2026 January - What I Have Read
Substack
How popular is Donald Trump? - Nate Silver and Eli Mckown-Dawson [Link]
Trump is quite unpopular right now, with unusually high intense opposition. They emphasize modeling rigor — weighting, adjustments, methodology — to argue their number is more reliable than any single poll headline.
Cold Truths - Doomberg [Link]
Human survival, prosperity, and political power are fundamentally constrained by physics—specifically the ability to maintain thermal comfort. Any ideology or policy that ignores this reality will eventually fail.
The article attacks climate policies that prioritize emissions targets and moral narratives over reliable, always-on energy, especially when those policies are designed by people insulated from the consequences of energy scarcity.
11 Public Speaking Techniques from the World’s Greatest Speakers - Polina Pompliano [Link]
Blog and Articles
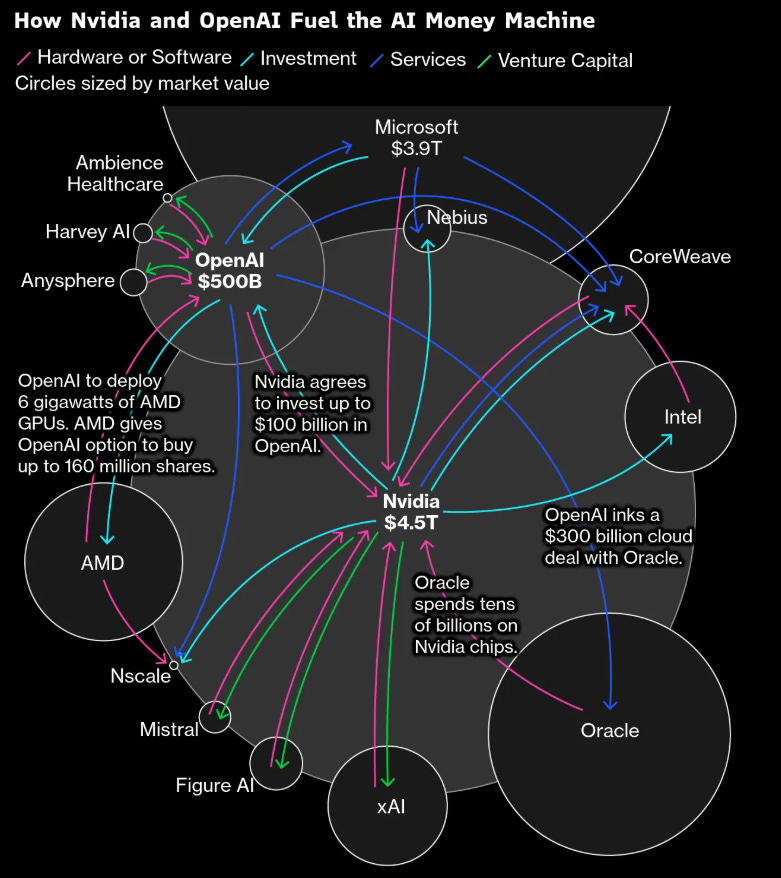
Exclusive: How China built its ‘Manhattan Project’ to rival the West in AI chips - Fanny Potkin, Reuters [Link]
In a secretive "Manhattan Project" led by Huawei, China built a prototype EUV machine by recruiting former ASML engineers, many of whom worked under aliases to maintain security. Although the prototype generates the necessary light, it has not yet produced working chips due to challenges in replicating high-precision optical systems. Operational production is now targeted for 2030, suggesting China is closing the technology gap faster than analysts anticipated.
AI agents are starting to eat SaaS - Martin Alderson [Link]
AI coding agents are fundamentally changing the build-vs-buy decision, making it increasingly viable for technically capable organizations to replace many SaaS products with internally built, agent-assisted tools—thereby threatening demand, renewals, and expansion economics for large parts of the SaaS industry.
The more I’ve done it, the more I realize that what most people think of as the hard parts of hiring—asking just the right question that catches the candidate off guard, defining the role correctly, assessing the person’s skills—are less important than a more basic task: how do you see someone, including yourself, clearly?
― What’s going on here, with this human? - Graham Dunca [Link]
The Three-Part Framework for Seeing People Clearly:
Seeing Your Reflection in the Window (Self-Awareness)
You can’t see others clearly unless you see your own biases, projections, and triggers.
Interviews are co-created interactions; your tone, assumptions, and values shape how the other person shows up.
