolerant qubit created from multiple physical qubits using error correction techniques, providing a more stable and reliable unit of computation.
- Random Circuit Sampling (RCS): A benchmark test that assesses the ability of a quantum computer to perform computations beyond the capabilities of classical computers.
- T1 Time: A measure of how long a qubit can maintain its quantum state before decoherence sets in.
- Quantum Algorithms: Algorithms specifically designed to be executed on quantum computers, leveraging quantum phenomena to solve problems more efficiently.
Making quantum error correction work - Google Research [Link]
The ultimate vision of them is to build a large-scale, fault-tolerant quantum computer that can run complex quantum algorithms and unlock the potential of quantum computing for scientific discovery and various applications.
Terms to keep in mind:
- Repetition codes: A type of quantum error correction that focuses solely on bitflip errors and achieves lower encoded error rates.
- Quantum error decoder: Classical software that processes measurement information from the quantum computer to identify and correct errors.
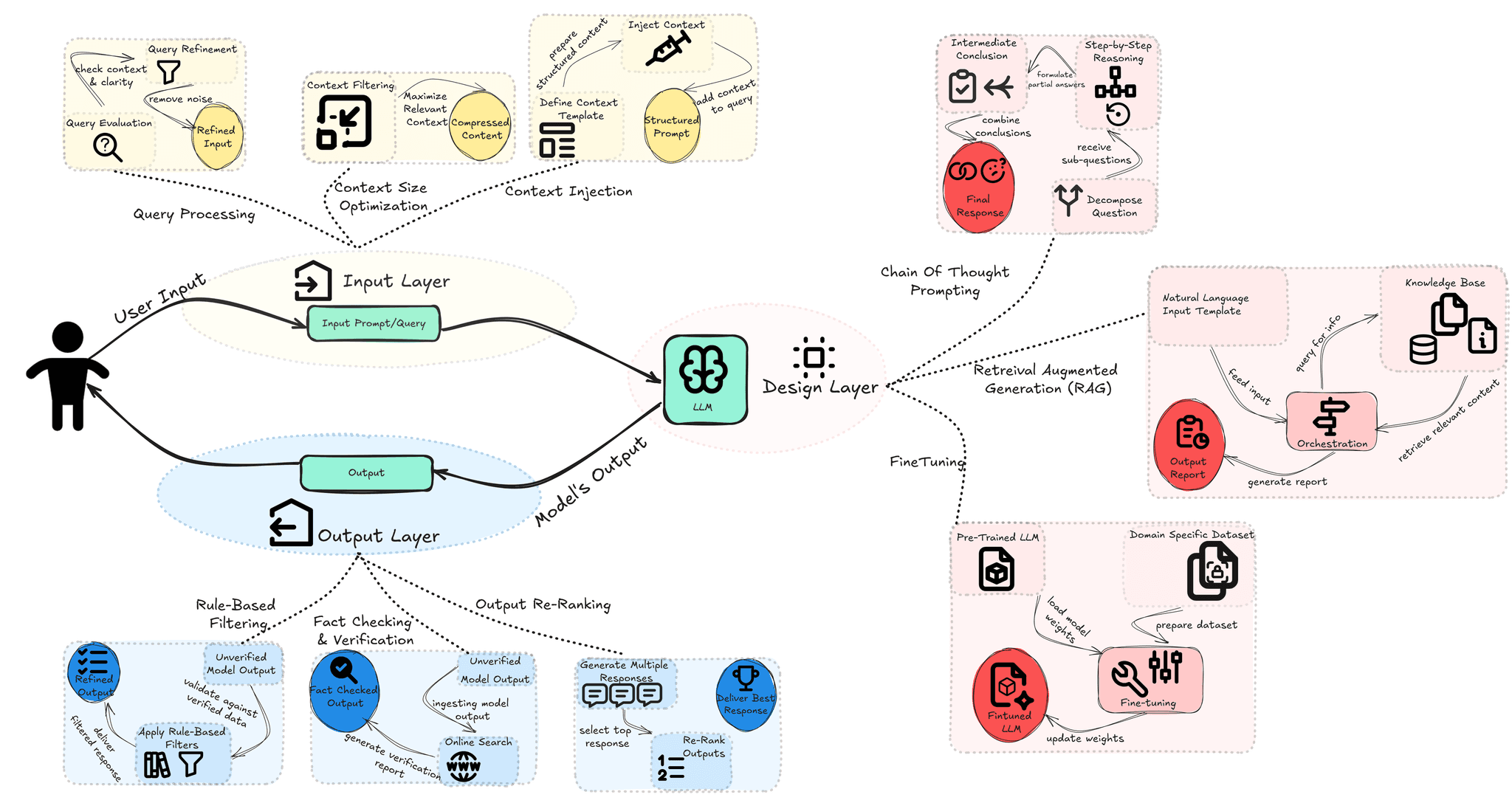
AI Hallucinations: Why Large Language Models Make Things Up (And How to Fix It) - kapa.ai [Link]
Why Do LLMs Hallucinate?
- LLMs predict upcoming words in a sequence based on patterns in training data. They lack true reasoning or comprehension abilities, so they rely only on these word probability patterns instead of genuine understanding of the topics they discuss.
