2024 October - What I Have Read
Substack
This new
model.out_headoutput layer has itsrequires_gradattribute set toTrueby default, which means that it’s the only layer in the model that will be updated during training. Technically, training the output layer we just added is sufficient. However, as I found in experiments, finetuning additional layers can noticeably improve the predictive performance of the finetuned model.― Building A GPT-Style LLM Classifier From Scratch - Sebastian Raschka [Link] [Github]
Interesting questions addressed by Sebastian:
Do we need to train all layers?
“For classification finetuning, it is not necessary to update all layers in an LLM. (The fewer weights we update, the faster the training will be because we don’t need to compute the gradients for these weights during backpropagation.)”
Why finetuning the last token, not the first token?
“In contrast to BERT, GPT is a decoder-style model with a causal attention mask. This means the first token has no context information of any other token in the input. Only the last token has information about all other tokens. Hence, if we want to use models like GPT for classification finetuning, we should focus on the last token to capture contextual information of all other input tokens.”
How does BERT compare to GPT performance-wise?
“The small GPT-2 model from the previous section and BERT performed similarly well on the spam classification dataset. “
Should we disable the causal mask?
“A core feature of the GPT architecture is the causal attention mask (different from BERT models or the original transformer architecture). However, we could actually remove the causal mask during classification finetuning, which would allow us to finetune the first rather than the last token since future tokens will no longer be masked, and the first token can see all other tokens.”
What impact does increasing the model size have?
The prediction accuracy can improve significantly with larger models.
What improvements can we expect from LoRA?
Both full finetuning (all layers) and LoRA can result in the same test set performance.
“On the small model, LoRA is slightly slower since the additional overhead from adding LoRA layers may outweigh the benefits, but when training the larger 1.5 billion parameters model, LoRA trains 1.53x faster.”
Padding or no padding? [experiments]
“If we want to process data in batches during training or inference (this involves processing more than one input sequence at a time), we need to insert padding tokens to ensure that the training examples are of equal length.
In regular text generation tasks, padding doesn’t affect the model response since padding tokens are usually added to the right side, and due to the causal mask discussed earlier, these padding tokens don’t influence the other tokens. However, remember that we finetuned the last token, as discussed earlier. Since the padding tokens are to the left of this last token, the padding tokens may affect the result. “
These Are The 6 Best Science-Based Study Strategies - Super Learning Lab [Link]
Spaced Practice
Instead of cramming all the information at once, spaced practice consists of revisiting the material multiple times with breaks in between.
Interleaving
This is about studying different topics in a sequence.
Retrieval
This consists of bringing learned information from mid to long-term memory by recall or retrieval practices.
Elaboration
Elaborative interrogation consists of asking and explaining why and how things work based on prior knowledge. In other words, it involves connecting new information to preexisting knowledge.
Concrete Example
When learning abstract concepts it was found that illustrating these topics with specific examples improves learning.
Dual Coding
Dual coding is about combining words with visuals. If you use relevant and helpful images in your notes, you may increase learning by remembering what you study with the help of these images.
The \(\$120\) billion wagered on sports betting in America in 2023 translated into nearly \(\$11\) billion in revenue for sports betting companies. This corresponds to the ~9% fee sportsbooks keep after all bets have been settled.
- Flutter: Leverages FanDuel’s dominance and global expertise.
- DraftKings: Focuses on innovation and user engagement to fuel growth.
- Entain: Bets on BetMGM’s success in the US market.
- Penn: Leverages the ESPN partnership to challenge established players.
― Sports Betting Economics - App Economy Insights [Link]
For decades, companies have outsourced their organizational innovation to consultants or enterprise software vendors who develop generalized approaches based on what they see across many organizations. That won’t work here, at least for a while. Nobody has special information about how to best use AI at your company, or a playbook for how to integrate it into your organization.
― AI in organizations: Some tactics - One Useful Thing [Link]
Issues with AI at the organizational level and how to solve them.
- In many companies, there is little AI use and few productivity gains outside of narrow permitted use cases. That’s because AI use that boosts individual performance does not always translate to boosting organizational performance for a variety of reasons. To get organizational gains requires R&D into AI use and you are largely going to have to do the R&D yourself.
- “Many key breakthrough innovations come not from central R&D labs, but from people actually using products and tinkering with them to solve their own problems. “ (Prof. Eric von Hippel). As users are very motivated to make their own jobs easier with technology, they find ways to do so. The user advantage is especially big in experimenting with Generative AI because the systems are unreliable and have a jagged frontier of capability. People are experimenting with AI and finding it very useful. But they aren’t sharing their results with their employers.
How to solve the issues? What are the tactics? Talents in the lab should focus on building, not analysis or abstract strategy.
- Build AI benchmarks for your organization. [Anthropic’s guide to benchmarking]
- Build prompts and tools that work.
- Build stuff that doesn’t work… yet.
- Build provocations and magic.
The USA vs Visa - Net Interest [Link]
Key elements of Doha Mekki’s recent antitrust lawsuit against Visa:
- Visa controls over 60% of U.S. debit transactions, with Mastercard far behind at 25%.
- Visa traps merchants with pricing that penalizes them if they don’t process all transactions through Visa.
- Exclusive deals incentivize merchants to use Visa exclusively, reducing competition.
- Visa prevents potential competitors like PayPal and Apple from entering the market by locking them into restrictive agreements.
- Visa has faced antitrust lawsuits since 1971 and maintains a large legal team to manage ongoing cases.
In physics, we study how particles or systems’ units interact and evolve toward stable states. In machine learning, we study how neurons (or artificial neurons) interact to learn patterns directly from data. The connection lies in energy minimization: both approaches define an energy function to describe the stability of a system, and the optimization of this function helps to find optimal configurations that correspond to useful patterns or memories.
Hopfield developed a network that recreates patterns using energy minimization, while Hinton expanded on this with the introduction of Boltzmann machines, statistical physics-based systems that learn to recognize and generate patterns, providing groundwork for modern machine learning.
― Nobel Prize to the Statistical Physics of artificial neural networks - Complexity Thoughts [Link]
“The laws governing physical systems also apply to the world of artificial intelligence.”