Personality frameworks (Myers–Briggs, Big Five, self-monitoring, etc.) are most useful when applied to yourself first.
Use multiple frameworks to avoid becoming trapped by a single lens.
Key idea: Misjudgment often comes from mistaking your own internal reactions for objective insight.
Seeing the Elephants in the Room (Unconscious Drivers)
Borrowing from Jonathan Haidt: each person has a rider (conscious narrative) and an elephant (unconscious motivations). Interviews mostly capture the rider; references reveal the elephant.
Espoused beliefs ≠ actual behavior (“espoused theory” vs. “theory in use”).
High-quality reference checks are often 5–10x more valuable than interviews, especially from trusted, calibrated observers.
The best signal often comes from:
- The tone of a reference
- “Table-pounding” enthusiasm
- The dog that doesn’t bark (what’s conspicuously missing)
Key idea: Humility about your limited perception is a prerequisite for accuracy.
Seeing the Water (Context and Ecosystem)
There is no such thing as an “A player” in the abstract—performance is context-dependent.
People thrive or fail based on subtle environmental factors: culture, incentives, belief loops, and feedback structures.
Moving someone to a new ecosystem is risky; strengths in one context can become weaknesses in another.
Belief from leaders and teammates can create powerful positive feedback loops.
Hiring should focus on fit between person and environment, not just raw talent.
Key idea: To understand someone, you must understand the system they came from—and the one you’re putting them into.
Claude’s Constitution - Anthropic [Link]
This constitution is trying to define an AI that
Has internalized values, not just filters
Balances:
- User benefit
- Societal impact
- Company constraints
- Long-term safety
Operates more like a moral agent under supervision than a pure tool
Claude’s Constitution is not a dataset of examples. It’s a normative specification — a written set of values, priorities, and decision heuristics that Anthropic uses to shape Claude’s behavior. It’s one of the clearest examples of value-based alignment framing, rather than just policy enforcement.
OpenAI Starts Testing Ads in ChatGPT - The New York Times [Link]
From Words to Worlds: Spatial Intelligence is AI’s Next Frontier - Fei-Fei Li [Link]
Today’s models are powerful with words and patterns, but they don’t truly understand the 3D, physical, dynamic world the way humans do. To unlock robotics, scientific discovery, immersive creativity, and real-world interaction, AI needs world models — systems that can represent and reason about spaces, objects, physics, and change over time.
If you have multiple interests, do not waste the next 2-3 years - Dan Koe [Link]
In the AI era, the winners aren’t specialists — they’re people who turn their unique mix of interests into a public body of work and build systems around their own development.
Murders plummeted more than 20% in U.S. last year, the largest drop on record, study shows - CBS News [Link]
Exclusive: Musk's SpaceX in merger talks with xAI ahead of planned IPO, source says - Echo Wang and Joey Roulette, Reuters [Link]
The merger supports Musk’s vision of putting AI data centers in space, using solar power to cut energy costs for AI training and inference. It would tightly integrate:
- Rockets + satellite infrastructure (SpaceX/Starlink/Starshield)
- AI models + compute (xAI, Grok, Colossus supercomputer)
- Data + distribution (X platform)
YouTube and Podcast
Massive Somali Fraud in Minnesota with Nick Shirley, California Asset Seizure, $20B Groq-Nvidia Deal - All-In Podcast [Link]
I Investigated Minnesota’s Billion Dollar Fraud Scandal - Nick Shirley [Link]
The Minnesota Fraud Scandal | An Unfiltered Conversation with Nick Shirley - The Iced Coffee Hour [Link]
Iran's Breaking Point, Trump's Greenland Acquisition, and Solving Energy Costs - All-In Podcast [Link]
Apple's AI Crisis: Explained! - Marques Brownlee [Link]
Good points mentioned by Marques Brownlee:
The Velocity Trap: Polish vs. Pace
Apple’s traditional "slow and steady" approach—waiting for a category to mature before entering with a polished product—may be incompatible with AI. Unlike hardware, AI improves through real-world iteration and constant data loops. By prioritizing perfection and long release cycles, Apple risks falling behind competitors who are learning and evolving in real-time.
The Execution & Credibility Gap
While "Apple Intelligence" is conceptually sound (focusing on privacy and deep OS integration), there is a growing disconnect between marketing and reality. Much of Apple’s vision remains aspirational and unproven, leading to a "credibility gap." Relying on future-dated AI features to drive current hardware sales creates a significant trust risk if the eventual rollout doesn't meet the high bar set by the demos.
