2025 July - What I Have Read
Substack
Generative AI is revolutionizing how code is written. In just the past 6 months, coding assistant tools like Cursor, Windsurf, Lovable, Bolt, and Replit have evolved from being cute ways to help with 10-20% of code to now generating the majority of code for many startups. 1 in 4 companies in the latest YC batch have 95% of their code written by AI.
This new way to build products is much faster and simpler than before, it involves just 4 steps.
- Prioritize features by impact
- Ship simple version or clickable prototype
- Test at scale with users, measure impact
- Iterate or kill
― The Lean Startup is Dead - Fletcher Richman [Link]
A key part of being a lifelong learner is retaining what you are learning and comparing ideas and putting learning into our lives.
I choose a certain number of topics/books that I want to read/learn each year and focus on reading those books deliberately.
I find reading to be a more positive habit than scrolling mindlessly on my phone or watching YouTube videos. I do those things as well but I try to change my habits by choosing books instead. I also read multiple books at a time. This helps me avoid feeling the dread of picking up a challenging or long book when I am tired after a long day.
I have tried different retention techniques over the years, and have found these to work best for me. At first, these were slower and felt less efficient, but I have gotten faster and better at utilizing these tips with practice.
― How To Remember What You Read - Ryan Hall, Read and Think Deeply [Link]
Ryan Hall's top five tips for retaining more of what you are reading:
Underline or highlight key ideas or phrases.
- When reading deeply, always have a pen or highlighter in hand.
- On the first read-through, underline or highlight any key concepts, ideas, characters, or quotes.
This practice makes the reader interactive with the text and enables quick review of key concepts after reading. Reviewing these key ideas after finishing a chapter is helpful and increases focus as you actively look for points to underline.
Write in books.
- As you read and underline, write notes in the margins. These notes can include key ideas, questions, or indications if you don't understand a section or disagree with something.
- Notes are often single words or short phrases, like "Habit Stacking" when reading Atomic Habits. These words stand out when you revisit a section or chapter, keeping your mind engaged.
- For digital readers (like on a Kindle), keep a notes app open on your phone to jot down words or phrases related to the chapter. (A separate source comment also notes that Kindles allow unlimited marginal notes without needing a separate app).
Briefly summarize each section or chapter immediately after you have read it.
- Keep a notebook for reading notes, where you can write the date, book title, and chapter. Highlighting different books with different colors can help distinguish ideas from various books.
- Immediately after finishing a chapter or section, briefly summarize it in your own words, keeping it short (1-3 sentences). Putting ideas into your own words helps formulate thoughts and allows you to test your understanding of the concepts.
Talk to others or teach someone else.
- Tell someone else about what you are reading and learning. This verbal processing forces your mind to recall what you have read and put the pieces together, leading to greater retention.
Write reviews or summaries.
- After finishing a book, write a review or a summary. It doesn't need to be elaborate; the goal is to start the process of putting thoughts on paper or keyboard to let your mind work through what you've learned. Try to recall key plot points, ideas, and quotes, referencing your notebook notes and margin annotations.
- Summarize what you've read and ideas you'd like to incorporate into your life. For nonfiction, try to apply one idea into your life. Another comment also suggests writing a summary paragraph of each chapter and then summarizing those in a review.
Additionally, bonus tips:
- Re-read classic or deeper non-fiction books, as they are often meant to be revisited and "wrestled with".
- Listen to podcasts or interviews with the author (especially for nonfiction) after reading the book, as authors may provide more context or better explanations in an interview format.
Write Everything Down (and not in your notes app) - Megan, Typewriter Time [Link]
The author found that digital notes were easily forgotten and lacked the tangible connection and memory associated with handwriting. By shifting to a dedicated creative writing notebook, the author experienced improved recall, a more thoughtful writing process, and a stronger connection to their ideas and progress. The piece advocates for the benefits of physical writing for creative endeavors and personal reflection, highlighting how it fosters a deeper engagement with one's own thoughts and creations, a sentiment echoed by the included comments.
Suggestions:
- Switch to handwriting everything in notebooks instead of using your phone.
- Use a dedicated notebook for creative writing only.
- Write down ideas and pieces by hand.
- Constantly flip back through the pages of your physical notebook.
- Write out observations about your growth and areas for improvement directly within the same notebook.
- Create an index in your notebook so you can find things easily.
- Tab pages of importance.
- Scratch out things when you're stuck or frustrated. This allows for a "messy and alive" notebook that reflects the organic nature of the creative process, unlike the clean digital interface.