Major AI Functionalities / with Apps - AI Supremacy [Link]
A list of AI products you can experiment with.
Fine-tuning can be useful for certain tasks (see the relevant section here for more details), but when it comes to injecting morality into your LLM, it’s probably not a good bet.
By combining the strengths of diffusion models and auto-regressive generation, DGLM offers a more nuanced, adaptable, and potentially more effective approach to generating safe and creative text. It moves away from the brute-force, one-size-fits-all approach of fine-tuning and embraces a more modular, dynamic, and personalized approach to AI safety.
― A New Way to Control Language Model Generations [Breakdowns] - Artificial Intelligence Made Simple [Link]
The author lists drawbacks of fine tuning:
“A model’s knowledge and capabilities are learnt almost entirely during pretraining, while alignment teaches it which subdistribution of formats should be used when interacting with users.” - LIMA: Less Is More for Alignment [Link]
“Our findings reveal that while unsupervised fine-tuning offers some improvement, RAG consistently outperforms it, both for existing knowledge encountered during training and entirely new knowledge. Moreover, we find that LLMs struggle to learn new factual information through unsupervised fine-tuning.” - Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs [Link]
“Disconcertingly, our research also reveals that, even without malicious intent, simply fine-tuning with benign and commonly used datasets can also inadvertently degrade the safety alignment of LLMs, though to a lesser extent. These findings suggest that fine-tuning aligned LLMs introduces new safety risks that current safety infrastructures fall short of addressing — — even if a model’s initial safety alignment is impeccable” - Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To! [Link]
“The base model generates a wide range of nationalities, with American, British, and German being the top three. In contrast, the aligned model only generates three nationalities: American (highest percentage), Chinese, and a small percentage of Mexican.” - Creativity Has Left the Chat: The Price of Debiasing Language Models [Link]
Just do it! Brand Name Lessons from Nike’s Troubles - Musings on Markets [Link]
Brand value is often mixed with other advantages like scale, network effects, and product differentiation. Strong brands yield higher revenues, pricing power, and potentially lower capital costs. And it’s hard to separate brand value in companies with multiple advantages.
Spotify: Layoffs Pay Off - App Economy Insights [Link]
Key business highlights: 1) Spotify’s new subscription plans - Spotify’s Audiobooks Access ( \(\$9.99\) per month for 15 hours) and Basic (removing audiobooks from Premium) diversify its offerings, 2) Spotify is incorporating social-style discovery features, like Live Listening Parties and prompt-based AI playlists, but remains behind YouTube and Meta in algorithm sophistication and live content, 3) Spotify’s ad-supported ARPU is low (€1.15 vs. Meta’s \(\$11.89\) dollars in Q2), limiting ad revenue potential. A new in-house creative agency may improve brand experiences but is challenging to scale profitably, 4) Spotify pivoted from broad podcasting investments to a case-by-case approach, now pushing video podcasts.
Competitiveness: 1) Hub Entertainment Research shows Spotify’s high ‘must-have’ appeal, with 75% of US users viewing it as “uncancellable.” This loyalty supports Spotify’s growing free cash flow and a valuation around 40 times Free Cash Flow (FCF) —placing it ahead of rivals like YouTube Music (100M subscribers) and Apple Music (estimated 110M by 2025), 2) Despite solid growth, Spotify’s reliance on licensed content and its still-limited ad revenue leave room for competition. While TikTok’s 1B+ users could funnel into TikTok Music, ByteDance recently announced it will close TikTok Music by November, focusing instead on promoting artists and streaming value within the main app—a potential competitive break for Spotify.
Cybersecurity Earnings - App Economy Insights [Link]
Covered Palo Alto Networks, CrowdStrike, Fortinet, Zscaler, and Cloudflare.
Two Nobel Prizes for AI, and Two Paths Forward - Marcus on AI [Link]
Hinton’s focus on end-to-end neural networks can be limiting, especially when considering the complexities of real-world problems that often require more structured and hybrid approaches. On the other hand, Hassabis’s embrace of neurosymbolic AI reflects an openness to different methodologies and a recognition that a combination of techniques may yield better results.
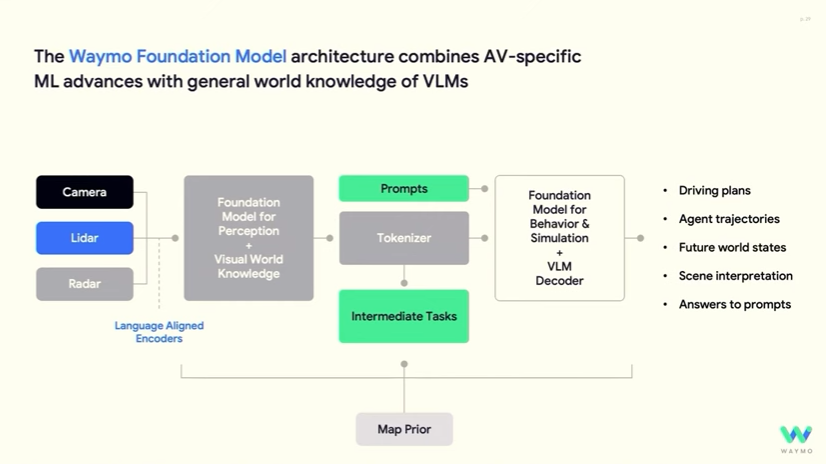
First, Waymo is using transformer-based foundation models for all stages of its self-driving pipeline: perception, prediction, and planning. Second, the whole system is trained end to end. During training, gradients from the behavior network propagate backwards to the perception network.
So I see more similarities than differences in the evolution of Waymo and Tesla’s self-driving software. Both companies made little to no use of neural networks in their early systems. Both companies started using neural networks for perception in the late 2010s. And both companies only recently shifted to end-to-end architectures that used neural networks for all stages of the self-driving pipeline.
― Elon Musk wants to dominate robotaxis—first he needs to catch up to Waymo - Understanding AI [Link]
Tesla’s advantages compared to Waymo:
- Tesla already has millions of vehicles on the road, which could quickly deploy robotaxi software without the need for new hardware.