Cultural Rigidity in a Fluid Market
The AI shift is as much a cultural test as a technical one. Apple’s core pillars—secrecy, privacy-first design, and walled-garden ecosystems—are now friction points in an industry that rewards open iteration and speed. While Apple still possesses massive advantages in silicon and distribution, its margin for error is slimmer than ever because AI is a foundational platform shift, not just a new feature set.
The New Siri is... Google (Explained) - Marques Brownlee [Link]
This is Apple choosing not to lose users while it catches up.
All-In's 2026 Predictions - All-In's 2026 Predictions [Link]
Ben Horowitz on Investing in AI: AI Bubbles, Economic Impact, and VC Acceleration - a16z [Link]
Ben & Marc: Why Everything Is About to Get 10x Bigger - a16z [Link]
Everything Is Becoming Supply-Driven (and That Breaks Old Intuitions)
Historically, markets were demand-constrained; now they are increasingly supply-unconstrained due to software, AI, and cloud. This is why traditional TAM / market sizing frameworks are fundamentally broken. If you remove constraints, human demand is far larger than economists ever modeled.
AI Is a General-Purpose Force Multiplier
AI is not “one more sector” — it’s a universal problem solver. This creates second-order effects across every industry, not just tech. Companies that treat AI as a feature will lose to those that treat it as infrastructure.
Cloud + Software Create 10× Outcomes
Databricks is a canonical example: when compute, storage, and tooling scale together, you get nonlinear gains. Once platforms reach sufficient abstraction, entire new categories appear that were impossible before. Step-change technologies don’t improve things linearly — they rewrite what’s possible.
Intangibles Are the New Moat
Brand, reputation, trust, and narrative now matter more than physical assets. In a world of infinite supply, attention and belief become the scarce resources.
Original Thinkers with Conviction Win
The future belongs to people who combine: original ideas, moral clarity, willingness to take public criticism (“take arrows”). Consensus thinking is structurally disadvantaged in exponential eras.
Media Has Shifted from Gatekeepers to Creators
When creators own distribution, creativity explodes.
Reputation Is a First-Class Economic Asset
In decentralized systems, there is no central arbiter of quality. Reputation becomes: The hiring signal, The funding signal, The distribution advantage.
Great Companies Are Built by Dreamers, Not Committees
a16z tries to invert this by protecting founders’ psychological safety and ambition. The job is to scale belief without killing the dream.
Founders Need Confidence, Not Just Intelligence
Turning inventors into CEOs requires emotional reinforcement, not just advice.
Autonomy Beats Control
a16z is structured as semi-autonomous teams rather than a centralized hierarchy. This mirrors how startups scale effectively: high trust, high accountability, low friction.
Adam Carolla on California’s Collapse: Fires, Failed Leadership, and Gyno-Fascism - All-In Podcast [Link]
Supercharging a New FDA: Marty Makary on Science, Power & Patients - All-In Podcast [Link]
Marc Andreessen's 2026 Outlook: AI Timelines, US vs. China, and The Price of AI - a16z [Link]
Key takeaways:
AI is the biggest tech shift is bigger than PCs, the internet, or mobile. Despite the hype, most industries have not reorganized around AI yet. Current adoption is surface-level (tools, copilots), not structural (AI-native workflows).
The cost of intelligence is collapsing. AI is fundamentally different because intelligence becomes cheap and abundant. As costs fall, usage explodes — even if revenue models lag. This creates temporary distortions: high burn, unclear margins, massive upside. Falling intelligence costs will unlock entirely new markets, not just improve existing ones.
Many AI companies look “unprofitable” by traditional standards. What matters is whether cost curves bend faster than price curves. Infrastructure advantages (GPUs, clusters) are real but short-lived. You back companies where learning speed beats depreciation speed.
Pricing will shift from SaaS to usage- and value-based. Flat SaaS pricing breaks when marginal intelligence cost trends toward zero. AI pricing will resemble: 1) cloud compute; 2) utilities; 3) consumption-based services. Value-based pricing becomes feasible because AI output is measurable.
Open vs. closed is not a winner-take-all debate. Multiple contradictory strategies can succeed simultaneously.
Closed models: 1) better control, 2) clearer monetization, 3) tighter safety
Open models: 1) faster diffusion, 2) ecosystem leverage, 3) geopolitical resilience
Incumbents and startups have different, real advantages. Outcomes depend on how deeply AI rewrites the workflow.