Brookfield: Undervalued Giant In An Overvalued Market! - Capitalist Letters [Link]
Context Engineering: Bringing Engineering Discipline to Prompts - Addy Osmani, Elevate [Link]
Context engineering components:
- Systemic Approach: It's a system, not a one-off
prompt, where the final prompt is woven together programmatically from
multiple components (e.g., role instruction, user query, fetched data,
examples).
- Dynamic and Situation-Specific: Context assembly
happens per request, adapting to the query or conversation state. This
involves including different information depending on the situation,
such as a summary of a multi-turn conversation or a relevant excerpt
from a document.
- Blending Multiple Content Types: It covers
instructional context (prompts, guidance, examples), knowledge context
(domain information, facts via retrieval), and tools context
(information from tool outputs like web searches or database
queries).
- Format and Clarity: It's about how information is presented, not just what is included. This means compressing and structuring information for the model's comprehension, using formatting like bullet points, headings, JSON, or pseudo-code, and labeling sections (e.g., "Relevant documentation:").
You can learn anything in 2 weeks - Dan Koe, Puture / Proof [Link]
- "skill acquisition = technique stacking." Instead of trying to learn an entire skill (like playing the guitar or Photoshop), you should focus on specific techniques needed for a direct purpose.
- "pure focus" as the missing ingredient for rapid learning. To achieve this, he suggests "tactical stress" – putting yourself in a high-pressure situation with a strong deadline that forces you to learn quickly to avoid negative consequences. This pain of the current situation outweighs the pain of learning, propelling you forward.
How to instantly be better at things - Cate Hall, Useful Fictions [Link]
Suggestions:
- Mimic others, especially those better than you.
- Simulate the thinking of experts: Even without direct observation of someone's thoughts, you can improve by asking yourself "what would a better [chess player/person/etc.] do?"
- Mimic generally competent individuals for new tasks
- Ignore existing standards and aspire to a higher level: Recognize that many skills are "pre-competitive," meaning current standards don't reflect the full potential. Aim to be better than anyone you've ever seen, rather than just slightly better than those around you. This involves a commitment to rigorous effort and exploration beyond perceived limits.
Cultivating a state of mind where new ideas are born - Henrik Karlsson, Escaping Flatland [Link]
Techniques to maintain the creative state
- Ritualistic work habits: Establishing consistent routines for creative work (e.g., daily writing sessions at a specific time and place) can induce a state akin to self-hypnosis, fostering a non-judgmental zone.
- Delaying exposure: Introducing a long delay between creation and public presentation can reduce self-censorship, as the creator feels detached from immediate judgment.
- Viewing work in religious terms: Framing the creative process as a service to a higher power can provide the necessary awe and daring to push into the unknown.
- Strategic collaboration: Working with supportive, open-minded collaborators who challenge rather than conform can be beneficial.
- Subverting expectations: Actively seeking out ideas or approaches that feel slightly uncomfortable or that one might be "ashamed of liking" can lead to truly original work.
- Working at speed: Forcing oneself to produce work rapidly can bypass self-censorship and allow raw, unfiltered ideas to emerge.
Where do Tech Returns Come From? - Eric Flaningam, Generative Value [Link]
The article suggests that successful technology investing requires embracing uncertainty, understanding the "base rates" of different company categories, recognizing where true differentiation lies (often beyond just technology), viewing market size from a first-principles perspective, and being aware of the unique opportunities unlocked by new technology waves.
- The next \(\$100B\) company will not look like the last: Value in technology is driven by "anomalous" companies founded by "anomalous" people, making pattern matching ineffective. The most successful companies create new categories.
- Know the game you’re playing: Different categories have different "Slugging Ratios" (Value/Company). Consumer companies, often network-driven marketplaces with winner-take-all dynamics, have the highest upside, while Hardtech companies also have high slugging ratios but are riskier. Enterprise software, while less "Power Lawed," offers more predictable returns and is suitable for an expanding venture capital landscape due to its scalability, moats, and lower operating costs.
- Software is like chicken, 80% of it tastes the same: Technical differentiation in enterprise software is often nuanced. Sales, marketing, and building "mindshare" are as, if not more, important than technical moats, especially as software becomes easier to build and features are quickly replicated. The "GPT Wrapper" argument for AI applications is analogous to how many successful enterprise software companies were essentially "database wrappers."