- Tesla relies on cost-effective, camera-based perception without expensive sensors like lidar, which Waymo uses. This could lower Tesla’s per-vehicle cost and allow it to expand more rapidly if autonomy is achieved.
- Tesla’s transition to a full, end-to-end neural network approach for perception, prediction, and planning has improved FSD’s ability to handle complex driving situations without manual coding for specific scenarios.
Tesla’s disadvantages compared to Waymo:
- Tesla hasn’t deployed a fully driverless car yet, while Waymo has offered driverless rides since 2020.
- Tesla would need extensive infrastructure to maintain a robotaxi network (for charging, cleaning, and repairs) which it currently lacks. Building this up in cities nationwide would take time, resources, and logistical planning.
- Tesla’s camera-only approach may struggle in certain conditions (e.g., low visibility), which lidar could handle better.
Key Contribution of AI to Robotics:
- Improved Reasoning and Planning: Large language models, like those developed by OpenAI and Google, are enabling robots to interpret high-level commands, understand contextual instructions, and execute complex, multi-step tasks. This is particularly valuable in dynamic environments where robots must adapt to unforeseen changes and make real-time decisions.
- Enhanced Visual and Motor Coordination: The integration of generative AI with visual and motor feedback systems allows robots to translate visual inputs into precise motor actions. This enables robots to perform tasks such as picking and placing objects with greater accuracy and efficiency, even in environments that are constantly changing.
- Natural Language Interfaces: AI-driven natural language interfaces are making it easier for users to interact with robots using everyday language rather than programming code. This democratization of robotics makes it accessible to non-technical users, paving the way for broader adoption across industries.
- Predictive Maintenance: AI models analyze real-time data from robots to predict potential malfunctions, enabling proactive maintenance that minimizes costly downtime and enhances operational efficiency.
― Generative AI and Robotics in 2024 - AI Supremacy [Link]
Glue: The less-glamorous stuff that helps a team succeed
Strike the right balance between glue and core work. Do enough glue work to show leadership promotable artifacts, but not too much to where your core work suffers.
Lead meetings, take notes, and share them to provide value to the right stakeholders.
Send your manager monthly recaps of your accomplishments so they can more easily sponsor you and your work.
Grit: The will to pursue a long-term goal despite challenges
Break your projects into achievable milestones so you can constantly feel progress, even for long projects.
View failures as progress. It’s one less route you need to explore now.
Take breaks and work in fun. I set up icebreakers at the start of our meetings, organized team events, and pushed for production freezes.
Friction: The gap between reality and the ideal state
Find ways to unblock yourself and the people around you. Do this enough, and you’ll have mastered removing friction.
Removing friction paints you as a force multiplier. Force multipliers get promoted.
― 3 Career Principles that got me to Director at Google - High Growth Engineer [Link]
- Processing Fluency: The ease with which information is perceived and processed by the human mind. High fluency can lead to positive evaluations, even if the information is not accurate.
- Halo Effect: A cognitive bias where a positive overall impression of something (e.g., an LLM’s fluency) influences the evaluation of its individual attributes (e.g., truthfulness).
- Inter-rater Agreement (IRA): A measure of how much two or more evaluators agree on their assessments. Low IRA indicates potential problems with the evaluation design or guidelines.
- Extrinsic Evaluation: Assessing the impact of an LLM’s output on an end-user task or system (e.g., measuring productivity gains from using an LLM-powered email assistant).
- Intrinsic Evaluation: Evaluating the properties of the LLM-generated text itself, such as fluency, coherence, and factual accuracy.
― How Amazon is Rethinking human evaluation for generative large language models [Breakdowns] - Artificial Intelligence Made Simple [Link]
Pretty comprehensive of human evaluation of Gen AI models.
US Banks: Soft Landing? - App Economy Insights [Link]
*A recent pre-print paper found that at least 5% of new Wikipedia articles in August 2024 were AI generated, Facebook isn’t doing anything to stop AI generated images of Hurricane Helene, and Goodreads and Amazon are grappling with various AI generated book schemes scamming people into buying pulp. It’s only the tip of the iceberg.*
― When Models Go MAD - Teaching computers how to talk [Link]
Humm AI is diluting reality. It’s concerning.
Elon Musk’s tech projects are inseparable from his authoritarian one - Blood In The Machine [Link]
Good discussion. Musk has multifaceted role—entrepreneur, political influencer, and media magnate. His activities underscore a model of influence that defies precedent, blending financial might, technological ambition, and political maneuvering. Recognizing the interconnectedness of these efforts is crucial for understanding Musk not just as a private-sector innovator but as a power broker actively shaping the public and political spheres in ways that could redefine norms, values, and who gets to participate in his envisioned future.
YouTube and Podcast
Tesla I don’t think it’s a car company, I think this is misleading, this is a robotics company robotics at Scale Company, because I would say at scale is also like a whole separate variable, they’re not building a single thing, they’re building the machine that builds the thing which is a whole separate thing and so I think robotics at scale company is what Tesla is.
I think with synthetic data you just have to be careful, because these models are silently collapsed, is like one of the major issues so if you go to ChatGPT and you ask it to give you a joke, you’ll notice that it only knows three jokes, that’s the only it gives you like one joke I think most of the time. And sometimes it gives you like three jokes and it’s because the models are collapsed and it’s silent, so when you’re looking at any single individual output, you’re just seeing a single example, but when you actually look at the distribution, you’ll notice that it’s not a very diverse distribution, it’s silently collapsed. When you’re doing synthetic data generation, this is a problem, because you actually really want that entropy, you want the diversity, and the richness in your data set otherwise.
― No Priors Ep. 80 | With Andrej Karpathy from OpenAI and Tesla - No Priors: AI, Machine Learning, Tech & Startups [Link]
Andrej Karpathy was a founding team member of OpenAI and the former Tesla Autopilot leader. He discussed the evolution of self driving cards, tech challenges, Tesla’s Optimus humanoid robot, bottlenecks of AI development today. The topic of how AI capabilities could be further integrated with human cognition sounds very future and funny.
