Persisting Agent State
Persistence in LangGraph
Persistence is a cornerstone for building robust and production-grade applications. LandGraph introduces a game-changing feature that ensures application states are stored and retrievable at any point. This redefines reliability and scalability in workflow management. This capability is especially vital when executing workflows involving interruptions, user inputs, or debugging. Whether you're building a simple app or an enterprise-grade system, persistence ensures your application is always ready to handle interruptions and user interactions gracefully.
The "Persisting Agent Stage" enables seamless workflows, especially in user-facing applications. Here’s why this feature is critical:
- Human-in-the-Loop Workflows: Many applications rely on user input to make decisions or advance processes. With persistence, LandGraph allows the graph execution to pause, checkpoint the state into persistent storage, and resume later. This means the application can wait for user input and continue without losing context.
- Debugging and History: Persistence creates a robust mechanism for saving the application state after every step. This makes debugging easier and enables the creation of detailed execution histories.
- Support for Multi-Session Scenarios: Applications often require users to switch between sessions while maintaining their progress. Persistence ensures continuity by saving states into persistent storage.
At the heart of this feature is the CheckPointer object, a persistence layer implemented by LandGraph. Here’s how it works:
Integration with Databases The CheckPointer can save states into various database types, including:
- Document databases: Firestore, MongoDB
- Relational databases: PostgreSQL, SQLite, MySQL
- Graph databases: Neo4j, AWS Neptune
For example, the following section will focus on persisting states into an SQLite database, a popular choice for local environments. The process can also be extended to managed cloud databases like Google Cloud SQL or AWS RDS.
State Management As each node in the graph executes, the CheckPointer saves the updated state into the database. This ensures that states are recoverable after interruptions, enabling the graph to resume execution from exactly where it left off.
To implement persistence, follow these simple steps:
- Import the CheckPointer object from LandGraph.
- Create an instance of CheckPointer and configure it with a connection string (local or cloud-based database).
- Pass the CheckPointer instance to your graph during creation. LandGraph will handle state persistence automatically after each node execution.
1 | from langgraph.checkpoint.sqlite import SqliteSaver |
The result is that you can pause the graph, fetch user input, and continue execution seamlessly, all while ensuring states are securely stored in your chosen database.
MemorySaver + Interrupts = Human In The Loop
Human-in-the-loop systems are essential to modern applications, allowing seamless integration of human feedback into automated workflows. With the help of the MemorySaver feature, you can build applications using LangGraph that pause, capture user input, and resume execution effortlessly.
In workflows involving human interaction, there are moments where the application needs to pause, gather feedback from the user, and then continue processing. For instance, consider a sequence of tasks where:
- A process executes its initial steps.
- The system pauses to collect human input.
- The workflow resumes, incorporating the user’s feedback.
This type of flow requires interrupts to halt the execution and persistence to save the current state of the workflow. Langraph provides the tools to manage both seamlessly.
Implementation
To illustrate, let’s build a straightforward graph with the following steps:
- Start with a simple initial node.
- Execute a task and pause for human feedback.
- Resume execution with the updated state and complete the workflow.
We use Langraph's MemorySaver, a checkpointing tool that saves the workflow’s state in memory after each node’s execution. This ephemeral storage method is perfect for local testing and prototyping. Here’s a simplified version of the setup:
1 | from dotenv import load_dotenv |
The graph visualization by using Mermaid.ink is here:
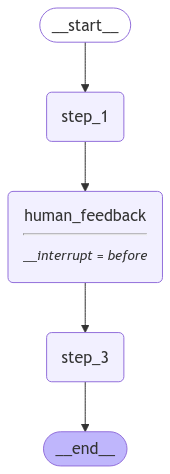
MemorySaver Implementations
Integrating human feedback into automated systems is a growing trend in AI development. It bridges the gap between machine automation and human judgment, enabling better decision-making, improved accuracy, and adaptability. In this section, we explore how to incorporate human-in-the-loop functionality into a graph-based system while leveraging memory storage to track execution states. This walkthrough showcases the process from initialization to final execution.
1 | from dotenv import load_dotenv |
The graph’s execution is tied to a thread variable, a
dictionary initialized with a thread_id. This serves as a
session or conversation identifier, distinguishing various graph runs.
For simplicity, the thread_id is set to 1,
though a more robust implementation would use a UUID. The graph
processes events using graph.stream(), which accepts the
initial input and thread details. Events are streamed in value mode, and
each event is printed for transparency.
During execution:
- Input is processed.
- Node executions are logged.
- Interruptions allow for dynamic human input.
Running the graph in debug mode provides insights into:
- Memory storage (
memory.storage) containing nested objects that log the graph state. - Transition logs for each node, showing updates or lack thereof.
At an interrupt, human feedback is solicited using Python's built-in
input() function. This input updates the state dynamically.
Once human input is integrated, the graph resumes execution. Subsequent
steps process the updated state, leading to the graph’s completion.
SqliteSaver
Switching from an ephemeral memory-based state saver to a persistent
database saver can significantly enhance the durability and traceability
of your graph’s execution. In this section, we’ll explore how to replace
the in-memory MemorySaver with an SQLiteSaver
for long-term storage and easy debugging.