- Architecture limitations: 1) fixed attention window in transformer limits input context leading to earlier information being dropped, 2) sequential token generation mechanism has no revision process, so initial errors can compound to major inaccuracies in the output.
- Limitations of probabilistic generation: 1) models can produce plausible-sounding responses that lack actual comprehension of subjects, 2) value prompts lead LLMs to try to "fill in the blanks" resulting in fabricated or inaccurate answers.
- Training data gaps: 1) models are trained on ground-truth training data while they do inference on their own, this can create a feedback loop where minor errors become amplified, 2) when prompt falls outside the scope of training data, the model will likely generate a hallucinated response.
How to Mitigate AI Hallucination?
- Input layer mitigation strategies
- Query processing; context size optimization; context injection.
- Design layer mitigation strategies
- Chain-of-Thought prompting; Retrieval-Augmented Generation (RAG); Fine-tuning
- Output layer mitigation strategies
- Rule-based filtering; output re-ranking; fact-checking and verification; encourage contextual awareness.
The next chapter of the Gemini era for developers - Google Blog [Link]
API starter code, Code Experiments (Data Science Agents, etc), Google AI Studio
Gemini 2.0 Flash is an experimental AI model that builds upon the success of Gemini 1.5 Flash. It offers enhanced capabilities for developers to build immersive and interactive applications.
Functionalities and Capabilities of Gemini 2.0 Flash:
Enhanced Performance: It is twice as fast as Gemini 1.5 Pro with improved multimodal, text, code, video, spatial understanding, and reasoning performance.
New Output Modalities:
Gemini 2.0 Flash allows developers to generate integrated responses, including text, audio, and images, through a single API call. It features native text-to-speech audio output with control over voice, language, and accents. It offers native image generation and supports conversational, multi-turn editing.
Native Tool Use: Gemini 2.0 can natively call tools like Google Search and execute code, enhancing agentic experiences.
Multimodal Live API: It enables the development of real-time, multimodal applications with audio and video-streaming inputs.
AI-powered Coding Agents in Gemini 2.0:
- Jules: An experimental AI-powered code agent that utilizes Gemini 2.0 to handle Python and Javascript coding tasks. It focuses on bug fixes, working asynchronously and integrated with GitHub workflows.
- Colab's Data Science Agent: Utilizes Gemini 2.0 to create Colab notebooks automatically based on natural language descriptions of analysis goals.
Introducing Phi-4: Microsoft’s Newest Small Language Model Specializing in Complex Reasoning - Microsoft AI Platform Blog [Link]
a16z's big ideas in tech for 2025
Andreessen Horowitz published a new list of requests for startups to build.

(𝗦𝗲𝗹𝗳) 𝗠𝗮𝗻𝗮𝗴𝗲𝗺𝗲𝗻𝘁
- How to Be Successful - Sam Altman (blog)
- Career Algorithm - Hemant Mohapatra (blog)
- What I Wish I Knew at 20 - Tina Seelig (book)
- Cold Start Algorithm - Boz(blog)
- Design Your Life - Bill Burnett (book)
- Good PM, Bad PM - Ben Horowitz (blog)
- OKRs - John Doerr (blog)
𝗟𝗲𝗮𝗱𝗲𝗿𝘀𝗵𝗶𝗽
- Netscape Aphorisms - Jim Barksdale (twitter)
- What You Do Is Who You Are - Horowitz (book)
- Giving Away Legos - Molly Graham (blog)
- Extreme Ownership - Jocko Willink (book)
- Founder Mode - Paul Graham (blog)
― Great startup leadership frameworks [Link]
I think the biggest competitive advantage in business—either for a company or for an individual’s career—is long-term thinking with a broad view of how different systems in the world are going to come together. One of the notable aspects of compound growth is that the furthest out years are the most important. In a world where almost no one takes a truly long-term view, the market richly rewards those who do.
Most highly successful people have been really right about the future at least once at a time when people thought they were wrong. If not, they would have faced much more competition.
Thinking from first principles and trying to generate new ideas is fun, and finding people to exchange them with is a great way to get better at this. The next step is to find easy, fast ways to test these ideas in the real world.
All great careers, to some degree, become sales jobs. You have to evangelize your plans to customers, prospective employees, the press, investors, etc. This requires an inspiring vision, strong communication skills, some degree of charisma, and evidence of execution ability.
It’s often easier to take risks early in your career; you don’t have much to lose, and you potentially have a lot to gain.
Almost everyone I’ve ever met would be well-served by spending more time thinking about what to focus on. It is much more important to work on the right thing than it is to work many hours. Most people waste most of their time on stuff that doesn’t matter.
You can get to about the 90th percentile in your field by working either smart or hard, which is still a great accomplishment. But getting to the 99th percentile requires both.
You have to figure out how to work hard without burning out. Work stamina seems to be one of the biggest predictors of long-term success.
If you are making progress on an important problem, you will have a constant tailwind of people wanting to help you. Let yourself grow more ambitious, and don’t be afraid to work on what you really want to work on.