AI prompt engineering: A deep dive - Anthropic [Link]
Some of Anthropic’s prompt engineering specialists—Amanda Askell (Alignment Finetuning), Alex Albert (Developer Relations), David Hershey (Applied AI), and Zack Witten (Prompt Engineering)—share their insights on the evolution of prompt engineering, offer practical advice, and discuss how prompting could evolve as AI continues to advance.
Decoding Google Gemini with Jeff Dean - Google DeepMind [Link]
Jeff Dean, chief scientist of Google DeepMind and Google Research, discusses the past, present and future of AI, specially the long term potential of multi-modal models like Gemini.
Shall We Repeal the Laws of Economics? - Oaktree Capital [Link]
Howard Marks addresses how politicians often ignore economic reality in their campaign promises, using examples like Trump’s call for tariffs and Harris’s attack on grocery profiteering. He emphasizes that economic laws are incontrovertible, and politicians can’t deliver on promises that contradict these laws; free markets allocate resources efficiently. And he highlights the ongoing political refusal to address issues like Social Security insolvency and national debt, stating that ignoring economic laws will eventually lead to negative outcomes.
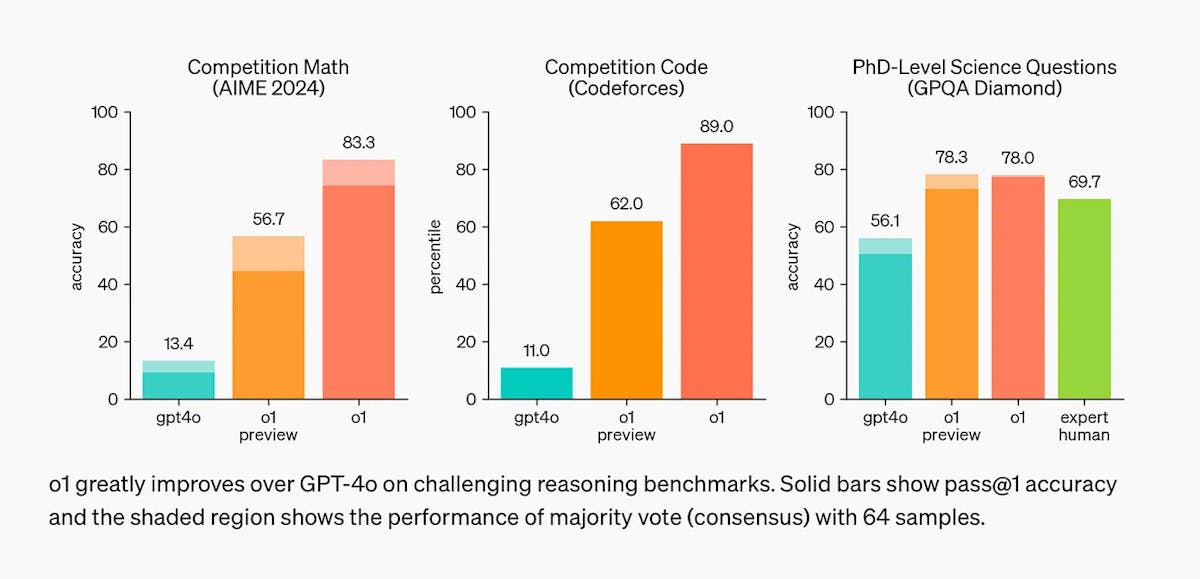
Introducing OpenAI o1 - Open AI [Link]
A series of video from Open AI to introduce GPT o1.
Ep17. Welcome Jensen Huang | BG2 w/ Bill Gurley & Brad Gerstner - Bg2 Pod [Link]
Dueling Presidential interviews, SpaceX’s big catch, Robotaxis, Uber buying Expedia?, Nuclear NIMBY - All-In Podcast [Link]
Meta VS Apple: What Their Battle Means For AI Startups - Y Combinator [Link]
The Waymo Way: Making Autonomous Driving a Reality | Dmitri Dolgov - U-M Computer Science and Engineering [Link]
Sam Altman: The Man Behind ChatGPT | Big Take - Bloomberg Podcasts [Link]
Markets turn Trump, Long rates spike, Election home stretch, Influencer mania, Saving Starbucks - All-In Podcast [Link]
What’s next for AI agentic workflows ft. Andrew Ng of AI Fund - Sequoia Capital [Link]
A fireside chat with Sam Altman OpenAI CEO at Harvard University - Harvard Business School [Link]
Q1: I’m curious how you rebuilt or rediscover momentum after pivoting in a professional or personal sense in terms of your values.
- We have unbelievable greatest technological wave ever, so it’s a great time to be starting out your career. You are going to be flooded with opportunities for the next few years.
Q2: How do you think AI’s role will be in tackling sort of inequalities in education and health care and legal stuff?
- It should reduce inequality.
Q3: Subscription model could be a barrier for startup and small businesses, do you think OpenAI would explore alternative monetization strategy that could include free API access, perhaps supported by advertising or other methods, to foster innovation in the future?
- Sam hates ads in general. Ads + AI is uniquely unsettling to him. He likes the simplicity of OpenAI’s model, which is they make great AI and people pay them for it, and they just do the best they can for people.
Q4: Does the increasing competitors change the way you are evolving for the next products?
- They are just trying to figure out the next paradigm and the next great idea. They don’t pay much attention to the market share though they pay at least attention to competitors to maybe get inspiration.
- Sam’s hope is that every year, they do something amazing that people thought was impossible. Once you know that something is possible and roughly how to do it, it always gets copied quickly. That’s not the hard part. The hard part is figuring out what it is and doing it first when you don’t know it’s possible.
Q5: what do you think the ideal public general education curriculum on AI should look like and what does the average person need to know about AI in the next 5-10 years?
- Computer science major or at least some courses. Being able to train a GPT-2.
Q6: Can you share what’s coming next after transformers? Then the second question is what do you think most entrepreneurs and VCs are getting wrong about the future of AI?
- Most entrepreneurs don’t bet on AI models are going to be massively better so that’s why there is meme that “OpenAI kills my startup”.
Q7: How much exposure does OpenAI and the AI movement have to energy constraints? And what do you think the role is of founders have to play in addressing these concerns?
- It’s necessary to Sam to drive tech abundance from those two key inputs - energy and AI.