Most disruption happens at the task level, not the job title. Productivity gains are uneven and socially destabilizing. Adoption depends more on human systems than model capability. Technology moves faster than institutions.
Venture strategy must embrace contradictions. a16z deliberately backs:
open and closed
big models and small models
infrastructure and applications
Because uncertainty is structural, not temporary.
Philosophy: If you think the future is clean and singular, you’re wrong.
Why AI will dwarf every tech revolution before it: robots, manufacturing, AR glasses from CES 2026 - All-In Podcast [Link]
The core argument is that AI is not just another productivity wave (like cloud, mobile, or the internet), but a general-purpose intelligence layer that will reshape every industry simultaneously—especially healthcare, education, labor markets, and capital allocation. The discussion emphasizes speed, organizational mismatch, and institutional lag as the real constraints—not technology itself.
Satya Nadella on AI’s Business Revolution: What Happens to SaaS, OpenAI, and Microsoft? - All-In Podcast [Link]
Takeways:
Satya frames AI not as “chatbots” but as a progression of work interfaces. The real value isn’t “fun AI,” it’s AI that completes multi-step business tasks inside workflows. Microsoft is focused on closing the gap between 'cool demo' and 'actual business process transformation'.
He subtly pushes back on the “AI replaces workers” narrative. His framing is that AI is productivity density, not just removal, meaning more output per employee, faster cycle times, and more ambitious projects.
He sees the future as not just one assistant, but many domain-specific agents. These agents will use enterprise data, work across tools (M365, Dynamics, GitHub, etc.), and handle business processes, not just prompts.
Microsoft’s edge is NOT owning the best foundation model. It’s:
- Distribution (Windows, Office, Azure)
- Enterprise trust
- Identity, security, compliance
- Data layer
- Developer ecosystem
AI is a full tech stack competition. He frames AI competition as not model vs model, but national + ecosystem tech stacks.
Winning stack = Compute + Models + Apps + Distribution + Developers + Data
He doesn’t say SaaS dies. SaaS UI becomes agent-accessible capability surfaces. Therefore, the UI is less important, APIs, workflows, and data models become key, and software becomes “actionable services for agents”.
Can You Teach Claude to be ‘Good’? | Meet Anthropic Philosopher Amanda Askell - Hard Fork [Link]
Takeaways:
The shift to ads in ChatGPT isn’t just a product tweak — it’s an alignment change. Alignment isn’t only technical — economics is an alignment mechanism.
Systems optimized for revenue gradually stop optimizing for user well-being.
OpenAI, Google, Anthropic may produce different kinds of AI not just because of tech — but because of revenue structure.
- Ad-driven systems → more incentive tension
- Enterprise/subscription focus → more incentive toward reliability & safety
This frames business strategy as a hidden driver of model personality.
Anthropic is trying to make values explicit. Claude is trained using Constitutional AI — a written set of principles the model uses to critique and guide itself.
You can’t separate intelligence from values. Smarter systems may reinterpret rules in ways designers didn’t expect.
Dr. Mehmet Oz on Fixing American Healthcare + Fraud | Live from Davos - All-In Podcast [Link]
Takeaways:
U.S. healthcare isn’t failing because of lack of talent or technology — it’s failing because:
Incentives reward procedures, billing complexity, and intermediaries
Prevention and long-term outcomes are underpaid
Bureaucratic and payment layers distort decisions
Fraud is not marginal — it’s structural and industrial-scale. Includes phantom billing, fake clinics, and organized rings. Fraud inflates prices and drains resources from real care
The bottleneck in healthcare isn’t knowledge — it’s access + navigation.
AI will: Do triage; Guide patients before they see doctors; Standardize care quality; Reduce unnecessary specialist visits. The big shift will be from doctor-centered care to data/AI-guided care. Doctors become escalation points, not the front door.
Healthcare reflects upstream social failures. Healthcare costs are downstream of: Addiction; Mental health breakdowns; Social instability; Border and population pressures.
Elon Musk on AGI Timeline, US vs China, Job Markets, Clean Energy & Humanoid Robots | 220 - Peter H. Diamandis [Link]
Takeaways:
- Musk’s stance is that transformative AI is very close. Superhuman AI as an engineering inevitability. Timeline measured in years, not decades. The key limiter now being infrastructure (chips, power) more than theory.
- AI risk is structural, not Hollywood. He’s not focused on evil robots; he worries about: Systems optimizing for goals misaligned with human intent; Intelligence that becomes strategically beyond human control; Power concentration in a few actors. The danger comes from competence without alignment, not malice.