- “Market size” may be the single greatest reason for investors missing great companies: Humans struggle with uncertainty, and new markets introduce exactly that. Many successful companies like Palantir, Shopify, and Uber created new markets that didn't exist before, leading to investors underestimating their potential market size. Companies with "multiple-expansion tailwinds" and strong platforms also tend to be underestimated.
- Companies resemble the technology waves they ride in on: New technology waves (internet, mobile, cloud, AI) unlock the ability for new businesses to exist. AI, for example, is enabling anyone to create software and automate voice/text-based workflows, expanding the market significantly and allowing for the creation of entirely new categories (e.g., legal software companies like Harvey reaching \(\$5B\)+ valuations quickly).
- Don't underestimate the Power Law, ever: While mentioned throughout, this point emphasizes the extreme concentration of value in a very small number of companies. The article states that the top seven companies in its dataset accounted for nearly 50% of the \(\$13\) trillion in value creation.
The Great Mental Models: Visual Book Summary - DoubleThink [Link]
The Map is Not The Territory: This model highlights that maps (including mental models) simplify reality and are imperfect reductions of what they represent. While useful, they lack perfect fidelity and should be used carefully, as the real world is complex.
Circle of Competence: Emphasizes the importance of knowing what you know and, critically, what you don't know. It's dangerous to incorrectly assume knowledge. The advice is to operate within your area of expertise and outsource the rest.
Falsifiability: States that for a theory to be confirmed, it must be challengeable. Instead of trying to prove a theory correct, one should try to prove it incorrect. A theory becomes stronger when rigorous experimentation fails to disprove it.
First Principles Thinking: Involves breaking down a problem into its fundamental, non-reducible parts to challenge pre-existing assumptions. It's an effective way to clarify and approach complex problems by building solutions from the bottom up, often using techniques like Socratic Questioning and the Five Whys.
Thought Experiment: Refers to mentally simulating situations to test theories or reach conclusions, rather than conducting physical experiments. It allows for gaining confidence in answers, as illustrated by comparing hypothetical basketball games.
Necessity and Sufficiency: Explains that having all necessary conditions does not guarantee all sufficient conditions are met. Meeting necessary conditions might make success possible, but it doesn't assure it (e.g., knowing how to write vs. being a New York Times Bestseller).
Second-Order Thinking: Encourages looking beyond immediate consequences to consider the "consequence of the consequence" or further. It involves thinking several steps ahead to avoid short-term positive decisions that lead to long-term negative effects.
Probabilistic Thinking: Acknowledges that the future cannot be predicted perfectly, but this model helps improve the accuracy of guesses using three main concepts:
- Bayesian Thinking: Using all relevant prior information for informed decisions in unfamiliar scenarios.
- Fat-Tailed Curves: Understanding that the more extreme scenarios are possible, the higher the likelihood of any one of them occurring.
- Asymmetries: Assessing the probability that your estimates accurately reflect the real world.
Correlation vs. Causation: Highlights that a correlation between two things does not necessarily mean one causes the other. Large datasets can yield strong correlations purely by chance, as demonstrated by the unrelated alignment of Walgreens customer satisfaction and Russell Crowe's movie appearances.
Inversion Principle: A thinking tool that involves approaching a situation from the opposite end of the usual starting point to reframe a problem into a solution (e.g., "make money" becomes "avoid going into debt").
Hanlon’s Razor: Suggests that one should "never attribute to malice that which can be adequately explained by stupidity." It implies that actions that seem ill-intended are often accidents or misunderstandings, and the explanation assuming the least intent is most likely correct.
Occam’s Razor: States that when multiple explanations are possible, the one that makes the fewest assumptions is generally the most probable and closest to the truth. In essence, the simplest explanation is usually the correct one.
Amazon: Betting The Farm - App Economy Insights [Link]
Tesla: From Bad to Worse - App Economy Insights [Link]
On the EV Landscape (specifically Tesla's automotive business):
- The author highlights that Tesla's year is going "from bad to worse". Global deliveries have fallen by 13%, marking their steepest quarterly drop ever.
- Tesla's revenue is declining, margins are compressing, and cash flow has dried out. Automotive revenue specifically fell by 16% year-over-year. The author notes that "Q2 results remain very poor" if Tesla is viewed purely as an auto business.
- Historically strong margins, supported by gigafactory scale, direct-to-consumer sales, and minimal marketing costs, are now being eroded by price cuts and rising competition.
- A return to growth, which was predicted earlier in the year, now "looks unlikely". The company has also withheld full-year guidance due to factors like trade policy and political backlash, adding to the uncertainty.
- The author expresses concern about "mounting evidence of brand erosion".