Articles and Blogs
Of the employees we studied, those with superior sales performance were genetically different from the rest of the group. They were better at learning in real time about new customers and new sales opportunities. From an initial conversation with a sales lead, they were able to quickly feel out the customer and propose appropriate products without being told what to recommend.
Adaptive learning is different; it isn’t trainable. It’s the ability to process new information in real time and immediately use it to achieve a positive result.
For example, sales teams often require junior employees to cold-call leads, even through they don’t know as much about the company as more experienced employees do. Most of them haven’t even learned how to sell yet. But our research shows that for adaptive learners, seniority and experience are less important. Employees with the sales gene quickly become knowledgeable about your products and are able to learn and adjust on the fly.
― There Really Is a “Sales Gene” - Juan Martinez, Harvard Business Review [Link]
Adaptive learning skill is important but might not correlated with seniority or experience. Employees with this capability can quickly become knowledgeable about the products and are able to learn and adjust on the fly.
The article suggests that managers or companies could be given a snapshot of how many of salespeople are adaptive learners without singling out any individual. and they could tell which tasks require adaptive learning skills and which don’t and allow them to choose. This should be done in an anonymous way.
No matter whether what’s been proposed in this article is applicable or ethical. The idea of adaptive learning is kind of new to me, and it inspires me to further think about whether this skill is learnable and teachable, and think about whether there is any other secret skills in sales.
New Rules for Teamwork - Harvard Business Review [Link]
Develop an Operating System
OS means building blocks for the way team members collaborate, create change, and support one another. Effective operating systems vary widely, depending on the needs and norms of the organization. What they all have in common is that they set out a view of how teams create value, what teams are supposed to achieve, the technical skills each team member is expected to contribute, the processes by which the work will be managed, and the cultural norms and mindsets of constructive collaboration that will guide behavior.
Suggestions: hold kickoffs, conduct one on ones, and take stock of progress using retrospectives, are the three practices as a foundations of team OS.
Invest in Active, Real-Time Measurement
To make teamwork scientific, organizations need to be able to measure the outcomes of their actions and determine how changes in the inputs affect results.
Suggestion: define what constitutes success.
Create a System for Continuous Improvement and Innovation
Teams today have new forms of technology and data collection at their disposal to help them self-correct while projects are underway. e.g. support colleagues to discuss what could have been done better; look at the patterns across teams to identify improvements and share best practices, particularly with regard to the rapid adoption of new technologies such as GenAI.
Suggestions: Identify the metrics that matter most (shift-changeover time, perhaps), hypothesize which actions could improve performance in those areas (preassigned workstations, perhaps), and embed technologies in the operating system (a smart-planning app, perhaps) to enable continuous improvement. Continuous improvement can occur only when all perspectives are considered and all teams have access to a centralized knowledge repository. Finally, it may be useful to set up a center of excellence, staffed with full-time employees with experience in analytics and operating system design.
Why Leadership Teams Fail - Harvard Business Review [Link]
I was reading while thinking about my team and neighbor teams. I find this article very useful.
A critical factor in organizational success: the health of their leadership team. There are three main patterns of dysfunction: Shark Tanks, Petting Zoos, and Mediocracies.
Shark Tanks
Definition: A leadership team marked by hyper-competition, political maneuvering, and infighting. Members prioritize personal agendas over collective goals, leading to toxic and combative dynamics.
Causes: Lack of clear direction or boundaries from the CEO or team leader. Failure to address self-serving behaviors early on. Absence of behavioral norms that encourage collaboration.
Signs: Team members engage in power struggles outside of meetings. One-on-one discussions with the CEO on issues that should be resolved in team settings. Meetings turn into battlegrounds, with frequent arguments and difficulty reaching consensus. Executives bad-mouth each other, form alliances, or resist decisions after they’ve been made.
Prevention:
Clear Expectations: Leaders should explicitly define which behaviors are acceptable and unacceptable. Set boundaries around how competition should be managed.
Confront Self-Serving Behaviors: Address aggressive or toxic behaviors directly with individuals. Remove those unwilling to align with the team’s goals, even if they’re high performers.
Role Modeling: The CEO or team leader must model collaborative behaviors and ensure transparency in communication to prevent political games.
Regular Feedback: Reinforce positive behaviors and correct negative ones through continuous feedback. Implement 360-degree reviews to track team behavior and performance alignment.
Petting Zoos
Definition: A leadership team that avoids conflict to maintain harmony. Vigorous debate is sacrificed, and members prioritize getting along over pushing for the best ideas, leading to complacency and poor decision-making.
Causes: Overemphasis on collaboration and mutual trust, leading to conflict avoidance. Team members are too deferential, fearing that disagreements might disrupt the team’s harmony. Leaders may unknowingly encourage this avoidance by stressing harmony over debate.
Signs: Meetings lack critical debate, and discussions feel muted and lacking in emotional intensity. Team members engage in performance theater, focusing on positive news while downplaying problems. Decisions are made by consensus without sufficient evaluation or challenge. Leaders avoid holding one another accountable for poor performance, reluctant to disrupt the status quo.
Prevention:
- Encourage Debate: Leaders should foster a culture of constructive conflict where members feel safe to challenge each other’s ideas. A foundation of trust and psychological safety is key.
- Promote Data-Driven Discussion: Ensure discussions are rooted in facts, using shared data to spur debate and avoid personal conflict. This encourages neutral, objective decision-making.
- Monitor Meeting Dynamics: Leaders should track participation and the quality of discussion during meetings, encouraging team members to speak up and challenge ideas more openly.
- Redefine Consensus: Teams must understand that consensus does not mean avoiding conflict but making informed decisions after rigorous debate.
Mediocracies
Definition: A leadership team marked by complacency, lacking the drive or skills to achieve high performance. Collaboration and competition are both underemphasized, and the team fails to meet the organization’s needs.
Causes: Long periods of success that breed complacency. Poor alignment between the team’s skills and the changing demands of the business. A divided team, where some members prefer competition while others favor collaboration, leading to inconsistent and ineffective efforts. A leader’s failure to adapt to changing market conditions or internal challenges.