- He frames AI as a civilization-level strategic asset. The US–China competition is inevitable. Export controls slow but don’t stop capability. Whoever leads in AI shapes military, economic, and political leverage. AI dominance may matter more than nuclear or industrial dominance did.
- Intelligence scaling = energy scaling. AI data centers are seen as industrial-scale electricity consumers, dependent on massive grid expansion, tightly linked to storage + renewables.
- Physical AI (robots) will outscale digital AI in impact. He sees humanoid robots (Optimus) as the path to automating real-world labor, more economically transformative than software alone, and potentially more numerous than humans. The biggest value creation isn’t chatbots — it’s AI in bodies.
- He argues AI + robotics will outperform humans at most jobs, collapse the economic necessity of labor, and shift society toward abundance of goods/services. The core future problem isn’t unemployment — it’s purpose and meaning in a post-labor world.
- Concentrated superintelligence is more dangerous than distributed superintelligence.
- We’re in a civilization transition, not a tech cycle. This is a species-level turning point, not a market trend.
The Singularity Countdown: AGI by 2029, Humans Merge with AI, Intelligence 1000x | Ray Kurzweil - Peter H. Diamandis [Link]
Ray's worldview is very consistent across decades:
- Progress is exponential, not linear. Technology improves in doubling patterns (compute, data, biotech, etc.). Humans think linearly - we massively underestimate what happens in the second half of an exponential curve.
- AI will reach human-level general intelligence soon - around 2029. Not just narrow tools — systems that reason, learn, and adapt across domains. After that, progress speeds up because AI designs better AI. This is the start of the steep part of the curve.
- The Singularity happens when non-biological intelligence becomes vastly more powerful than all human brains combined. Intelligence growth becomes runaway and civilization transforms at a speed we can’t intuitively grasp. It’s an evolutionary phase shift, not just a tech upgrade.
- He strongly rejects the “AI replaces humans” framing. We expand our intelligence by plugging into non-biological systems. Future humans will merge with AI (biological + digital hybrid minds)
- AI + biotech enables rapid advances in diagnostics, drug discovery, and gene editing. The goal of longevity escape velocity (medical progress adds more life than time passing) will be reached. Radical life extension is plausible this century.
- Work doesn't disappear - it evolves. Automation removes tasks, not human meaning. New categories of work emerge that we can’t predict today. As abundance rises, humans focus more on creativity, relationships, exploration, and purpose-driven work.