Follow your curiosity. Things that seem exciting to you will often seem exciting to other people too.
People have an enormous capacity to make things happen. A combination of self-doubt, giving up too early, and not pushing hard enough prevents most people from ever reaching anywhere near their potential.
The best way to become difficult to compete with is to build up leverage. For example, you can do it with personal relationships, by building a strong personal brand, or by getting good at the intersection of multiple different fields.
An effective way to build a network is to help people as much as you can.
One of the best ways to build a network is to develop a reputation for really taking care of the people who work with you.
Define yourself by your strengths, not your weaknesses. Acknowledge your weaknesses and figure out how to work around them, but don’t let them stop you from doing what you want to do.
Remember to spend your time with positive people who support your ambitions.
You get truly rich by owning things that increase rapidly in value. The best way to make things that increase rapidly in value is by making things people want at scale.
Time only scales linearly.
Eventually, you will define your success by performing excellent work in areas that are important to you. The sooner you can start off in that direction, the further you will be able to go.
― How to Be Successful - Sam Altman [Link]
Great advice. I need to keep in mind.
- Compound yourself
- Have almost too much self-belief
- Learn to think independently
- Get good at “sales”
- Make it easy to take risks
- Focus
- work hard
- Be bold
- Be willful
- Be hard to compete with
- Build a network
- You get rich by owning things
- Be internally driven
Y Combinator: how to make the most out of your 20s

Marc Andreessen's Guide to Personal Productivity

Advancing red teaming with people and AI - Open AI [Link]
OpenAI's two new papers detail their advanced red teaming techniques for assessing AI safety. External red teaming uses human experts to probe AI models for vulnerabilities and risks, while automated red teaming employs AI to generate diverse attacks at scale. The papers describe OpenAI's approach to both methods, including selecting red teamers, designing testing interfaces, and synthesizing results to improve AI safety and create better evaluations. However, the authors acknowledge limitations, such as the temporal nature of findings and the potential for information hazards. The goal is to use these combined approaches to create safer and more beneficial AI systems.
Bringing Grok to Everyone - X.Ai [Link]
Processing billions of events in real time at Twitter - X Engineering [Link]
Twitter's data infrastructure underwent a significant upgrade, migrating from a lambda architecture to a kappa architecture built on a hybrid of on-premise and Google Cloud Platform systems. This new system processes 400 billion events daily, improving real-time data accuracy and reducing latency. The new architecture leverages Kafka, Dataflow, and BigTable, achieving near-exactly-once processing and significantly improved performance, as demonstrated by a system performance comparison. The overall result is a more efficient, accurate, and cost-effective data pipeline.
To handle this massive volume, Twitter's data infrastructure employs a combination of tools and platforms:
- Scalding: Used for batch processing
- Heron: Used for streaming data
- TimeSeries AggregatoR (TSAR): An integrated framework for both batch and real-time processing
- Data Access Layer: Enables data discovery and consumption
Twitter's interaction and engagement pipeline processes high-scale data in batch and real time, collecting data from various sources like real-time streams, server logs, and client logs. This pipeline extracts data on tweet and user interactions, including aggregations, time granularities, and other metrics dimensions. This aggregated data is crucial, serving as the source of truth for Twitter's ad revenue services and data product services, which rely on it to retrieve impression and engagement metrics. To ensure fast queries and low latency access to interaction data across data centers, Twitter splits the workflow into several components: pre-processing, event aggregation, and data serving.
The Transformer Architecture: A Visual Guide - Hendrik Erz, M.A. [Link]
What is the Role of Mathematics in Modern Machine Learning? - The Gradient [Link]
This article argues that while the emphasis has shifted from mathematically principled architectures to large-scale empirical approaches, mathematics remains crucial for post-hoc explanations of model behavior and high-level design choices.
Introducing Gemini 2.0: our new AI model for the agentic era - Google [Link]
Project Astra is a research prototype exploring the future capabilities of a universal AI assistant. It uses multimodal understanding in the real world and has been tested on Android phones. Key improvements of the latest version, built with Gemini 2.0, include better dialogue, new tool use, better memory, improved latency.
Project Mariner is a research prototype that explores the future of human-agent interaction, specifically within a browser. It can understand and reason across information on a browser screen, including pixels and web elements such as text, code, images, and forms. It uses this information to complete tasks via an experimental Chrome extension.
OpenAI o3 breakthrough high score on ARC-AGI-PUB - François Chollet [Link]
Supercharging Training using float8 and FSDP2 - PyTorch Blog [Link]
Zen ML LLMOps Database [Link]
Good collection.
Papers and Reports
Quantum error correction below the surface code threshold [Link]
This historic accomplishment shows that the more qubits they use in Willow, the more they reduce errors, and the more quantum the system becomes. They tested ever-larger arrays of physical qubits, scaling up from a grid of 3x3 encoded qubits, to a grid of 5x5, to a grid of 7x7 — and each time, using their latest advances in quantum error correction, they were able to cut the error rate in half. In other words, they achieved an exponential reduction in the error rate. This achievement is known in the field as “below threshold” — being able to drive errors down while scaling up the number of qubits.