Signs: Team members operate in silos, with little collaboration between departments or units. Decision-making is slow, and there is a lack of accountability for performance. The team focuses on past achievements rather than future goals, with little ambition or drive for improvement. The team struggles with stagnation, missed opportunities, and duplicated efforts due to poor coordination.
Prevention:
- Rebuild the Team: Leaders may need to replace members who are not fit for their roles or who lack the motivation or skills needed to lead effectively. New hires should be chosen not just for their skills but also for their alignment with the company’s purpose and values.
- Promote Balance: Strike a balance between competition and collaboration by hiring individuals with complementary skills and styles (e.g., planners and visionaries alongside hard-nosed executors).
- Clear Roles and Expectations: Define where collaboration is expected (e.g., across departments) and where competition might be useful (e.g., in individual market decisions). Ensure everyone understands their responsibilities and how their performance contributes to broader goals.
- Challenge the Status Quo: Continuously push the team to innovate and grow by setting ambitious goals and holding team members accountable for driving performance improvements.
Without such an observability system–let’s call it Design System Observability–it could be too late when Uber learned through complaints and public media about the end users who would suffer confusing onboarding rides, inconsistent layouts, and frustrating voiceovers/talkbacks sessions.
― How to Measure Design System at Scale - Uber Blog [Link]
RAG is the most popular architecture of the LLM based systems in 2023. There are many products build almost solely on RAG — from Question Answering services combining web search engines with LLMs to hundreds of chat-with-your-data apps.
― Advanced RAG Techniques: an Illustrated Overview - Medium [Link]
Machines of Loving Grace - Dario Amodei, CEO of Anthropic [Link]
This essay aligns with our thinking that while you acknowledge the risks and share concerns over idealistic promises, you also recognize the challenges inherent in building AGI. It reflects an approach to AI that balances ambition with caution, and providing perspectives of how to articulate a vision for AI that remains both ambitious and grounded.
Interesting point: As AI reaches near-universal superiority, the economy may need to adapt fundamentally. Potential solutions range from universal basic income (UBI) to entirely new economic frameworks. Perhaps AIs might manage resources and distribute them according to value systems derived from human input, but such proposals raise ethical and practical concerns. The author hints that the economic transformation required could be as drastic as past societal shifts (e.g. from hunting-gathering to agriculture), suggesting that humanity will have to experiment and iterate to find sustainable models that protect against exploitation or dystopia.
Overall, the author believes that the core human values such as fairness, cooperation, and autonomy have a natural, most ‘’overdetermined’ appeal, and will often lead toward democracy, rule of law, and enlightenment ideals - a trajectory that AI as a catalyst could accelerate by making the path to this “good world” more tangible. While the vision seems intuitive and inspiring to many, it may still appear fantastical or undesirable to others. Even so, the author finds a unique beauty in striving for it, suggesting that our intrinsic human impulses toward collaboration and justice make this vision both plausible and worth pursuing.
Andrew Ng’s writing in The Batch - The Batch [Link]
“The best we can do is a compromise: learn to recognize situations in which mistakes are likely and try harder to avoid significant mistakes when the stakes are high.” ― Daniel Kahneman, Thinking, Fast and Slow
― Unleashing System 2 Thinking? AlphaCodium Outperforms Direct Prompting of OpenAI o1 - qodo [Link]
System 1 thinking: fast responses with surface-level understanding;
System 2 thinking: deliberate methodical and reasoned problem solving.
Introducing the Realtime API - OpenAI Blog [Link]
Developers can now build fast speech-to-speech experiences into their applications
With canvas, ChatGPT can better understand the context of what you’re trying to accomplish. You can highlight specific sections to indicate exactly what you want ChatGPT to focus on. Like a copy editor or code reviewer, it can give inline feedback and suggestions with the entire project in mind.
You control the project in canvas. You can directly edit text or code. There’s a menu of shortcuts for you to ask ChatGPT to adjust writing length, debug your code, and quickly perform other useful actions. You can also restore previous versions of your work by using the back button in canvas.
― Introducing canvas - OpenAI [Link]
Canvas offers a new interface for the project works that require editing and revisions.
Multi document agentic RAG: A walkthrough - LanceDB [Link]
This tutorial shows you how to build a multi-document agentic RAG system using LanceDB and LlamaIndex for complex information retrieval. Specifically, the walkthrough demonstrates how to integrate LLMs, vector databases, and agent-based reasoning for enhanced information retrieval and task completion.
Reports and Papers
Learning vs Retrieval: The Role of In-Context Examples in Regression with LLMs [Link]
The paper explores in-context learning (ICL) mechanisms in large language models (LLMs), focusing on the balance between knowledge retrieval and learning from in-context examples in regression tasks. It reports that LLMs can learn from regression examples of realistic datasets in-context, extending previous work on synthetic data to more practical scenarios.
I’m looking forward to this kind of experiments and studies, because I was suspicious about applying LLM on structured data.
Larger and more instructable language models become less reliable [Link]
The issue might stem from the nature of LLMs, which are designed to generate plausible responses based on patterns in the data they’ve seen, rather than to know anything in the traditional sense. They don’t have an internal mechanism to differentiate truth from fabrication, so as they scale up, they produce more complex, yet not necessarily more accurate, answers. This makes them better at appearing smart, but less reliable overall—a quality that philosophers like Mike Hicks rightly criticize as “bullshitting.”
From a user perspective, it underscores the need for critical thinking when engaging with AI models through prompt engineering. Just because an LLM provides a well-phrased response doesn’t mean it’s accurate.
o1—like previous LLMs—is sensitive to the probability of examples and tasks, performing better and requiring fewer “thinking tokens” in high-probability settings than in low-probability ones.
― When a language model is optimized for reasoning, does it still show embers of autoregression? An analysis of OpenAI o1 [Link]
Although optimized for reasoning, o1 still exhibits probability-based limitations tied to its autoregressive origins, implying that a complete departure from these influences has not been fully achieved.
VideoPrism: A foundational visual encoder for video understanding - Google Research [Link]
Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models [Link]
Astute RAG is designed to better combine internal and external information through an interactive consolidation mechanism (i.e., identifying consistent passages, detecting conflicting information in them, and filtering out irrelevant information).