The MemorySaver is transient, meaning all state
information vanishes after the program stops. By using an SQLite
database, you can:
- Persist graph states across runs.
- Debug and troubleshoot using a structured database.
- Resume executions exactly where they were interrupted.
1 | import sqlite3 |
We start by importing the required modules. Then Initialize a
connection to your SQLite database. The
check_same_thread=False flag ensures thread-safe database
operations, essential for stopping and restarting execution across
different threads. After that we create an instance of
SQLiteSaver and pass it the SQLite connection. This saver
integrates seamlessly with the graph execution pipeline, persisting
states to the SQLite database.
- Initial Execution: Run the graph with the
SQLiteSaver. After execution, you’ll see a new file,checkpoints.sqlite, created in your project directory. - Inspect the Database: Use your IDE’s database tools
(e.g. SQLite3 Editor for VS Code) to load and inspect the
checkpoints.sqlitefile. You’ll find a table storing graph states, similar to what you’d see withMemorySaver, but now it’s persistent.
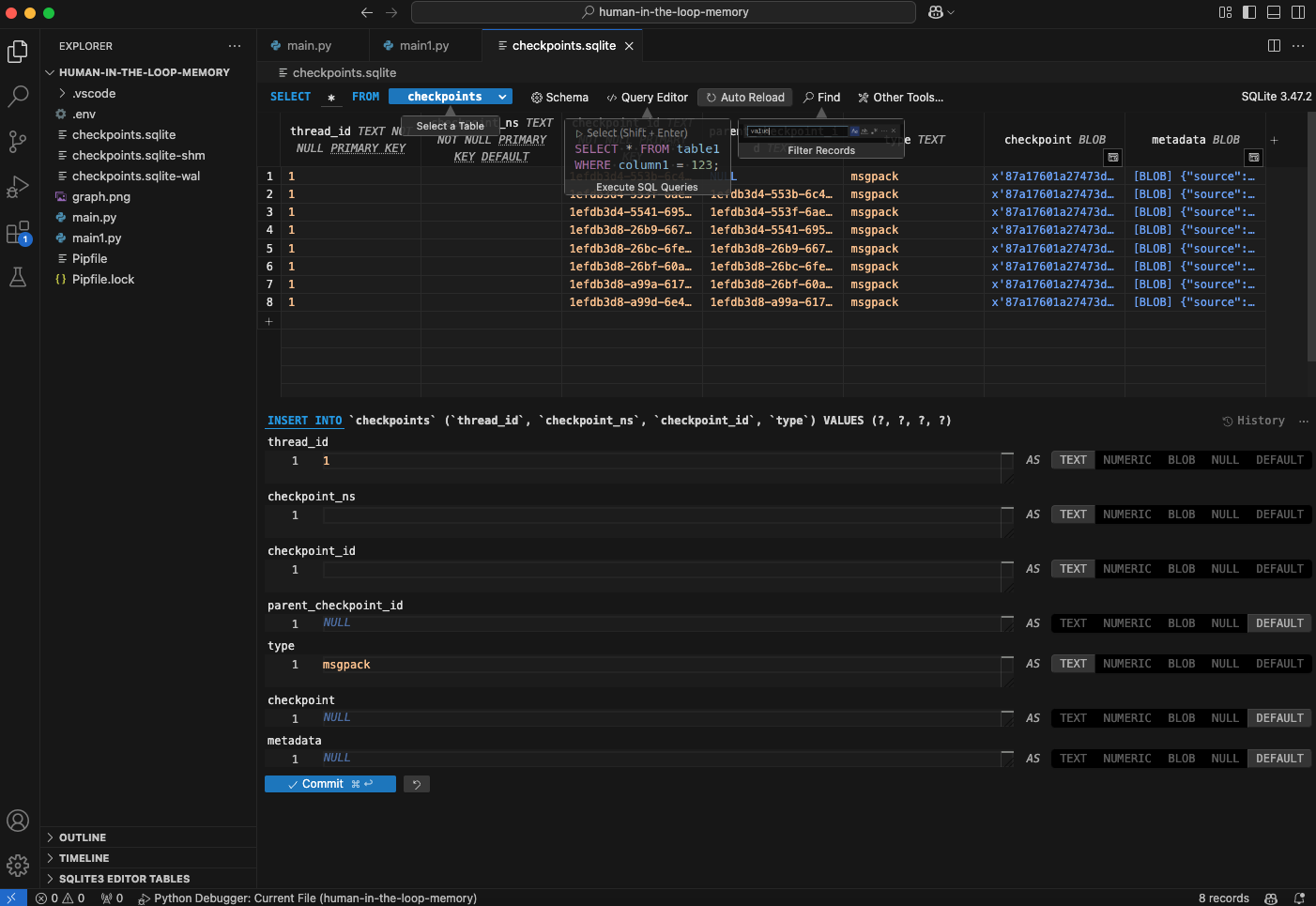
Changing the thread_id allows you to simulate a new
session while retaining access to previous runs. When resuming, the
graph starts from the last recorded state. You can verify this by
inspecting the database entries for the new thread_id.
For enhanced traceability, integrate Langsmith for tracking and debugging. Langsmith provides detailed insights, including thread metadata and execution traces.