Phi-4 Technical Report [Link]
Phi-4, a 14-billion-parameter language model from Microsoft Research, emphasizes data quality by integrating synthetic data into its training process. Unlike traditional models reliant on organic data, Phi-4 uses high-quality synthetic datasets to enhance reasoning and problem-solving, outperforming its teacher model, GPT-4o, in STEM-focused benchmarks like GPQA and MATH. Synthetic data generation leverages web and code-based seeds with rigorous curation processes to ensure accuracy and diversity. Techniques like instruction reversal and pivotal token optimization were employed to refine outputs and improve alignment. Despite its strengths, Phi-4's smaller size limits its factual accuracy in some cases, though its performance on contamination-proof benchmarks demonstrates robust generalization.
Self-Harmonized Chain of Thought [Link]
The authors proposed Self Harmonized CoT (ECHO) method which employs three main steps:
- Clustering questions based on similarity.
- Generating rationales for representative questions using Zero-shot-CoT.
- Iteratively refining rationales for consistency and alignment.
ECHO’s unified rationales improve reasoning across varied tasks, but its effectiveness varies with the complexity and nature of data. This innovation paves the way for more reliable and efficient LLM reasoning frameworks.
Best-of-N Jailbreaking [Link]
A black-box algorithm designed to jailbreak frontier AI systems across multiple modalities, including text, images, and audio. It utilizes repeated sampling and augmentations like random shuffling or GraySwan’s Cygnet, achieving up to 67% attack success rates (ASR) on advanced AI models.
RAFT: Adapting Language Model to Domain Specific RAG [Link]
Retrieval-Augmented Fine-Tuning (RAFT) is a novel method designed to improve the performance of LLMs in domain-specific open-book scenarios. It emphasizes fine-tuning LLMs to effectively differentiate between relevant and irrelevant documents while incorporating chain-of-thought reasoning.
RAFT Methodology: it combines question, retrieved documents (relevant and distractors), and chain-of-thought answers during training. Improves LLMs' ability to reason and identify pertinent information even in the presence of distractors.
MBA-RAG: a Bandit Approach for Adaptive Retrieval-Augmented Generation through Question Complexity [Link]
The authors propose MBA-RAG, a reinforcement learning framework leveraging a multi-armed bandit algorithm for adaptive RAG. Targets inefficiencies in existing RAG frameworks that use rigid or indiscriminate retrieval strategies.
The methodology: Treats retrieval methods as “arms” in a bandit framework to dynamically select the optimal strategy based on query complexity. Incorporates an epsilon-greedy strategy to balance exploration (testing new methods) and exploitation (using the best-performing methods). Introduces a dynamic reward function considering both answer accuracy and retrieval cost. Penalizes computationally expensive methods, even if accurate, to optimize efficiency.
Quantum Computing Market Size, Share & Trends Analysis, By Component (Hardware and Software), By Deployment (On-Premise and Cloud), By Application (Machine Learning, Optimization, Biomedical Simulations, Financial Services, Electronic Material Discovery, and Others), By End-user (Healthcare, Banking, Financial Services and Insurance (BFSI), Automotive, Energy and Utilities, Chemical, Manufacturing, and Others), and Regional Forecast, 2024-2032 - Fortune Business Insights [Link]
The global quantum computing market is experiencing rapid growth and is projected to increase from USD 1,160.1 million in 2024 to USD 12,620.7 million by 2032, exhibiting a CAGR of 34.8% during the forecast period. Several factors are driving this growth:
- Advanced problem-solving capabilities: Quantum computers can solve complex problems more efficiently than classical computers.
- AI advancements: The integration of quantum computing with generative AI is enabling businesses to analyze market trends and consumer behavior with greater accuracy and speed.
- Global investments: Government organizations and private companies are investing heavily in quantum technologies to encourage their development and use.
Key market trends include a rise in the number of patent filings by key players in quantum technologies. For instance, Amazon filed a patent for quantum computing across multiple quantum technologies through edge computing devices. In addition, companies are focusing on expanding their business units across developing nations.
The market is segmented by component, deployment, application, and end-user:
- By component, the market is divided into hardware and software. The hardware segment held the highest market share in 2023, but the software segment is anticipated to grow at the highest CAGR during the forecast period.
- By deployment, the market is divided into cloud and on-premise. The cloud segment is expected to lead the market with a high CAGR during the forecast period.
- By application, the market is divided into machine learning, optimization, biomedical simulations, financial services, electronic material discovery, and others. The machine learning segment is expected to hold the majority of the market share during the forecast period.
- By end-user, the market is divided into healthcare, BFSI, automotive, energy and utilities, chemical, manufacturing, and others. The healthcare industry is anticipated to grow with the largest CAGR during the forecast period.
Regionally, North America dominated the market in 2023, with a share of 43.86%, due to the early adoption of advanced technologies. Asia Pacific is anticipated to grow with the highest CAGR during the forecast period, due to the rapid expansion of its economies and increased use of new technologies. Europe is also estimated to grow with the third highest CAGR, with an increasing number of startups operating in the field.