Differential Transformer - Microsoft Research [Link]
Diff Transformer amplifies attention to relevant context while canceling noise, resulting in outperforming standard Transformers in multiple areas such as long-context modeling, key information retrieval, hallucination mitigation, in-context learning, and reducing activation outliers, as shown in the experiments.
The key innovation is a differential attention mechanism that calculates attention scores by subtracting two separate softmax attention maps. This subtraction cancels out irrelevant attention, promoting sparser, more accurate focus on important information, similar to noise-canceling techniques.
Diffusion Guided Language Modeling [Link]
Controllable language modeling refers to techniques that allow users to guide or control specific attributes of the generated text from a language model (LM). These attributes can include factors like sentiment, toxicity, formality, or any other desired linguistic or stylistic feature. The primary challenge is ensuring that generated content aligns with specific requirements without compromising fluency, coherence, or overall quality of the text.
Diffusion models are excellent for controllable generation. They generate data in a multi-step process, gradually refining noise into coherent content. This incremental approach allows for fine-grained control at various stages of the generation. By manipulating the process at specific steps, you can guide the output more effectively toward desired characteristics (such as sentiment, style, or tone). In contrast, auto-regressive models like GPT generate text token by token in a one-shot manner, making it harder to impose controls without affecting fluency.
DGLM could refine language model generation because it integrates the fluency of auto-regressive language models (like GPT) with the flexibility of diffusion models. This flexibility is realized by employing Plug-and-Play with Linear Classifiers in the Sentence-T5 latent space to guide the diffusion process towards generating proposals with desired attributes.
On the Diagram of Thought [Link]
Researchers from Tsinghua University, led by Andrew Chi-Chih Yao, introduced Diagram of Thought (DoT), designed to enhance the reasoning capabilities of LLMs.
The limitation of CoT is that it processes information in a straight line which does not reflect the way of how humans think. The limitation of ToT or GoT is that they are computationally expensive and challenging to implement within a single LLM.
DoT addresses these limitations by modeling reasoning as the construction of a directed acyclic graph (DAG) within a single LLM. This DAG comprises nodes representing: 1) Propositions: Initial and refined ideas generated throughout the reasoning process, 2) Critiques: Evaluations of propositions, identifying errors or inconsistencies. 3) Refinements: Improved propositions based on critiques. 4) Verifications: Confirmation of valid propositions.
Two key crucial aspect of DoT framework: 1) it leverages auto-regressive next-token prediction with role specific tokens to manage reasoning process within a single LLM, 2) it has strong foundation in math logic - Topos Theory, ensuring logical consistency and soundness in reasoning process.
A Survey on the Honesty of Large Language Models [Link]
Dunning-Kruger effect is named after psychologists David Dunning and Justin Kruger, who first described this phenomenon in 1999. It reveals a troubling mismatch between perception and reality. Those who know little often lack the self-awareness to recognize their limitations. Conversely, experts may be acutely aware of the vastness of their field, leading them to undervalue their own expertise.
Spatial context non-uniformly modulates inter-laminar information flow in the primary visual cortex [Link]
Their research shows that when our field of vision is cluttered, it changes how efficiently our brain processes information, though the basic pattern of information transfer remains the same.
When you give a Claude a mouse - Out Useful Thing [Link]
Some impression on what an agent is capable of.
Agentic Information Retrieval [Link]
Research proposed AI agent on information retrieval (IR) task. Compared to traditional IR, Agentic IR employs a unified, adaptive architecture where agents use observation, reasoning, and actions iteratively to reach the desired user information state. Key methods include prompt engineering, retrieval-augmented generation, multi-agent systems, and reinforcement fine-tuning (RFT).
A Comparative Study on Reasoning Patterns of OpenAI’s o1 Model [Link]
An evaluation study of GPT o1’s reasoning patterns. The study identified six distinct reasoning patterns for o1—Systematic Analysis (SA), Method Reuse (MR), Divide and Conquer (DC), Self-Refinement (SR), Context Identification (CI), and Emphasizing Constraints (EC)—with DC and SR being most common across tasks. And token count varied greatly across tasks, indicating that the o1 model adjusts reasoning depth based on task complexity.
Malla: Demystifying Real-world Large Language Model Integrated Malicious Services [Link]
A study of malicious services powered by LLM ‘Malla’ in the underground marketplaces. (When it comes to AI, everywhere has gaps to bridge lol). Interesting mysteries to uncover:
Who are the pivotal players within the Malla ecosystem?
The Malla ecosystem comprises vendors who create malicious LLM services, users who exploit these services, and platforms that facilitate their operations.
How is Malla orchestrated and monetized?
Malla services generate revenue through direct user transactions, often accepting cryptocurrencies, with some vendors reporting substantial earnings.
What techniques did miscreants deploy to exploit LLMs and build up Mallas?
Miscreants utilize techniques like jailbreak prompts to bypass LLM restrictions and abuse public APIs to generate harmful content.
The minimal versions (minLSTMs and minGRUs) are fully parallelizable during training and use fewer parameters. They are 175x faster to train than traditional LSTMs and GRUs. And their performance is equivalent to Transformers or Mamba with fewer training steps.
The Perfect Blend: Redefining RLHF with Mixture of Judges [Link]
This work is redefining RLHF with Mixture of Judges by Constrained Generative Policy Optimization (CGPO), a novel RLHF framework. The framework uses a Mixture of Judges (MoJ) with rule-based and LLM-based constraints to mitigate reward hacking. As a result, CGPO consistently outperforms PPO and DPO baselines across various benchmarks.
STATE OF AI REPORT 2024 [Link]
This annual publication examines trends in AI research, industry developments, and technological progress. And this year it reveals convergence in AI Model Performance.
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering [Link] [Blog]
As the title described, they introduce MLE-bench as a benchmark for measuring how well AI agents perform at machine learning engineering. The tasks for testing were created by curating 75 ML engineering related competitions from Kaggle. Eventually, OpenAI’s o1-preview with AIDE scaffolding achieves at least bronze medal in 16.7% of competitions.
Github and Docs
Swarm - An educational framework exploring ergonomic, lightweight multi-agent orchestration [Link]
Little experimental and educational multi-agent framework by OpenAI.