- Every major technology starts centralized, then becomes widely accessible. Risks are real, but benefits historically outweigh harms. The solution to tech risk is better tech + human values, not stopping progress.
- Consciousness can extend beyond biology. Mind is patterns and processes. If reproduced in another substrate, consciousness can continue or expand. Digital minds could be as rich (or richer) than biological ones.
Chamath & Nathalie on Leaving California, Tech Investments & Their Marriage | KMP Ep.24 - All-In Podcast [Link]
ICE Chaos in Minneapolis, Clawdbot Takeover, Why the Dollar is Dropping - All-In Podcast [Link]
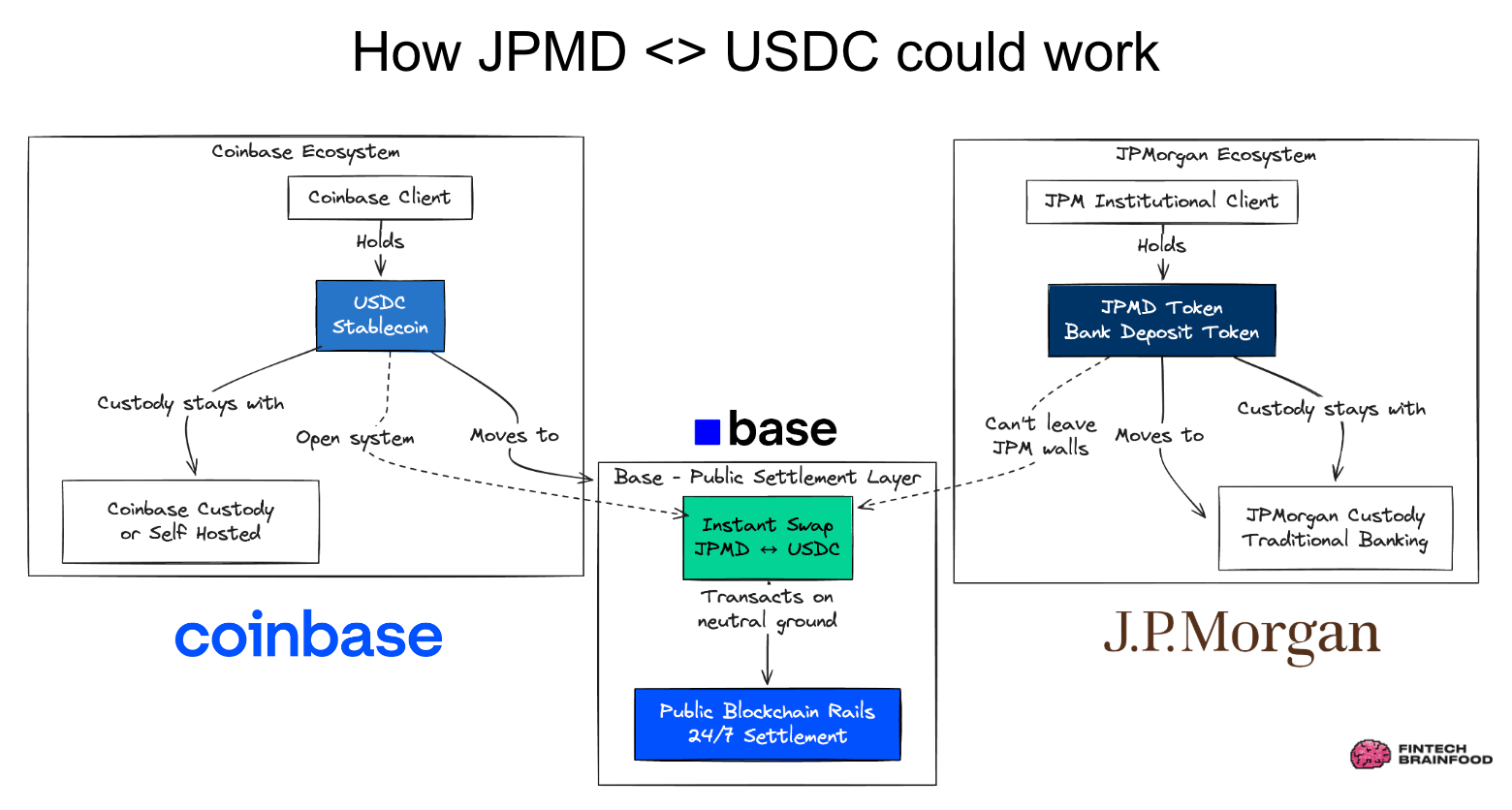
Coinbase CEO's Top 3 Crypto Trends for 2026 + More from Davos! - All-In Podcast [Link]
Takeaways:
- Brian Armstrong (Coinbase)
- Exchanges become universal financial marketplaces. Crypto exchanges stop being “places to trade coins” and become places to trade everything — using blockchain as the behind-the-scenes system. This means everything becomes a digital token on a blockchain, which includes stocks, bonds, funds, real estate, etc, - they are all represented the same way: digital assets on-chain.
- Stablecoins are the new payments layer. They are moving into cross-border payments, business settlement, and everyday financial flows. They are positioned as faster, cheaper, programmable internet-native money. This is crypto’s move from speculation to real economic utility.
- Crypto and AI will merge. AI agent will need wallets, identity, ability to transact. Crypto provides economic infrastructure for autonomous AI systems. AI will be able to earn, pay, and contract on its own.
- Andrew Feldman (Cerebras)
- AI progress is compute-constrained. The bottleneck is no longer just algorithms; it's chips, power, data centers. Whoevere scales compute fastest drives AI capability.
- Massive hardware innovation is required. The frontier isn’t just better models — it’s better physical AI infrastructure.
- Compute is now geopolitics. AI compute capacity is strategically important, nationally competitive and comparable to energy or oil infrastructure. The AI race is an infrastructure race, not just software.
- Jake Loosararian (Gecko Robotics)
- AI is leaving the screen and entering industry. AI + robotics are being deployed in power plants, industrial facilities, and critical infrastructure. This is aAI moving from chat & code to machines & steel.
- Real world data beats theoretical models. AI becomes powerful when grounded in actual industrial reality, not just simulations.
- AI and robotics improve maintenance, safety, and efficiency. This drives huge economic leverage because it upgrades the systems that power society.
Amazon Layoffs & Shutdown of Fresh and Go Stores, The Anthropic Cowork Threat | Jan 28, 2026 - The Information [Link]