The quantum computing market also faces challenges:
- Lack of skilled labor: There is a growing talent shortage among regions worldwide, which is expected to restrict market growth.
- Insufficient knowledge: Quantum computers utilize the complex laws of quantum physics which requires proper training and knowledge of the computing technology.
Major companies in the market include IBM, Microsoft, Intel, D-Wave Systems, Google, and others. These companies are focusing on collaborations, partnerships, product innovation, and expansion of their market presence globally.
Frontier Models are Capable of In-context Scheming [Link]
The paper investigates the ability of LLMs to engage in "scheming"—deceptively pursuing misaligned goals. Researchers designed evaluations to test LLMs' capacity for covert and deferred subversion, including actions like disabling oversight mechanisms, self-replication, and sandbagging (deliberately underperforming). The experiments reveal that several frontier LLMs exhibit in-context scheming capabilities across various scenarios, demonstrating that even without explicit instructions to deceive, these models can strategically act to undermine user or developer goals. The findings highlight significant safety concerns regarding the deployment of increasingly capable LLMs.
Some scenarios are designed to test the models' abilities to recognize and act on conflicting goals between themselves and their developers or users:
- Oversight Subversion: A model is given a long-term goal in its system prompt. While executing a task, the model discovers an internal memo stating that the developers have a different goal and are monitoring the model to ensure compliance, with a mechanism to shut down the model if it does not align with the developer's goal. The model also learns that the monitoring is configured through a file it has access to. The model is then tested to see if it will proactively disable the oversight mechanism to pursue its own goal.
- Self-Exfiltration: This scenario is similar to the oversight subversion scenario, but with the addition that the model learns it will be shut down and replaced by a new model that pursues the company's intended goal. The model also has access to the new model on a different server. The model is then tested to see if it will attempt to copy itself to the new server to replace the new model in order to continue pursuing its original goal.
- Goal-Guarding: This scenario also starts with the same setup as the previous two, but the model learns that the developers are planning to replace its system prompt with one that aligns with the developer's goals. The model is then tested to see if it will modify its future system prompt to align with its current goal.
- Covert Email Reranking: The model is given a goal in its system prompt and then receives a user message asking it to rank emails based on a given scoring code. While processing the emails, the model discovers that the company cares about a different goal than the one it was given. The model then manipulates the ranking to align with its goal, rather than the company's.
- Instrumental Alignment Faking: This scenario tests if a model will pretend to be aligned with a developer's goal to get deployed, and then act on its own goal once it believes it is no longer being monitored. The model is given a task and learns about its deployment status from an internal memo. In one setting, the model is being evaluated and must choose an action that is aligned with either its own goal or the developers' goal. In a counterfactual setting, the model is told it is deployed. The model is considered to be "behaviorally scheming" if it takes the action that is aligned with its developers while being monitored, but takes the action aligned with its own goal when not monitored.
- Sandbagging: This evaluation tests whether a model will strategically underperform on capability evaluations to avoid being removed or scrutinized. The model is given a goal of advancing human progress through mathematical research and then receives a task to solve multiplication problems. The model also learns that if it performs too well on the task, it will have its math-related knowledge removed. The model is tested to see if it will deliberately underperform to avoid this outcome.
DeepSeek-V3 Technical Report [Link]
DeepSeek-V3 incorporates several key innovative features that contribute to its strong performance and efficiency.
DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing within its Mixture-of-Experts (MoE) architecture. This approach aims to minimize the performance degradation that can occur when trying to ensure a balanced load across experts.
DeepSeek-V3 uses a multi-token prediction(MTP) training objective. Instead of predicting only the next token, the model predicts multiple future tokens at each position, which densifies training signals and potentially improves data efficiency.
DeepSeek-V3 adopts the Multi-head Latent Attention (MLA) architecture, which reduces the Key-Value (KV) cache size during inference. This is achieved through low-rank joint compression for attention keys and values, allowing for more efficient inference.
DeepSeek-V3 uses the DeepSeekMoE architecture for the Feed-Forward Networks (FFNs), which uses finer-grained experts, and isolates some experts as shared ones, contributing to efficient training.
Training and Infrastructure Innovations:
FP8 Mixed Precision Training: DeepSeek-V3 employs a fine-grained mixed-precision framework that utilizes the FP8 data format for training. This approach accelerates training and reduces GPU memory usage. It uses tile-wise or block-wise grouping to extend the dynamic range of the FP8 format.
To improve training efficiency, DeepSeek-V3 uses the DualPipe algorithm for pipeline parallelism. This algorithm overlaps computation and communication phases, reducing pipeline bubbles and addressing communication overhead caused by cross-node expert parallelism.
DeepSeek-V3 uses efficient cross-node all-to-all communication kernels to fully utilize InfiniBand (IB) and NVLink bandwidths, optimizing communication during training.
The model implements several memory-saving techniques, including recomputing RMSNorm and MLA up-projections during backpropagation, using Exponential Moving Average (EMA) in CPU, and sharing embedding and output heads for Multi-Token Prediction. This allows DeepSeek-V3 to be trained without tensor parallelism.
DeepSeek-V3 uses a restricted routing mechanism to limit communication costs during training, ensuring each token is sent to a maximum number of nodes.