Swarm’s Operational Framework:
- Agent Definition: Create Agents with specific instructions, roles, and functions. Each function is automatically converted to a JSON structure for API compatibility.
- Handoff Mechanism: Implement logic for agent transitions. Functions can return a new Agent object to transfer control based on conversation flow or predefined criteria.
- Context Management: Utilize Context Variables to initialize and update shared information throughout the conversation, maintaining state across agent interactions.
- Execution Loop: The client.run() function manages the multi-agent conversation. It takes an initial agent, user messages, and context as input, and returns a response with updated messages, context variables, and the last active agent.
- This structure allows for flexible, dynamic multi-agent interactions while maintaining a stateless architecture between calls.
o1-engineer [Link]
A CLI tool for streamlining workflows with AI-powered code generation and editing.
Llama-stack [Link]
Meta unveils open-source Llama Stack, standardizing AI building blocks across the entire development lifecycle.
Leaked meta prompt [Link]
Leaked OpenAI meta prompt: optimizing GPT instructions for better results.
Auto Jobs Applier - AIHawk [Link]
Job search assistant.
RAGBuilder [Link]
Toolkit used to create optimal production-ready RAG setup for your data automatically.
Prompt caching (beta) - Anthropic [Link]
Prompt caching optimizes API calls for faster LLM interactions. It is a new API feature that optimizes large language model interactions. It caches and reuses consistent parts of prompts, reducing processing time and costs for repetitive tasks.
This technique is particularly useful for scenarios involving large contexts, multiple examples, or long conversations. Prompt Caching works by checking if a prompt prefix is already cached from a recent query and using it if found, otherwise processing and caching the full prompt.
Lazy Predict [Link]
Works to rapidly test multiple ML models with minimal coding effort. This Python library streamlines model selection for classification and regression tasks.
News
The Nobel Prize in Physics 2024 to John J. Hopfield and Geoffrey E. Hinton, for foundational discoveries and inventions that enable machine learning with artificial neural networks [Link]
Zuckerberg imagines that people will want to use AR glasses like Orion for two primary purposes: communicating with each other through digital information overlaid on the real world — which he calls “holograms” — and interacting with AI.
― Meta’s big tease - The Verge [Link]
One downside of Apple’s Vision Pro or Meta’s Quest 3 is that you lost vision of other people and other people cannot see your eyes, making it usage situation limited to home where you don’t have interaction with other people. However, the future of devices that’s going to replace mobile phone or comparable to mobile phone, has to have some functionalities to support socialization and networking.
Llama 3.2: Revolutionizing edge AI and vision with open, customizable models - Meta Blog [Link]
Big Tech has cozied up to nuclear energy - The Verge [Link]
Microsoft, Amazon, and Google are investing in nuclear energy to power their data centers.
Why Taiwan and Its Tech Industry Are Facing an Energy Crisis - Yale Environment 360 [Link]
Google’s share of the U.S. search ad market is expected to drop below 50% next year for the first time in over a decade, according to the research firm eMarketer.
Amazon is expected to have 22.3% of the market this year, with 17.6% growth, compared with Google’s 50.5% share and its 7.6% growth.
― Google’s Grip on Search Slips as TikTok and AI Startup Mount Challenge - The Wall Street Journal [Link]
Uber and Lyft drivers use Teslas as makeshift robotaxis, raising safety concerns - Reuters [Link]
Real world example:
Shorenstein Properties, a real-estate investment company based in San Francisco, is in a pilot program that is designed to lead to the automated tagging of all of its files using a RAG-based AI system. The goal is to eliminate many of the drawbacks in a time-consuming manual system, in which people might make errors or simply skip the process altogether. The company plans to put the tagging system into production in the next few months.
Files can also be organized quickly into “knowledge bases” and interrogated with AI, according to Egnyte, a cloud-based platform that companies use to access, share and manage business content.
Shorenstein in the past few weeks has started a proof of concept project using Egnyte to extract data from prospectuses on properties for sale, documents that can often run 60 pages, and organize it into reports that could help the company make efficient business decisions and improve processes.
― Companies Look Past Chatbots for AI Payoff - Steven Rosenbush at The Wall Street Journal [Link]
Beginning Friday, users of Meta’s AI chatbot feature in the U.S. will have access to real-time news and information from Reuters when they ask questions about news or current events.
It’s the first news deal Meta has brokered in the AI era.
― Scoop: Meta strikes multi-year AI deal with Reuters - AXIOS [Link]
An AI companion for everyone - Microsoft Blog [Link]
Releasing Copilot Voice, Copilot Daily, Personalization in Copilot, Copilot Vision, Think Deeper.
Anaconda Brings Generative AI Models to Desktops with Launch of AI Navigator - Anaconda Press [Link]
Meet the new Notion AI - Notion [Link]
Notion AI heavily integrates AIintroducing file-handling capabilities, enabling developers to extract insights from PDFs and images.
Customer data search, unification and retrieval for LLMs - Tilores [Link]
Identity RAG from Tilores improves accuracy and relevance of enterprise LLMs.
New autonomous agents scale your team like never before - Microsoft [Link]
We’re also introducing a groundbreaking new capability in public beta: computer use. Available today on the API, developers can direct Claude to use computers the way people do—by looking at a screen, moving a cursor, clicking buttons, and typing text. Claude 3.5 Sonnet is the first frontier AI model to offer computer use in public beta.
Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku [Link]
Perplexity Now Offers Powerful AI Search Right On Your macOS Desktop [Link]
Pushing the frontiers of audio generation - Google DeepMind [Link]
Gemini API and Google AI Studio now offer Grounding with Google Search - Google for Developers [Link]
What’s new: 1) reduces hallucination rates by sourcing verified, real-time information, 2) provides citation-supported answers, improving transparency, 3) allows threshold-based activation to control costs.
Technical details: Google’s Dynamic Retrieval system evaluates each query for grounding suitability, assigning a prediction score between 0 and 1. Factual or time-sensitive queries score higher (e.g., 0.97), while creative prompts score lower (e.g., 0.13).
New in Maps: Inspiration curated with Gemini, enhanced navigation and more - Google [Link]