On the AV Landscape (specifically Tesla's Robotaxi program):
- The author acknowledges that Tesla's robotaxi program "could unlock tremendous value". Elon Musk himself emphasizes that "autonomy is the story" for Tesla.
- Despite its significant potential, the author cautions that even if these "moonshots in robotaxi and robotics succeed," they are "years away from offsetting collapsing vehicle demand". This indicates that the robotaxi program is not seen as an immediate solution to Tesla's current financial woes in its automotive segment.
- The robotaxi program faces considerable regulatory hurdles.
- The author raises a critical question about whether the ongoing "brand erosion" could "undermine even the most ambitious upside" of the robotaxi program.
- The author foresees an "upcoming robotaxi war" among Big Tech companies, suggesting a highly competitive environment for autonomous vehicles.
Microsoft: AI Crossroads - App Economy Insights [Link]
Figma Files for IPO - App Economy Insights [Link]
Figma's Current State and Potential:
- The author asserts that Figma is "not just a great product—it’s a great business" and describes its growth since monetizing in 2017 as "one of the most explosive runs in SaaS history".
- Figma achieved $ $749$ million in FY24 revenue, up 48% year-over-year, with over 1,000 customers paying \(\$100\)K+ annually, and 95% of Fortune 500 companies using Figma. The author considers its product-led, freemium "Land and Expand" growth model to be "hard to manufacture—and even harder to replicate".
- The author highlights Figma's transformation "from a design tool into a full-stack product platform". It is "evolving into a full product development suite", with new tools like FigJam, Dev Mode, and Figma Make (AI-driven prototyping) expanding its reach across the entire product lifecycle.
- Figma is positioned as a "productivity platform disguised as a design tool", which, in the author's view, separates it "from legacy tools and what opens the door to much broader enterprise budgets" by serving designers, engineers, product managers, marketers, and executives.
- Figma's "web-first" and "multiplayer by default" approach gave it a "distinct edge over incumbents like Adobe".
Figma's Uncertainty and Challenges:
- The author notes the collapse of the \(\$20\) billion Adobe acquisition due to "antitrust concerns in the US, UK, and Europe". While Figma received a "\(\$1\) billion breakup fee" and regained independence, this past scrutiny highlights a challenging regulatory environment that companies of Figma's scale can face.
- The author points out a significant "catch" in Figma's reported net dollar retention of 132% in Q1 FY25. They state that the metric "only includes customers still spending over \(\$10,000\) today, then looks back at what those same customers were spending a year ago." This indicates a potential lack of clarity or transparency in how a key growth metric is presented, which could be an uncertainty for investors trying to assess actual customer retention.
Articles and Blogs
How we built our multi-agent research system - Anthropic [Link]
Building the Hugging Face MCP Server - Hugging Face [Link]
Claude for Financial Services - Anthropic [Link]
Cursor on Web and Mobile - Cursor [Link]
How to Build an MCP Server in 5 Lines of Python - Hugging Face [Link]
Claude Code in Action - Anthropic [Link]
This is a 10-lesson guide covering GitHub automation, custom workflows, and MCP integration. Teaches you how to use Claude Code to automate dev tasks in 36 minutes.
Papers and Reports
A Survey of Context Engineering for Large Language Models [Link]
YouTube and Podcasts
Grok 4 Wows, The Bitter Lesson, Elon's Third Party, AI Browsers, SCOTUS backs POTUS on RIFs - All-In Podcast [Link]
Trump vs Powell, Solving the Debt Crisis, The $10T AGI Prize, GENIUS Act Becomes Law - All-In Podcast [Link]
Silicon Valley Insider EXPOSES Cult-Like AI Companies | Aaron Bastani Meets Karen Hao [Link]
Karen Hao, an expert in mechanical engineering and journalism, provides a comprehensive critique of the A industry, detailing her opinions, arguments, and proposals across various topics during the interview.
Understanding AI and its Definition
- Hao argues that the term "artificial intelligence" is poorly defined and was originally coined in 1956 by John McCarthy to attract more attention and funding for his research, essentially as a marketing term. She notes that while AI generally refers to recreating human intelligence in computers, there is no scientific consensus on what human intelligence is, contributing to the term's ambiguity.