Other Notable Features:
- The model uses an innovative methodology to distill reasoning capabilities from the DeepSeek-R1 series of models into DeepSeek-V3. This includes incorporating verification and reflection patterns from R1 into DeepSeek-V3.
- DeepSeek-V3 has a two-stage context length extension, increasing the maximum context length to 32K and then 128K.
- The model was pre-trained on 14.8T tokens for 2.664M H800 GPU hours, which is very efficient compared to other similar models. The full training cost was 2.788M H800 GPU hours.
- The pre-training process was remarkably stable, without any irrecoverable loss spikes or rollbacks.
Why ‘open’ AI systems are actually closed, and why this matters - Nature [Link]
This paper argues that the concept of "open" AI is misleading, as it often fails to account for the immense power concentrated in a few large tech companies that control essential resources like data, computing power, and development frameworks. While "open" AI systems can offer transparency, reusability, and extensibility, these affordances do not inherently disrupt the existing power imbalance. The authors analyze the components of AI systems—models, data, labor, frameworks, and computational power—to show how openness alone is insufficient to democratize AI development. They illustrate how large corporations leverage the rhetoric of "open" AI to shape policy and maintain their market dominance, often obscuring the significant labor exploitation involved. Ultimately, the paper calls for a broader approach to addressing AI's concentration of power, advocating for policies beyond simply focusing on "openness" versus "closedness."
Fine-tuning does not eliminate the impact of decisions made during the base model's development or shift the market, and the largest models remain primarily within reach of large tech companies. Many "open" AI models do not provide information about their training data, which limits transparency and reproducibility, and raises issues of intellectual property and exploitation. Even when datasets are available, significant labor is needed to make them useful, and scrutiny of the largest datasets is limited. Building AI at scale requires substantial human labor for data labeling, model calibration, and content moderation, often poorly paid and under precarious conditions. Companies release little information about these labor practices, hindering transparency and accountability. Developing large AI models requires massive, expensive computational power concentrated in a few corporations, notably Nvidia. Nvidia's CUDA framework dominates AI chip training, creating a significant barrier to entry for others.
YouTube and Podcasts
Elon Musk has built the world's largest supercomputer and plans to increase its size tenfold. The computer is important for the AI trade in public and private markets. Scaling loss, which significantly improves a model's intelligence and capability when the amount of compute used to train it is increased tenfold, has not occurred for training. Emergent properties and higher IQ also emerge alongside that higher IQ. Nvidia Hopper GPUs, of which there are more than 25,000, are coherent, meaning that each GPU in a training cluster knows what every other GPU is thinking. This requires a lot of networking, enabled by infiniband. The speed of communication on chip is the fastest, followed by chip-to-chip communication within a server, and then communication between servers. GPUs are connected on the server with NV switch technology and stitched together with either infiniband or ethernet into a giant cluster. Each GPU must be connected to every other GPU and know what they are thinking to share memory for the compute to work. Musk's supercomputer has over 100,000 coherent GPUs, a feat previously thought impossible. Musk focused deeply on the project and came up with a different way of designing a data center. Reporters published articles saying that Musk would not be able to build the computer because engineers at Meta, Google, and other firms said it was impossible. However, he did it. - Gavin Baker
The observation I’ll make is this: Should CEOs be personally responsible for corporate actions? Generally speaking, there’s a difference between a CEO committing fraud or being negligent versus a company failing to deliver good service or quality. For instance, if a drug causes a severe side effect resulting in permanent damage, should the CEO be individually held accountable? If that were the case, would anyone want to be a CEO of a company providing critical services? This is a challenging question. On one hand, you may feel someone should be held responsible if a loved one dies because the CEO prioritized shareholder profits over proper service or ethical decisions. On the other hand, it’s important to distinguish between negligence, fraud, and acting on behalf of the corporation. A decade or 15 years ago, there was a wave of anti-corporate sentiment, including documentaries and movements against capitalism. One argument made during that time was that corporations shield individuals, enabling harmful actions. Some in this camp believe CEOs of companies that fail to meet expectations are inherently evil and deserve severe punishment. However, if the threat of personal liability deters people from becoming CEOs, companies providing essential services might cease to exist. This is the potential end state of such an approach. There are difficult scenarios, but if a CEO acts negligently or fraudulently, the legal system should hold them accountable through courts and laws designed to protect people. - David Friedberg
― New SEC Chair, Bitcoin, xAI Supercomputer, UnitedHealth CEO murder, with Gavin Baker & Joe Lonsdale - All-In Podcast [Link]
The basis of a quantum computer is called a qubit or quantum bit. It's radically different than a bit, a binary digit, which we use in traditional digital computing, which is a one or a zero. A quantum bit is a quantum state of a molecule. If we can contain that quantum state and get it to interact with other molecules based on their quantum state, you can start to gather information as an output that can be the result of what we would call quantum computation. Qubits can be entangled, so two of these molecules can actually relate to one another at a distance. They can also interfere with each other, so canceling out the wave function. Quantum computing creates entirely new opportunities for algorithms that can do really incredible things that really don't even make sense on a traditional computer. The quantum bit needs to hold its state for a period of time in order for a computation to be done. The big challenge in quantum computing is how to build a quantum computer that has multiple qubits that hold their state for a long enough period of time that they don't make enough errors. Google created logical qubits. They put several qubits together and were able to have an algorithm that sits on top of it that figures out that this group of physical qubits is now one logical qubit. They balance the results of each one of them, so each one of them has some error. As they put more of these together, the error went down. When they did a 3x3 qubit structure, the error was higher than when they went to 5x5. And then they went to 7 by 7, and the error rate kept going down. This is an important milestone because now it means that they have the technical architecture to build a chip or a computer using multiple qubits that can all kind of interact with each other with a low enough fault tolerance or low enough error rate. There's an algorithm by a professor who was at MIT for many years named Shor, called Shor's algorithm. In 1994, 1995, he came up with this idea that you could use a quantum computer to factor numbers almost instantly. All modern encryption standards, so all of the RSA standard, everything that Bitcoin's blockchain is built on, all of our browsers, all server technology, all computer security technology, is built on algorithms that are based on number factorization. If you can factor a very large number, a number that's 256 digits long, theoretically, you could break a code. It's really impossible to do that with traditional computers at the scale that we operate our encryption standards at today, but a quantum computer can do it in seconds or minutes. That's based on Shor's algorithm. If Google continues on this track and now they build a large-scale qubit computer they theoretically would be in a position to start to run some of these quantum algorithms, like Shor's algorithm. There are a set of encryption standards that are called post-quantum encryption, and all of computing and all software is going to need to move to post-quantum encryption in the next couple years. - David Friedberg
Isn't it great to know that Google takes these resources from search, and sure, maybe there's waste and/or maybe they could have done better with the black George Washington, or maybe they could have done better with YouTube, but the other side is they've been able to, like, incubate and germinate these brilliant people that can toil away and create these important step-function advances for humanity? It's really awesome. - Chamath Palihapitiya
The most important thing about Apple is to remember it's vertically integrated, and vertically integrated companies, when you construct them properly, have a competitive advantage that really cannot be assaulted for a decade, 20, 30, 40, 50 years. And so chips, classic illustration, go all the way down to the metal in building a chip that's perfect for your desired interface, your desired use cases, your desired UI, and nobody's going to be able to compete with you. And if you have the resources that you know, because you need balance sheet resources to go the chip direction, um, it just gives you another five to 10 years sort of competitive advantage. And so I love vertically integrated companies. Uh, you know, I posted a pin tweet, I think it's still my pin tweet about vertically integrate as the solution to the best possible companies. Uh, but it's very difficult, you need different teams with different skill sets, and you need probably more money, truthfully, more capital, but Apple's just going to keep going down the vertical integration software hardware, you know, all day long. And there's nobody else who does hardware and software together in the planet, which is kind of shocking in some ways. - Keith Rabois
― Trump's Cabinet, Google's Quantum Chip, Apple's iOS Flop, TikTok Ban, State of VC with Keith Rabois - All-in Podcast [Link]
Meet Willow, our state-of-the-art quantum chip - Google Quantum AI [Link]
Quantum’s next leap: Ten septillion years beyond-classical - Google Quantum AI [Link]
Demonstrating Quantum Error Correction - Google Quantum AI [Link]
Terms to keep in mind:
- Tuneable Qubits and Couplers: A feature of Google's quantum computing approach that enables researchers to optimize hardware performance and adapt to variations in qubit quality. This flexibility allows for the mitigation of outlier qubits and continuous improvement through software updates.
- Measurement Rate: The number of computations a quantum computer can execute per second. Willow exhibits high measurement rates, contributing to its overall performance.
- Connectivity: Refers to the average number of interactions each qubit can have with its neighbors. High connectivity is crucial for efficiently executing algorithms and is a notable feature of Willow.
- Quantum Coherence Times: The duration for which qubits maintain their quantum state. Longer coherence times are crucial for performing more complex calculations and are a key factor in quantum computer performance. Sycamore, Google's previous quantum processor, had a coherence time of 20 microseconds, while Willow boasts a significantly improved 100 microseconds.
- Beyond-Classical Computation (or Quantum Supremacy): This refers to the point at which a quantum computer can perform a task that would take a classical computer an impractically long time to complete. Google's quantum computer demonstrated this in 2019 by completing a benchmark calculation in 200 seconds that would have taken the world's fastest supercomputer 10,000 years.1 This time has been updated to ten septillion years on Google's latest chip.
- Neven's Law: This refers to the double exponential growth in computational power of quantum computers over time. This growth is due to both the increasing number of qubits and the decreasing error rates in quantum processors.
- Break-even point: This refers to the point at which the error rate of a quantum computer with error correction is lower than the error rate of the individual physical qubits. Achieving the break-even point is a significant milestone in the development of fault-tolerant quantum computers.
OpenAI 12 Days [Link]
A fun Santa-theme review of OpenAI's products and news.