- AI serves as an "umbrella" term encompassing various technologies that simulate human behaviors or tasks, ranging from Siri to ChatGPT, which operate on vastly different scales and have different use cases. Hao uses the analogy that AI is like the word "transportation" to illustrate its vagueness: just as "transportation" can refer to bicycles or rockets, AI can refer to vastly different technologies with different purposes and costs. She finds it frustrating and unproductive when politicians use the term vaguely, suggesting it means "progress" without specifying the type of AI or its potential costs, which she compares to promoting rockets for commuting when more efficient alternatives exist.
Environmental and Public Health Costs of AI Development
- Hao emphasizes that the resource consumption required to develop and use generative AI models is quite extraordinary. She cites a McKinsey report projecting that within the next five years, current data center and supercomputer expansion for AI will require adding around half to 1.2 times the amount of energy consumed in the UK annually to the global grid. A significant portion of this energy will be serviced by fossil fuels, including natural gas and the extended lives of coal plants.
- Hao highlights that this acceleration not only impacts the climate crisis but also exacerbates public health crises, citing Elon Musk's xAI's Colossus in Memphis, Tennessee, which is powered by 35 unlicensed methane gas turbines pumping toxic air pollutants into the community. She argues that "unlicensed" means the company completely ignored existing environmental regulations.
- She stresses the undertalked about issue of water consumption: AI data centers require fresh, potable water for cooling to prevent corrosion and bacterial growth, often using public drinking water infrastructure. She notes that two-thirds of new AI data centers are being built in water-scarce areas, providing the example of Montevideo, Uruguay, where Google proposed a data center during a historic drought.
The Business Case and Ideology Driving AI
- Hao contends that the business case for AI is currently unclear, noting that even Microsoft has started pulling back investments in data centers and its CEO, Satya Nadella, has expressed skepticism about the "race to AGI". She argues that what drives the fervor in the absence of a clear business case is an ideology or a "quasi-religious fervor". People genuinely believe in the ability to fundamentally recreate human intelligence, seeing it as the most important civilizational goal.
- She explains that this ideological drive from startups like OpenAI and Anthropic pressures larger, more traditional tech giants to invest heavily, as shareholders demand an AI strategy, often due to consumer shifts (like using ChatGPT as search). Hao explains that OpenAI's pitch to investors is that funding could lead to being the first to AGI for "the biggest returns you've ever seen" or, failing that, could automate human tasks to replace labor, generating significant returns.
- She warns of a "bandwagon mentality" among investors. Crucially, she highlights that if the AI bubble pops, the risk is not just for Silicon Valley but will have ripple effects across the global economy, as investments often come from public endowments.
OpenAI's Origins and Sam Altman's Leadership
- Hao reveals that OpenAI started as a nonprofit in late 2015, co-founded by Elon Musk and Sam Altman, as an "anti-Google" initiative to conduct fundamental AI research without commercial pressures. Musk specifically feared Google's DeepMind could lead to AI going "very badly wrong" (sentience, harming humans). The original "open" in OpenAI stood for open source, and for its first year, the company genuinely open-sourced its code and research. Hao speculates that the nonprofit status was a recruitment tool to attract talent, as they couldn't compete with Google's salaries but could offer a compelling sense of mission. However, within less than a year, the bottleneck shifted from talent to capital, leading to the decision to convert to a for-profit entity. This shift also led to a falling out between Musk and Altman over who would be CEO.
- Regarding Sam Altman, Hao portrays him as a "master manipulator" and "understander of human psychology". She notes that Altman was not publicly well-known but was a critical "lynchpin" within the tech industry, having cultivated relationships with powerful networks and policymakers early in his career as president of Y Combinator. Hao states that people who worked with Altman consistently told her they didn't know what he truly believed because he would often say he believed what the person he was talking to believed, even if those beliefs were diametrically opposed. She concludes that Altman's comparative advantages as a leader include his ability to persuade people to join his "quest," acquire necessary resources (capital, land, energy, water, laws), and instill a powerful sense of belief in his vision among his team. She describes his work as being most effective in one-on-one meetings where he can tailor his message to achieve his goals.
Critique of Big Tech as a Corporate Empire
- Hao argues that if allowed to expand unfettered, these corporate empires will ultimately erode democracy. Hao states that tech leaders view the rest of the world, including other Western countries, as "resources"—territories from which to acquire land, labor, minerals, energy, and water for their data centers. She highlights that data center expansion often targets economically vulnerable communities in rural areas of the US and UK, which are often uninformed about the true costs, such as bans on new housing construction due to massive electricity consumption, or the depletion of fresh water supplies. Hao laments that politicians are often unaware of these negative consequences.