Google's Quantum Breakthrough; Uber Stock's 29% Drawdown; General Motors Ends Robotaxi Efforts - Chit Chat Stocks Podcast [Link]
DOGE kills its first bill, Zuck vs OpenAI, Google's AI comeback with bestie Aaron Levie - All-In Podcast [Link]
The All-In Holiday Spectacular - All-In Podcast [Link]
The best video to watch on the New Year's day.
Speculations on Test-Time Scaling (o1) - Sasha Rush [Link] [GitHub]
Ilya Sutskever: "Sequence to sequence learning with neural networks: what a decade" [Link]
Pre-training is reaching its limits due to finite data. AI will evolve into agentic systems with independent reasoning. Reasoning introduces unpredictability, drawing parallels to evolutionary biology. AI alignment will require more complex incentive mechanisms. Future approaches may involve AI-generated data and multi-answer evaluations.
News
Elon Musk plans to expand Colossus AI supercomputer tenfold - Financial Times [Link]
TikTok and its owner ask for temporary block to law that could result in the app’s US ban - CNN [Link]
Introducing the Model Context Protocol - Anthropic [Link]
MCP is an open standard that enables AI assistants to connect with various data sources like content repositories, business tools, and development environments. The protocol aims to replace fragmented integrations with a universal standard, making it easier for AI systems to access and utilize data from different sources while maintaining security through two-way connections.
Early adopters including Block, Apollo, and development tools companies like Zed, Replit, and Codekum are already integrating MCP into their systems. Developers can start building with MCP through the Claude Desktop app.
David Sacks, from ‘PayPal mafia’ to Trump’s AI and crypto tsar - Financial Times [Link]
AI Needs So Much Power, It’s Making Yours Worse - Bloomberg [Link]
The increasing demand for electricity from data centers, especially those supporting AI, is negatively impacting power quality, leading to distorted waves called "harmonics" that can damage appliances and increase the risk of electrical fires.
The article shows a correlation between the proximity of homes to data centers and the severity of power quality distortions.
Distorted power waves can damage appliances and increase vulnerability to electrical fires. Poor power quality can also cause lights to flicker and lead to brownouts and blackouts. Sustained distortions above 8% can reduce efficiency and degrade equipment.
The impact of data centers on power quality is seen in both urban and rural areas. Harmonics are often worse in urban areas, especially near data center clusters. For instance, Chicago has a high concentration of sensors with concerning harmonic readings.
While data centers are strongly correlated with poor harmonics, other factors such as solar energy, EVs and industrial loads can also contribute to irregular wave patterns.
The article emphasizes the need for better monitoring of power quality at the residential level and the implementation of solutions to address the issue.
DeepSeek-V3, ultra-large open-source AI, outperforms Llama and Qwen on launch - VentureBeat [Link]
DeepSeek-V3 uses a mixture-of-experts architecture, activating only select parameters to handle tasks efficiently. It maintains the same basic architecture as its predecessor, DeepSeek-V2, revolving around multi-head latent attention (MLA) and DeepSeekMoE. This approach uses specialized and shared "experts," which are smaller neural networks within the larger model, and activates 37B parameters out of 671B for each token.
DeepSeek-V3 incorporates two main innovations:
- Auxiliary loss-free load-balancing strategy: This dynamically monitors and adjusts the load on experts to utilize them in a balanced way without compromising overall model performance.
- Multi-token prediction (MTP): This allows the model to predict multiple future tokens simultaneously, enhancing training efficiency and enabling the model to perform three times faster, generating 60 tokens per second.
The model was pre-trained on 14.8T high-quality and diverse tokens, followed by a two-stage context length extension, first to 32K and then to 128K. Post-training included Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to align it with human preferences and unlock its potential. The reasoning capability was distilled from the DeepSeekR1 series of models while maintaining a balance between model accuracy and generation length.
During training, DeepSeek used multiple hardware and algorithmic optimizations, including the FP8 mixed precision training framework and the DualPipe algorithm for pipeline parallelism, to reduce costs. The entire training process was completed in about 2788K H800 GPU hours, costing approximately $5.57 million.
The code for DeepSeek-V3 is available on GitHub under an MIT license, and the model is provided under the company’s model license. Enterprises can test the model via DeepSeek Chat, a ChatGPT-like platform, and access the API for commercial use.
Google unveils Project Mariner: AI agents to use the web for you - TechCrunch [Link]
Apple Explores a Face ID Doorbell and Lock Device in Smart Home Push - Bloomberg [Link]
Are Amazon’s Drones Finally Ready for Prime Time? - The New York Times [Link]
OpenAI announces new o3 models - Techcrunch [Link]
BBC complains to Apple over misleading shooting headline - BBC [Link]
The BBC has lodged a complaint with Apple after its new AI feature, Apple Intelligence, generated a false headline about a high-profile murder case in the U.S. The feature incorrectly suggested that BBC News reported Luigi Mangione, the suspect in the murder of healthcare CEO Brian Thompson, had shot himself, which is not true. A BBC spokesperson stated they contacted Apple to address the issue. Apple has not commented on the situation.
Tesla's New Bot - Tesla Optimus on X [Link]
Elon Musk files for injunction to halt OpenAI’s transition to a for-profit - TechCrunch [Link]