- She argues that the idea that "you need colossal data centers to build AI systems" is a "false trade-off". Before OpenAI, AI research was trending towards "tiny AI systems" requiring little computational resources, showing that AI innovation can occur without these massive, resource-intensive approaches. Hao points out that most AI experts today are employed by these companies, which she likens to climate scientists being bankrolled by oil and gas companies, leading to biased information that serves the company's interests rather than scientific grounding.
Exploitative Labor Practices
- Hao exposes grueling exploitative practices in the global AI supply chain, particularly regarding content moderation for OpenAI. Kenyan workers were contracted to sift through "reams of the worst text on the internet," including child sexual abuse, hate speech, and violent content, to build content moderation filters for ChatGPT. She details how this work traumatized workers, causing PTSD, personality changes, and family breakdowns, like the story of Moffat, whose family left him due to his changed demeanor. These workers were paid only a few dollars an hour.
- She also discusses data annotation, a long-standing part of the AI industry. Venezuelan refugees in Colombia, highly educated but desperate due to their country's economic crisis, became cheap labor for labeling data for self-driving cars and retail platforms. Hao describes the structural exploitation where workers compete for tasks on platforms, leading to immense anxiety and control over their lives, exemplified by a woman who wouldn't walk outside during weekdays for fear of missing tasks and would wake up at 3 AM if an alarm signaled a new task. She asserts that there is no moral justification for why these workers, whose contributions are critical, are paid pennies while company insiders receive multi-million dollar compensation packages; the only "justification" is an ideological one that some people are superior.
Proposals for Public Action and Shaping the Future of AI
- Hao believes that anyone in the world can take action to shape the AI development trajectory. She proposes thinking of AI development as a "full supply chain of AI development", where various resources (data, land, energy, water) and deployment spaces (schools, hospitals, offices) are points of democratic contestation.
She suggests the public can reclaim ownership over resources. She encourages people to contest the spaces where AI is deployed. Hao also advises people to research AI technologies and vendors to make informed choices about which AI systems to use.
She expresses optimism that widespread, democratic contestation at every stage of the AI development and deployment pipeline can "reverse the imperial conquest of these companies" and lead to a more broadly beneficial trajectory for AI.
How to Gamify Your Life (And Reinvent Yourself ... Fast) - Dan Koe [Link]
The Future of Work (How to Become AI-First) - Dan Koe [Link]
Winning the AI Race Part 1: Michael Kratsios, Kelly Loeffler, Shyam Sankar, Chris Power [Link]
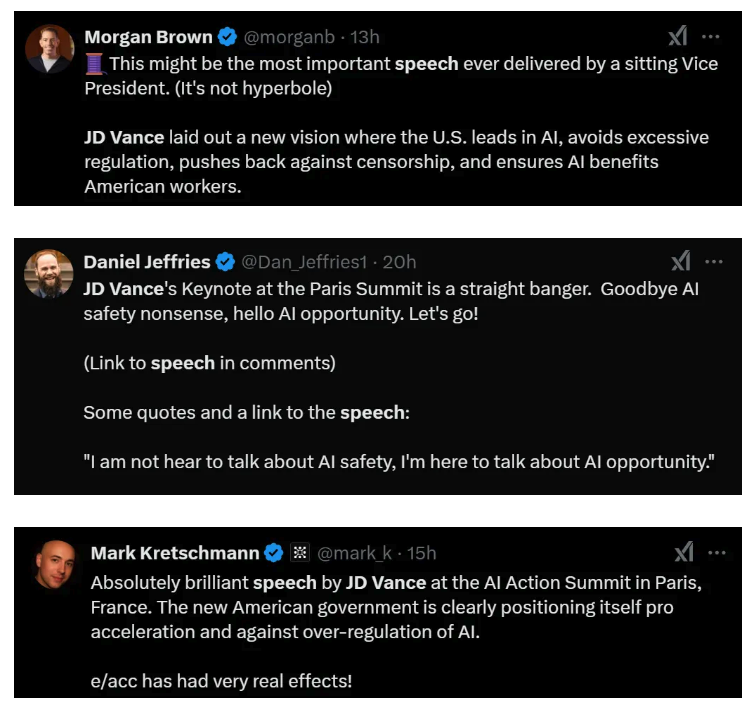
Winning the AI Race Part 2: Vice President JD Vance [Link]
Winning the AI Race Part 3: Jensen Huang, Lisa Su, James Litinsky, Chase Lochmiller [Link]
Turbo-Scaling GenAI at DoorDash: From Product Knowledge Graph to Real-Time Personalization - Predibase [Link]